论文导读- Cluster-driven Graph Federated Learning over Multiple Domains(聚类驱动的图联邦学习)
Posted 1 + 1=王
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文导读- Cluster-driven Graph Federated Learning over Multiple Domains(聚类驱动的图联邦学习)相关的知识,希望对你有一定的参考价值。
文章目录
论文信息
Cluster-driven Graph Federated Learning over Multiple Domains

原文链接:Cluster-driven Graph Federated Learning over Multiple Domains:https://openaccess.thecvf.com/content/CVPR2021W/LLID/papers/Caldarola_Cluster-Driven_Graph_Federated_Learning_Over_Multiple_Domains_CVPRW_2021_paper.pdf
摘要
Federated Learning (FL) deals with learning a central model (i.e. the server) in privacy-constrained scenarios, where data are stored on multiple devices (i.e. the clients). The central model has no direct access to the data, but only to the updates of the parameters computed locally by each client. This raises a problem, known as statistical heterogeneity, because the clients may have different data distributions (i.e. domains). This is only partly alleviated by clustering the clients. Clustering may reduce heterogeneity by identifying the domains, but it deprives each cluster model of the data and supervision of others. Here we propose a novel Cluster-driven Graph Federated Learning (FedCG). In FedCG, clustering serves to address statistical heterogeneity, while Graph Convolutional Networks (GCNs) enable sharing knowledge across them. FedCG: i) identifies the domains via an FL-compliant clustering and instantiates domain-specific modules (residual branches) for each domain; ii) connects the domain-specific modules through a GCN at training to learn the interactions among domains and share knowledge; and iii) learns to cluster unsupervised via teacher-student classifier-training iterations and to address novel unseen test domains via their domain soft-assignment scores. Thanks to the unique interplay of GCN over clusters, FedCG achieves the state-of-the-art on multiple FL benchmarks.
联邦学习( Federation Learning,FL )是在隐私受限的场景中学习一个中心模型(即服务器),其中数据存储在多个设备(即客户)上。中心模型不直接获取数据,只对每个客户端本地计算的参数进行更新。这就产生了一个问题,称为统计异质,因为客户可能具有不同的数据分布(即域)。聚类可以通过识别领域来降低异构性,但是它剥夺了每个集群模型的数据和其他人的监督。
本文提出了一种新的聚类驱动的图联合学习( Fed CG )。在FedCG中,聚类服务于解决统计异构性,而图卷积网络( Graph Convolutional Networks,GCNs )则实现了跨网络的知识共享。
FedCG:i )通过符合FL的聚类来识别域,并为每个域实例化域特定的模块(残差分支);ii) 在训练中通过GCN连接特定于域的模块,以学习域之间的交互并共享知识;iii ) 学习通过teacher-student 分类器-训练迭代进行无监督聚类,并通过其域软分配分数来处理新的看不见的测试域。
得益于GCN在聚类上的独特交互,FedCG在多个FL基准上达到了最先进的水平。
主要贡献
- 提出了第一个基于聚类驱动的GCN方法来解决FL场景中的统计异质性问题。得益于通过GCN学习到的域之间的交互,知识根据基于相似性的准则在域之间共享,降低了过拟合的风险,并帮助填充较少的域。
- 引入了一个为联邦学习场景设计的迭代师生聚类算法,它允许通过软分配适应新的领域。这样可以在不违反FL约束的情况下捕获不同的域分布。每个领域分配模型特定的组件,通过GCN交互进行训练。
- 我们在多个FL基准上评估了我们的模型,在这些基准上,我们与最先进的模型进行了比较。
聚类驱动的图联邦学习
问题定义
我们的目标是学习一个函数f θ:X —> Y,以θ为参数,将输入空间X中的样本映射到输出空间Y中对应的语义。具体来说,我们关注一个分类任务,其中X包含图像,而Y是定义在一组标签上的概率。
在FL设置中,服务器没有直接访问数据的权限,但是可以与一组客户端C进行通信,其中每个客户端c∈C访问一个本地数据集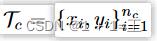 ,其中x∈X,y∈Y。
,其中x∈X,y∈Y。
在此情景下,可以通过查询客户端并依靠其本地更新的参数θ来学习f θ。特别地,由于| C |很大,我们可以假设在通信轮中执行同步更新方案,其中在每一轮中,一组K客户端接收f θ,其中| K |远小于| C |。每个客户端通过最小化给定的目标函数,用其本地数据集计算θ的局部更新,即θ k。由于我们考虑分类任务,我们通过最小化标准交叉熵损失来更新θ k:
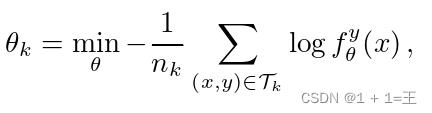
其中, 表示由f θ给出的x属于该类的概率。
表示由f θ给出的x属于该类的概率。
通过上式,我们得到每个客户端对应的局部参数θ k,以解决该客户端上数据集的分类问题。在每一轮,服务器收集所有的局部更新,并将它们组合起来更新中心模型参数θ。一个简单而有效的聚合本地更新的策略是FedAvg ,它计算θ作为每个θ k的加权平均值:
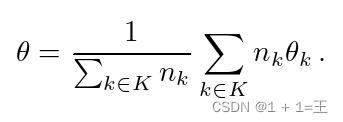
异质性可能是FedAvg的一个问题,一般而言,对于FL策略,由于在非独立同分布和不平衡数据中缺乏收敛性保证。在实际应用中,每个客户端在X和Y上的联合概率分布通常是不同的,即给定两个客户端c和k,且c != k,则有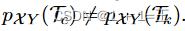
为了解决这个问题,我们提出了一种方法,
(1) 通过聚类识别不同客户端中存在的分布(即域);
(2) 实例化特定领域的组件,使模型适应每个领域;
(3) 通过一个GCN使各个特定领域的模块进行交互,更新其中一个模块可以使其他模块受益。
下面分别对这些要素进行描述。
联邦聚类
为了通过领域特定的模块来解决统计异质性,我们需要识别数据中存在的不同领域。这是很有挑战性的,因为数据是跨多个客户端的,并且服务器不能直接对它们进行聚类。而且,这些聚类即使对于训练集正确识别,对于测试集也可能不是最优的。在这里,我们通过一个基于两个领域分类器的聚类过程来解决第一个问题,一个是教师的角色,另一个是学生的角色,它迭代地对图像进行分组,使其分组更容易分类。
形式上,假设我们的数据包含D个域,其中D是一个超参数。我们初始化两个域分类器(教师和学生),每个域分类器都是一个函数,将图像映射到定义在D域上的概率向量D,即X —> D。给定一个输入图像,教师提供域伪标注作为目标来改进学生的预测。特别地,我们通过迭代最小化客户端数据集上教师和学生域预测之间的交叉熵损失来学习客户端学生参数ϕ k。因此,对于一个客户端,学生的参数ϕ k为:
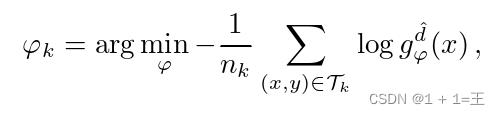
其中,d’ 是教师给出的关于x的伪标号,即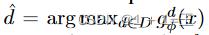 ,并且
,并且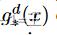 表示x属于g *给出的第d个域的概率。奖励学生能够根据伪标签进行分类,并隐式鼓励在伪标注上达成一致,从而在聚类上最容易达成一致。然后用标准的FedAvg更新每轮后的域分类器参数ϕ,即:
表示x属于g *给出的第d个域的概率。奖励学生能够根据伪标签进行分类,并隐式鼓励在伪标注上达成一致,从而在聚类上最容易达成一致。然后用标准的FedAvg更新每轮后的域分类器参数ϕ,即: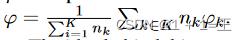
聚类模型
由于我们的模型可以通过前面描述的过程来识别数据簇,因此我们可以设计一种方法将函数f θ特殊化到每个域。为了简单起见,我们考虑将参数θ分成两个集合,即θ = θa,θs ,其中θa为领域无关参数,θ s为领域相关参数。注意到,θ s实际上满足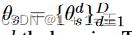 其中θds是特定于第d域的参数。为了将模型裁剪到特定的领域,我们可以考虑多种方式来包含θ s。假设f θ是一个具有一组层L的深度置信网络,表示在层ℓL上应用的函数fℓθ。给定一个域的输入和上一层提取的特征zℓ,第ℓ层的输出为:
其中θds是特定于第d域的参数。为了将模型裁剪到特定的领域,我们可以考虑多种方式来包含θ s。假设f θ是一个具有一组层L的深度置信网络,表示在层ℓL上应用的函数fℓθ。给定一个域的输入和上一层提取的特征zℓ,第ℓ层的输出为:
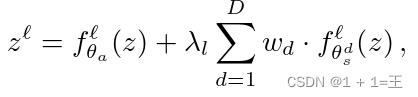
其中,λ l为平衡域特定成分影响的可学习参数,wd为域d的权重。
在训练过程中,我们假设数据属于单个簇,由教师的伪标注给出,如果d = d’,则wd为1,否则为0。在测试时,我们希望我们的模型通过简单地合并已看到的残差来处理来自任意域的数据。因此,我们设置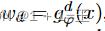 ,通过学生输出概率来加权每个领域特定组件的影响。
,通过学生输出概率来加权每个领域特定组件的影响。
由于我们是在一个联邦场景中,也必须在没有访问本地数据的情况下和每一轮之后更新特定于中心域的参数。在实际应用中,我们遵循FedAvg,并且我们在每个训练回合中对域无关参数和域特定参数执行联邦平均。
聚类模型的联系
我们现在有了一个模型,可以适应每个领域的特殊性。在这里通过使特定领域的参数相互作用来进一步完善。具体来说,我们通过图Gℓ= ( Vℓ, Eℓ)对每一层ℓ的领域特定参数的交互进行建模,其中Vℓ是ℓ层所有领域特定参数的集合,eijEℓ是连接两个可能交互的领域节点i和j的边。也就是说,如果一个域分配的样本很少,那么它的参数将很少更新,因此不足以捕获域的特殊性,并推广到同一域的看不见的样本。
我们提出使用GCN来建模领域特定参数的相互作用。在第ℓ层所有的特定领域参数表示为: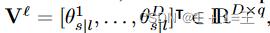 ,
,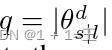 。其中q表示为每一个域参数的数量,并基于 GCN 进行参数的更新:
。其中q表示为每一个域参数的数量,并基于 GCN 进行参数的更新:
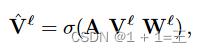
为了简单起见,在 GCN 过程中不涉及特征维度的变换,并且 GCN 的权重矩阵也应用 FedAvg 进行参数更新。
对于每条边,邻接矩阵中的值表示两个域是多么接近;由于我们对图的结构没有任何先验知识,因此我们将Gℓ建模为一个全加权图。在不直接访问数据服务器端的情况下,我们直接在(特定于域的)参数空间中计算两个域之间的距离。在实践中,将域i, j 之间的相似性定义为:
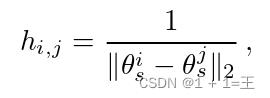
基于此,邻接矩阵的构建方式如下:
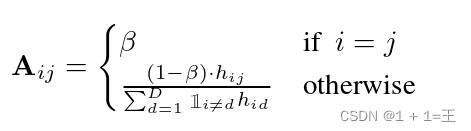
其中,β是衡量自连接影响的超参数,我们将其设置为0.5,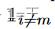 是一个指示函数,当i = m时为1,否则为0。
是一个指示函数,当i = m时为1,否则为0。
在我们的公式中,每个客户端不仅收到参数θ的集合,还收到邻接矩阵。有了这个定义,我们就迫使特定领域组件的梯度通过GCN流向所有其他组件。因此,一个领域特定组件的更新将影响所有领域特定的参数,即使是当前训练轮中不存在的领域的参数。此外,给定两个域i,j且i != j,每一层中j对i的影响与邻接矩阵值Aij成正比。这意味着两组特定于域的参数越接近,它们的相互影响就越大。最后,虽然GCN是在训练过程中确保信息跨域流动的一种方法,但在推理时,我们可以为每一层预先计算V (ℓ),以节省内存使用。
FedCG框架
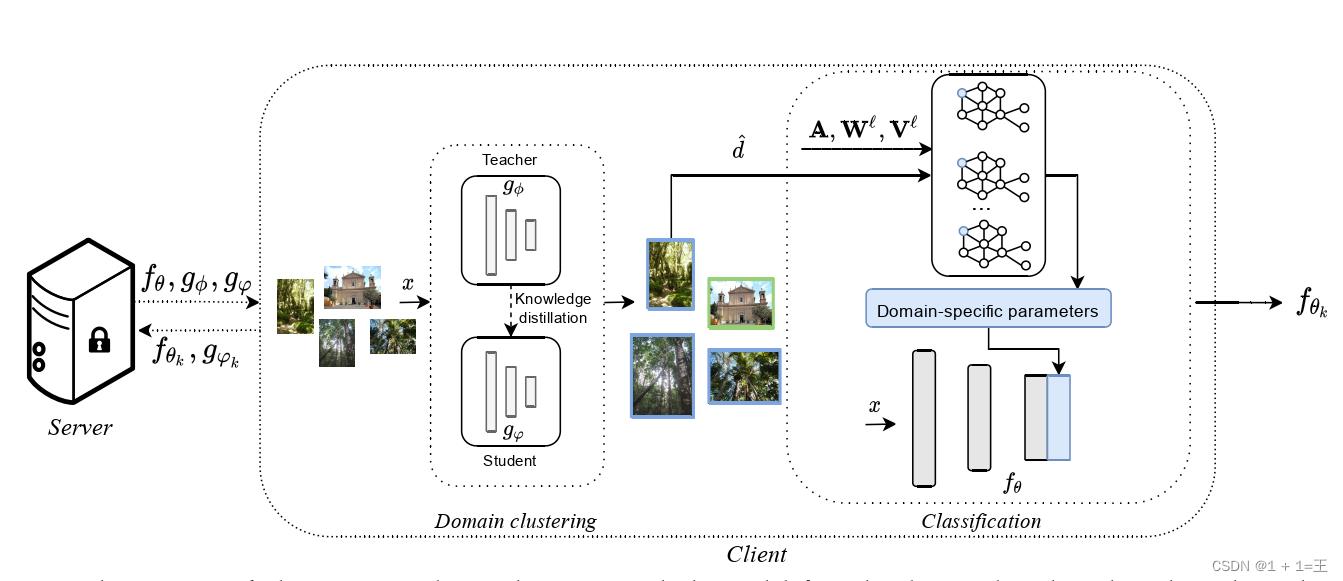
服务器将模型f θ与教师g φ和学生g ϕ域分类器一起发送给为联邦轮选择的客户端。在客户端,域分类器对本地数据x进行聚类,生成每个图像的归属域( d )。在训练时,通过g φ预测硬标签d’,并将其作为输入,通过基于知识蒸馏的过程训练g ϕ。在测试时刻,d’ 由g ϕ给出,是已发现域的加权组合。在Fed CG中,网络f θ由领域无关部分(灰色)和残差领域相关部分(蓝色)组成。特定于域的参数由GCN产生,作为输入A、Wℓ、Vℓ和d’接收。在对其数据进行f θ和g ϕ训练后,客户端k将更新后的权值θ k和ϕk发回服务器。在服务器端,通过FedAvg算法对更新进行聚合。
以上是关于论文导读- Cluster-driven Graph Federated Learning over Multiple Domains(聚类驱动的图联邦学习)的主要内容,如果未能解决你的问题,请参考以下文章