RFM 模型
Posted Debroon
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RFM 模型相关的知识,希望对你有一定的参考价值。
RFM 模型
顾客价值分析
由于激烈的市场竞争,各个公司相继推出了多样灵活的优惠方式来吸引更多的客户。
对一个没有购买力的顾客,你打电话推销优惠活动毫无作用,可一个高价值顾客,会说有优惠活动怎么不通知我呢!
为了公司能立足于市场,需要对不同的客户群体提供个性化的客户服务。
这种方法就是 RFM 模型。
RFM 模型是一个传统的数据分析模型,沿用至今约 60 年。
1961 年,乔治·卡利南在顾客的资料库中指出,最近一次消费、消费频率、消费金额三项数据可以较为客观的描绘顾客的轮廓。
企业针对近期有消费的”新客“、消费频率高的”常客“、消费金额高的”贵客“进行精准营销和广告投放,确实收到了意料之外的惊喜。
因此,这三项数据成为了衡量客户价值和客户创利能力的重要工具和手段。也是 RFM 模型的三个重要指标:
-
R(Recency):最近一次消费时间间隔,指用户最近一次消费时间距离现在的时间间隔;
-
F(Frequency):消费频率,指用户一段时间内消费了多少次;
-
M(Monetary):消费金额,指用户一段时间内的消费金额。
RFM 模型多用于精细化运营服务。单看 R、F、M 三个指标,其本身已经具备了一定的参考性:
-
一般来说,比起许久没有消费的顾客,消费时间间隔短的客户再次购买的几率较高。针对这类客户,可以采取唤醒或者刺激消费,如赠送打折券等。
-
消费频率高的客户,其忠诚度相对较高,可以规律性地提醒这类客户关于产品的一些优惠信息。
-
消费金额高的客户,客户价值也越高,可以提供专属该类客户的优惠价格。
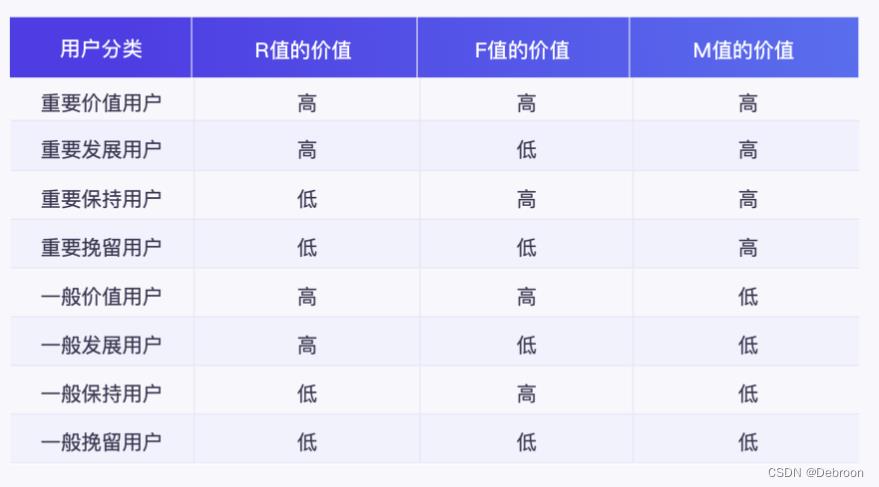
RFM 模型分析步骤:
- 最近一次消费数据 = 当前时间 - 该用户最新一次消费数据
- 消费频率 = 该用户不重复的订单号数
- 消费金额 = 该用户的所有消费额进行加和
# 计算时间间隔
today = '2000-01-01 00:00:00' # 当前时间
pd.to_datetime(today) - pd.to_datetime(grouped_data['发货日期'])
节奏,确认关键的节点进行划分。比如小学考试中满分 100 分,达到 60 分就算及格;
或者,根据实际经验进行划分。比如一般的用户消费水平在 1w,消费超过 10w 是高净值人群。
# 定义函数按照区间划分 R 值(间隔时间),返回等级越高越重要
def caculate_r(s):
if s <= 100:
return 5
elif s <= 200:
return 4
elif s <= 300:
return 3
elif s <= 400:
return 2
else:
return 1
# 对 R 值进行评分
rfm_data['R评分'] = rfm_data['时间间隔'].agg(caculate_r)
# 定义函数按照区间划分 F 值(消费频率),返回等级越高越重要
def caculate_f(s):
if s <= 5:
return 1
elif s <= 10:
return 2
elif s <= 15:
return 3
elif s <= 20:
return 4
else:
return 5
# 对 F 值进行评分
rfm_data['F评分'] = rfm_data['总次数'].agg(caculate_f)
# 定义函数按照区间划分 M 值(消费金额),返回等级越高越重要
def caculate_m(s):
if s <= 2000:
return 1
elif s <= 4000:
return 2
elif s <= 6000:
return 3
elif s <= 8000:
return 4
else:
return 5
# 对 M 值进行评分
rfm_data['M评分'] = rfm_data['总金额'].agg(caculate_m)
# 计算 R评分、F评分、M评分的平均数
r_avg = rfm_data['R评分'].mean()
f_avg = rfm_data['F评分'].mean()
m_avg = rfm_data['M评分'].mean()
得到 R、F、M 各值的阈值以后,将要为 R、F、M 各值进行高低值的标记。
将获得的阈值与 RFM 分数进行比较,高于阈值记为“高”,低于阈值记为“低”,高低值可暂时用 1 和 0 表示。
# 将R评分、F评分、M评分 的数据分别与对应的平均数做比较
rfm_data['R评分'] = (rfm_data['R评分'] > r_avg) * 1
rfm_data['F评分'] = (rfm_data['F评分'] > f_avg) * 1
rfm_data['M评分'] = (rfm_data['M评分'] > m_avg) * 1
# 拼接R评分、F评分、M评分
rfm_score = rfm_data['R评分'].astype(str) + rfm_data['F评分'].astype(str) + rfm_data['M评分'].astype(str)
# 数据已经由三个数字组成,其中 1 代表着高价值,0 代表着低价值。
为了将数字替换为价值的高低,可以使用 replace() 方法对数据进行批量替换。
# 定义字典标记 RFM 评分档对应的用户分类名称
transform_label =
'111':'重要价值用户',
'101':'重要发展用户',
'011':'重要保持用户',
'001':'重要挽留用户',
'110':'一般价值用户',
'100':'一般发展用户',
'010':'一般保持用户',
'000':'一般挽留用户'
# 按【客户类型】分组,统计用户的数量
customer_data = rfm_data.groupby('客户类型')['用户 ID'].count()
一般发展用户和一般挽留用户的人数偏多。
对于一般发展用户较多的情况,问题可能在于一般发展用户后续的复购转化不足。可以多通过短信、平台网站等渠道,在一般发展用户首购后的一段时间内可以领取复购券等策略,将这类用户转化为更高价值的用户类型。
对于一般挽留用户较多的情况,问题可能在于平台的产品竞争力或者服务不足。可以多对比竞品公司的产品,对自身的产品进行提升。同时,可以采取赠送优惠券的策略,并收集用户对平台产品以及服务的评价。
以上是关于RFM 模型的主要内容,如果未能解决你的问题,请参考以下文章