Kafka的原理和一些关键术语概念
Posted 黑马程序员官方
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka的原理和一些关键术语概念相关的知识,希望对你有一定的参考价值。
本文带大家了解Kafka基本原理和一些关键术语概念。
Kafka最初是由LinkedIn公司采用Scala语言开发的一个多分区、多副本并且基于ZooKeeper协调的分布式消息系统,现在已经捐献给了Apache基金会。目前Kafka已经定位为一个分布式流式处理平台,它以高吞吐、可持久化、可水平扩展、支持流处理等多种特性而被广泛应用。
Apache Kafka是一个分布式的发布-订阅消息系统,能够支撑海量数据的数据传递。在离线和实时的消息处理业务系统中,Kafka都有广泛的应用。Kafka将消息持久化到磁盘中,并对消息创建了备份保证了数据的安全。Kafka在保证了较高的处理速度的同时,又能保证数据处理的低延迟和数据的零丢失。

特性
- (1)高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个主题可以
- 分多个分区, 消费组对分区进行消费操作;
- (2)可扩展性:kafka集群支持热扩展;
- (3)持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失;
- (4)容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败);
- (5)高并发:支持数千个客户端同时读写
- (6)日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如Hadoop、Hbase、Solr等;
- (7)消息系统:解耦和生产者和消费者、缓存消息等;
- (8)用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点 击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时 的监控分析,或者装载到Hadoop、数据仓库中做离线分析和挖掘;
- (9)运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告;
- (10)流式处理:比如spark streaming和storm;
技术优势
可伸缩性:Kafka的两个重要特性早就了它的可伸缩性
- 1、Kafka 集群在运行期间可以轻松地扩展或收缩(可以添加或删除代理),而不会宕机。
- 2、可以扩展一个 Kafka 主题来包含更多的分区。由于一个分区无法扩展到多个代理,所以它的容量受 到代理磁盘空间的限制。能够增加分区和代理的数量意味着单个主题可以存储的数据量是没有限制的。
容错性和可靠性:Kafka 的设计方式使某个代理的故障能够被集群中的其他代理检测到。由于每个主题都可以在多个代理上复制,所以集群可以在不中断服务的情况下从此类故障中恢复并继续运行。
吞吐量:代理能够以超快的速度有效地存储和检索数据。
概念详解

Producer
生产者即数据的发布者,该角色将消息发布到Kafka的topic中。broker接收到生产者发送的消息后, broker将该消息追加到当前用于追加数据的segment文件中。生产者发送的消息,存储到一个partition中,生产者也可以指定数据存储的partition。
Consumer
消费者可以从broker中读取数据。消费者可以消费多个topic中的数据。
Topic
在Kafka中,使用一个类别属性来划分数据的所属类,划分数据的这个类称为topic。如果把Kafka看做为一个数据库,topic可以理解为数据库中的一张表,topic的名字即为表名。
Partition
topic中的数据分割为一个或多个partition。每个topic至少有一个partition。每个partition中的数据使用多个segment文件存储。partition中的数据是有序的,partition间的数据丢失了数据的顺序。如果topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
Partition offffset
每条消息都有一个当前Partition下唯一的64字节的offffset,它指明了这条消息的起始位置。
Replicas of partition
副本是一个分区的备份。副本不会被消费者消费,副本只用于防止数据丢失,即消费者不从为follower的partition中消费数据,而是从为leader的partition中读取数据。副本之间是一主多从的关系。
Broker
Kafka 集群包含一个或多个服务器,服务器节点称为broker。broker存储topic的数据。如果某topic有 N个partition,集群有N个broker,那么每个broker存储该topic的一个partition。如果某topic有N个 partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的一个partition,剩下的M个 broker不存储该topic的partition数据。
如果某topic有N个partition,集群中broker数目少于N个,那么 一个broker存储该topic的一个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种 情况容易导致Kafka集群数据不均衡。
Follower
Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与 Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。当Follower与Leader挂掉、卡住或者同步太慢,leader会把这个follower从“in sync replicas”(ISR)列表中删除,重新创建一个Follower。
Zookeeper
Zookeeper负责维护和协调broker。当Kafka系统中新增了broker或者某个broker发生故障失效时,由 ZooKeeper通知生产者和消费者。生产者和消费者依据Zookeeper的broker状态信息与broker协调数据的发布和订阅任务。
AR(Assigned Replicas)
分区中所有的副本统称为AR。
ISR(In-Sync Replicas)
所有与Leader部分保持一定程度的副(包括Leader副本在内)本组成ISR。
OSR(Out-of-Sync-Replicas)
与Leader副本同步滞后过多的副本。
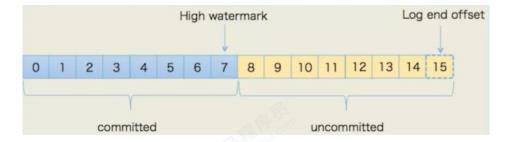
HW(High Watermark)
高水位,标识了一个特定的offffset,消费者只能拉取到这个offffset之前的消息。
LEO(Log End Offffset)
即日志末端位移(log end offffset),记录了该副本底层日志(log)中下一条消息的位移值。注意是下一条消息!也就是说,如果LEO=10,那么表示该副本保存了10条消息,位移值范围是[0, 9]。
以上是关于Kafka的原理和一些关键术语概念的主要内容,如果未能解决你的问题,请参考以下文章