组成原理-处理器流水线技术
Posted Mount256
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了组成原理-处理器流水线技术相关的知识,希望对你有一定的参考价值。
文章目录
0 流水线性能指标
流水线的表示方式:
- 指令流程图(指令执行过程图):横轴为时间,纵轴为指令
- 时空图:横轴为时间,纵轴为流水线段
0.1 指令执行时间
假设为 n 段流水线(处理机的度为 1),每段流水线时间为 t,一共有 k 条指令。
- k 条指令执行时间:
T = 第一条指令执行时间 + 其余 k-1 条指令执行时间 = n * t + (k - 1) * t = (n + k - 1) * t
假设为 n 段流水线(处理机的度为 m),每段流水线时间为 t,一共有 k 条指令。
- k 条指令执行时间:
T = 第一条指令执行时间 + 其余 k-1 条指令执行时间 = n * t + (k/m - 1) * t = (n + k/m - 1) * t
0.2 流水线的吞吐率
假设为 n 段流水线,每段流水线时间为 t,一共有 k 条指令。
- k 条指令的吞吐率:
TP = n / T = n / [(n + k - 1) * t] - 当
k → ∞时,得最大吞吐率:TPmax = 1 / t
0.3 流水线的加速比
假设为 n 段流水线,每段流水线时间为 t,一共有 k 条指令。
- 不用流水线时,k 条指令执行时间:
T0 = n * t * k - k 条指令的加速比:
S = T0 / T = [n * t * k] / [(n + k - 1) * t] - 当
k → ∞时,得最大加速比:Smax = n
0.4 流水线的效率
假设为 n 段流水线,每段流水线时间为 t,一共有 k 条指令。
则在时空图上,流水线的效率定义为完成 k 条指令占用的时空区有效面积与 k 条指令所用的时间与 n 个流水段所围成的时空区总面积之比。
- 不用流水线时,k 条指令执行时间:
T0 = n * t * k - 完成 k 条指令占用的时空区有效面积:
T0 = n * t * k - k 条指令所用的时间与 n 个流水段所围成的时空区总面积:
n * T = (n + k - 1) * t * n - 流水线的效率:
E = T0 / (n * T) = [n * t * k] / [(n + k - 1) * t * n]
1 基本流水线技术
1.0 流水线设计基本原则
流水线设计原则:流水段的长度以花费时间最长的阶段为准。
【例】若某计算机最复杂指令的执行需要完成 5 个子功能,分别由功能部件 A~E 实现,各功能部件所需时间分别为 80ps、50ps、50ps、70ps 和 50ps,采用流水线方式执行指令,流水段寄存器延时为 20ps,则 CPU 时钟周期至少为?
【解】指令流水线的每个流水段时间单位为时钟周期,题中指令流水线的指令需要用到 A~E 五个部件,所以每个流水段时间应取最大部件时间 80ps,此外还有寄存器延时 20ps,则 CPU 时钟周期至少是 100ps。
1.1 五段流水线
五段流水线的一般过程:
- 取指(IF):根据 PC 从指令 Cache 取指令至 IF 段的锁存器
- 译码/读寄存器(ID):对指令进行译码,并用 IR 中的寄存器地址去访问通用寄存器组,读出所需的操作数
- 执行/计算地址(EX):不同指令所进行的操作不同
- 访存(MEM):该周期处理的指令只有 LOAD、STORE 和条件分支指令,其它类型的指令在此周期不做任何操作
- 写回(WB):ALU 运算指令和 LOAD 指令在这个周期把结果数据写入通用寄存器组
下面来分析不同指令的执行过程。
1.1.1 运算类指令的执行过程(背!)
举例:ADD #996, Rd,功能:996+(Rd)–>Rd
- 取指(IF):根据 PC 从指令 Cache 取指令至 IF 段的锁存器
- 译码/读寄存器(ID):取出操作数至 ID 段锁存器
- 执行/计算地址(EX):运算,将结果存入 EX 段锁存器
- 访存(MEM):空段
- 写回(WB):将运算结果写回指定寄存器
1.1.2 LOAD 指令的执行过程(背!)
举例:LOAD Rd, 996(Rs),功能:(996+(Rs))–>Rd
- 取指(IF):根据 PC 从指令 Cache 取指令至 IF 段的锁存器
- 译码/读寄存器(ID):将基址寄存器的值放到锁存器 A,将偏移量的值放到锁存器 Imm
- 执行/计算地址(EX):运算,得到有效地址
- 访存(MEM):从数据 Cache 中取数并放入锁存器
- 写回(WB):将取出的数写回寄存器
1.1.3 STORE 指令的执行过程(背!)
举例:STORE Rs, 996(Rd),功能:Rs–>(996+(Rd))
- 取指(IF):根据 PC 从指令 Cache 取指令至 IF 段的锁存器
- 译码/读寄存器(ID):将基址寄存器的值放到锁存器 A,将偏移量的值放到锁存器 Imm,将要存的数放到锁存器 B
- 执行/计算地址(EX):运算,得到有效地址,并将锁存器 B 的内容放到锁存器 Store
- 访存(MEM):写入数据 Cache
- 写回(WB):空段
1.1.4 条件转移指令的执行过程
举例:beq Rs, Rt, #偏移量,功能:若(Rs)==(Rt),则(PC)+指令字长+(偏移量×指令字长)–>PC;否则(PC)+指令字长–>PC
- 取指(IF):根据 PC 从指令 Cache 取指令至 IF 段的锁存器
- 译码/读寄存器(ID):偏移量放入锁存器 Imm
- 执行/计算地址(EX):运算,比较两个数
- 访存(MEM):将目标 PC 值写回 PC
- 写回(WB):空段
1.1.5 无条件转移指令的执行过程
举例:jmp #偏移量,功能:(PC)+指令字长+(偏移量×指令字长)–>PC
- 取指(IF):根据 PC 从指令 Cache 取指令至 IF 段的锁存器
- 译码/读寄存器(ID):偏移量放入锁存器 Imm
- 执行/计算地址(EX):将目标 PC 值写回 PC
- 访存(MEM):空段
- 写回(WB):空段
1.2 流水线的冒险
1.2.1 数据冒险(数据冲突)
- 概念:数据相关指在一个程序中,存在必须等前一条指令执行完才能执行后一条指令的情况,则这两条指令即为数据相关。
- 解决办法:
- 数据旁路技术(转发机制):不等前一条指令把计算结果写回寄存器组,下一条指令不再读寄存器组,而是直接把前一条指令的计算结果作为自己的输入数据开始计算过程
- 暂停流水线:把遇到数据相关的指令及其后续指令都暂停一至几个时钟周期,直到数据相关问题消失后再继续执行。可分为硬件阻塞(stall)和软件插入“NOP”两种方法
- 编译优化:通过编译器调整指令顺序来解决数据相关
数据冒险的分类:
- 写后读(RAW)相关:按序发射,按序完成时,只可能出现 RAW 相关
// R5 发生冲突
I1:ADD R5,R2,R4 (R2)+(R4) -> R5 // 往 R5 写入
I2:ADD R4,R5,R3 (R5)+(R3) -> R4 // 从 R5 读出
- 读后写(WAR)相关:乱序发射,编写程序的时候希望 I1 在 I2 前完成,但优化手段导致 I2 在 I1 前发射
// 编译优化后,导致 I2 先执行,I1 后执行,R2 发生冲突
// 或 I2 可能比 I1 先完成,导致 M 存储的是 (R4)+(R5) 的结果,而不是原本 R2 的值
I1: STA M,R2 (R2) -> M, M 为主存单元
I2: ADD R2,R4,R5 (R4)+(R5) -> R2
- 写后写(WAW)相关:存在多个功能部件时,后一条指令可能比前一条指令先完成
// I2 可能比 I1 先完成,导致 R3 最后存储的是 (R2)*(R1) 的结果,而不是 (R4)-(R5) 的结果
I1: MUL R3,R2,R1 (R2)*(R1) -> R3
I2: SUB R3,R4,R5 (R4)-(R5) -> R3
相关例题:
【例 1】五段流水线:
I1:add R1, R2, R3 (R2)+(R3) -> R1
I2:add R5, R2, R4 (R2)+(R4) -> R5
I3:add R4, R5, R3 (R5)+(R3) -> R4
I4:add R5, R2, R6 (R2)+(R6) -> R5
指令流程图:
| 指令/时钟 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| I1 | IF | ID | EX | M | WB | ||||||
| I2 | IF | ID | EX | M | WB | ||||||
| I3 | IF | ID | EX | M | WB | ||||||
| I4 | IF | ID | EX | M | WB |
【注】若前一条指令的 ID 段被阻塞,则后一条指令的 IF 段也被阻塞。因为此时 IF 段锁存器还保存着前一条指令,如果后一段指令开始 IF 段,则 IF 段锁存器将被后一条指令所覆盖。
【例 2】五段流水线:
I1:add s2, s1, s0 // R[s2]<-R[s1]+R[s0]
I2:load s3, 0(t2) // R[s3]<-M[R[t2]+0]
I3:add s2, s2, s3 // R[s2]<-R[s2]+R[s3] // 与 I1、I2 发生数据冒险
I4:store s2, 0(t2) // M[R[t2]+0]-<R[s2] // 与 I3 发生数据冒险
指令流程图:
| 指令/时钟 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| I1 | IF | ID | EX | M | WB | |||||||||
| I2 | IF | ID | EX | M | WB | |||||||||
| I3 | IF | ID | EX | M | WB | |||||||||
| I4 | IF | ID | EX | M | WB |
1.2.2 结构冒险(资源冲突)
- 概念:由于多条指令在同一时刻争用同一资源而形成的冲突称为结构相关
- 解决办法:
- 暂停流水线:后一相关指令暂停一个时钟周期
- 资源重复配置:数据存储器 + 指令存储器
1.2.3 控制冒险
- 概念:当流水线遇到转移指令和其他改变 PC 值的指令而造成断流时,会引起控制相关
- 解决办法:
- 转移指令分支预测:简单预测(永远猜 true 或 false)、动态预测(根据历史情况动态调整)
- 预取转移成功和不成功两个控制流方向上的目标指令
- 加快和提前形成条件码
- 提高转移方向的猜准率
2 高级流水线技术
- 时间上的并行技术:流水线技术
- 空间上的并行技术:超标量技术
2.1 超标量技术
- 每个时钟周期内可并发多条独立指令,不能调整指令的执行顺序
- 要配置多个功能部件,通过编译优化技术,把可并行执行的指令搭配起来
2.2 超流水技术
- 在一个时钟周期内再分段(继续细分,比如再分为 3 段),在一个时钟周期内一个功能部件使用多次(使用 3 次)
- 不能调整指令的执行顺序,靠编译程序解决优化问题
2.3 超长指令字
- 由编译程序挖掘出指令间潜在的并行性,将多条能并行操作的指令组合成一条
- 具有多个操作码字段的超长指令字(可达几百位),采用多个处理部件
3 多处理器
- 并发:指两个或多个事件在同一时间间隔内发生。
- 并行:指两个或多个事件在同一时刻发生。
【注】对于单处理机,在多道程序环境下,一段时间内,宏观上有多道程序在同时执行,而在每个时刻,单处理机仅能有一道程序执行。此时操作系统
是通过分时来实现并发性的,没有真正实现并行性。
3.1 单指令流单数据流(SISD)结构
- 特性:各指令序列只能并发、不能并⾏,每条指令处理⼀两个数据
- 不是数据级并⾏技术!
- 硬件组成:⼀个处理器 + ⼀个存储器(若采用流水线,则需采⽤多模块交叉存储器)
3.2 单指令流多数据流(SIMD)结构
- 特性:各指令序列只能并发、不能并⾏,但每条指令可同时处理很多个具有相同特征的数据
- 是⼀种数据级并⾏技术!
- 硬件组成:⼀个指令控制部件(CU)+ 多个处理单元/执⾏单元(ALU)+ 多个局部存储器
- 每个执⾏单元有各⾃的寄存器组、局部存储器、地址寄存器,但整体只有⼀个程序计数器 PC
- 不同执⾏单元执⾏同⼀条指令,处理不同的数据
3.3 多指令流单数据流(MISD)结构
多条指令并⾏执⾏,处理同⼀个数据。现实中不存在这种计算机
3.4 多指令流多数据流(MIMD)结构
- 特性:各指令序列可以并⾏执⾏,分别处理多个不同的数据
- 是⼀种线程级并⾏、甚⾄是线程级以上并⾏技术!
3.4.1 多处理器系统(共享内存多处理器)
- 概念:⼀个CPU芯⽚中包含多个处理器,即多个核(core),因此通常也称为片级多处理器(Chip-Level MultiProcessing,CMP)
- 特性:
- 多个处理器共享⼀个主存储器,所有核共享⼀个LLC(Last-Level Cache)
- 多个处理器共享单⼀的地址空间,都可以通过 LOAD、STORE 指令访问共享的主存储器
- 硬件组成:(Intel i5、i7 处理器)
- ⼀台计算机内,包含多个处理器 + ⼀个主存储器
- 多个处理器共享单⼀的物理地址空间
3.4.2 多计算机系统
- 特性:
- 多个计算节点都有各⾃私有的主存储器
- 各计算结点的地址空间相互独⽴,不能通过 LOAD、STORE 指令访问另⼀个计算结点的主存储器
- 硬件组成:
- 由多台计算机组成,因此拥有多个处理器 + 多个主存储器
- 每台计算机拥有各⾃的私有存储器,物理地址空间相互独⽴
3.5 向量处理机
- 特性:
- ⼀条指令的处理对象是“向量”
- 擅⻓对向量型数据并⾏计算、浮点数运算,常被⽤于超级计算机中,处理科学研究中巨⼤运算量
- 硬件组成:
- 多个处理单元,多组“向量寄存器”
- 主存储器应采⽤“多个端⼝同时读取”的交叉多模块存储器
- 要有⼤容量的、集中式的主存储器,因为主存储器⼤⼩限定了机器的解题规模
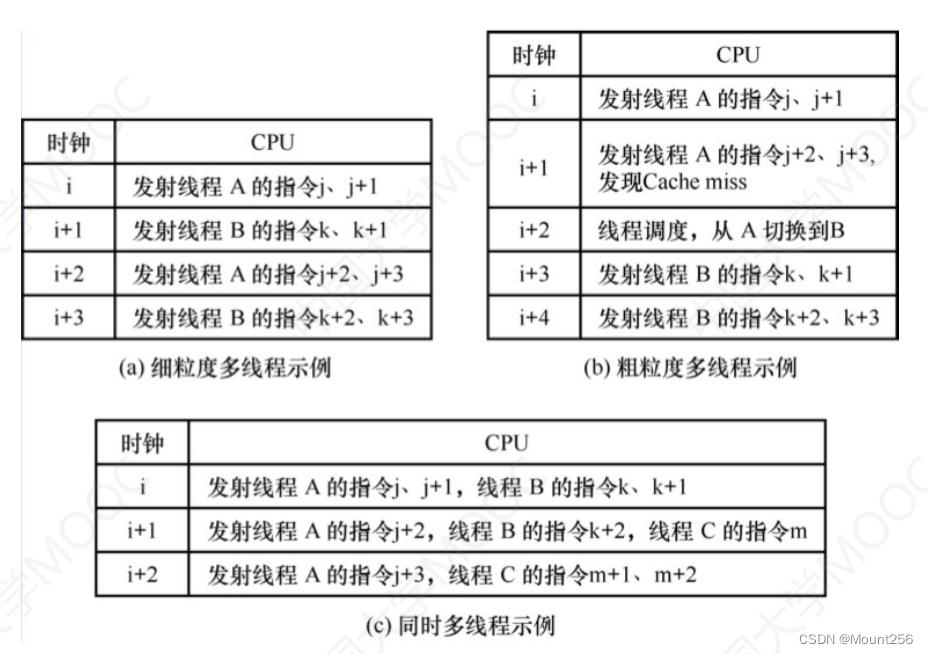
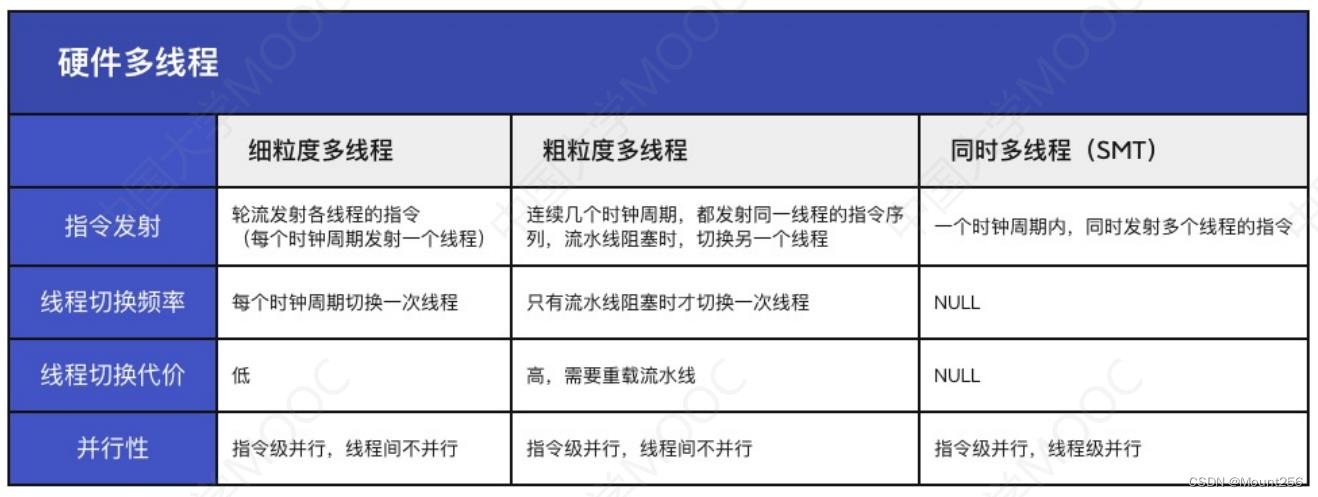
4 硬件多线程
以上是关于组成原理-处理器流水线技术的主要内容,如果未能解决你的问题,请参考以下文章