QANet: Combining Local Convolution With Global Self-Attention For Reading Comprehension
Posted AI蜗牛之家
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了QANet: Combining Local Convolution With Global Self-Attention For Reading Comprehension相关的知识,希望对你有一定的参考价值。
文章目录
博主标记版paper下载地址:zsweet github
关于paper,在进入正题之前先吐槽一下,论文中说的所有矩阵都是按照tensorflow源码中的形势,所以row和column的在读论文时自己切换一下。。。
1.概述
过去几年中最成功的模型通常采用了两项关键要技术:
- 处理顺序输入的循环模型
- 应对长期交互的注意力要素。
Seo等人于2016年提出的的双向注意力流(Bidirectional Attention Flow,BiDAF)模型将这两项要素成功地结合在了一起,该模型在SQuAD数据集上取得了显著的效果。这些模型的一个缺点是,它们的循环特性使得它们在训练和推理方面的效率通常较低,特别是对于长文本而言。
QAnet模型设计的主要思想:卷积捕获文本的局部结构,而自注意力则学习每对单词之间的全局交互。附加语境疑问注意力(the additional context-query attention)是一个标准模块,用于为语境段落中的每个位置构造查询感知的语境向量(query-aware context vector),这在随后的建模层中得到使用。
CMU 和 Google Brain 新出的文章,SQuAD 目前的并列第一,两大特点:
- 模型方面创新的用 CNN+attention 来完成阅读理解任务
在编码层放弃了 RNN,只采用 CNN 和 self-attention。CNN 捕捉文本的局部结构信息( local interactions),self-attention 捕捉全局关系( global interactions),在没有牺牲准确率的情况下,加速了训练(训练速度提升了 3x-13x,预测速度提升 4x-9x) - 数据增强方面通过神经翻译模型(把英语翻译成外语(德语/法语)再翻译回英语)的方式来扩充训练语料,增加文本多样性
现在越来越觉得CNN、capsule、transformer相关非NLP技术在NLP领域的强大,以后多尝试在模型上使用这些结构!
2.模型结构
模型由五层结构组成:
- input embedding layer
- embedding encoder layer
- context-query attention layer
- model encoder layer
- output layer
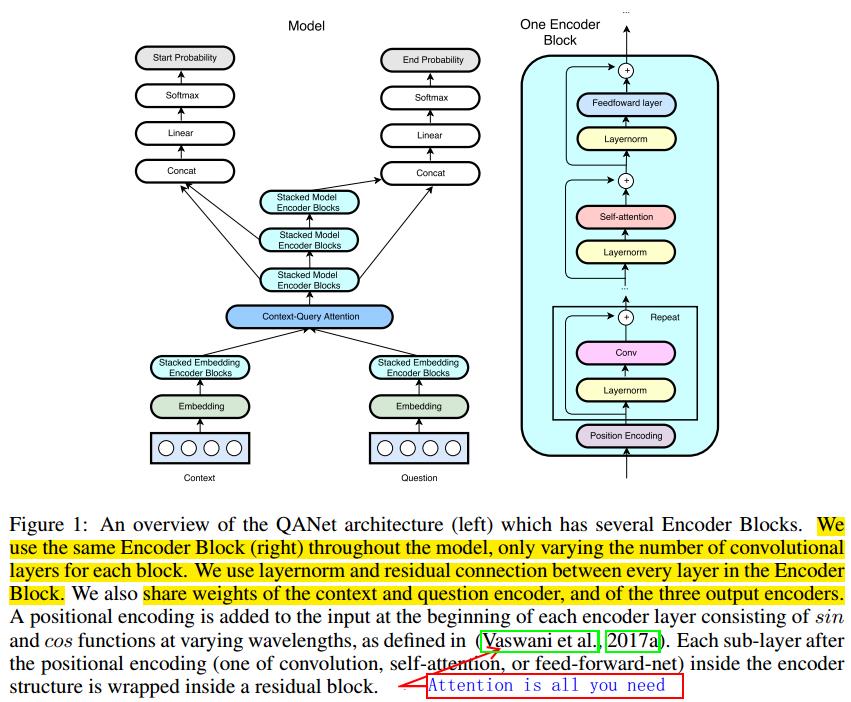
2.1.Input embedding layer
Input embedding layer和BIDAF一模一样
具体顺序是:
- 英文字母随机初始化每个字母的char-embedding(当然对中文的char-embedding最好是pretrain的),并对query和context进行lookup
- 对query和context的char-embedding过CNN,提取每个字之间的特征;
- 对query和context的pretrain的word-embedding进行lookup
- word-embedding和char-embedding进行concatenation
- 对concat的向量过两层highway,提取并保留原来的特征。(关于highway可参考博客highway netword)
word embedding+character embedding,word embedding从预先训练好的词向量中读取,每个词向量维度为
p
1
p_1
p1假设词w对应的词向量为
x
w
x_w
xw;
character embedding随机初始化,维度为
p
2
p_2
p2,将每个词的长度padding or truncating到
k
k
k,则词w也可以表示成一个
p
2
∗
k
p_2*k
p2∗k的矩阵,经过卷积和max-pooling后得到一个
p
2
p_2
p2维的character-level的词向量,记为
x
c
x_c
xc。
将
x
w
x_w
xw和
x
c
x_c
xc拼接,得到词w对应词向量
[
x
w
;
x
c
]
∈
R
p
1
+
p
2
[x_w;x_c]\\inR^p_1+p_2
[xw;xc]∈Rp1+p2,最后将拼接的词向量通过一个两层的highway network,其输出即为embedding层的输出。训练过程中,word embedding固定,character embedding随模型一起训练。
2.2 Embedding Encoder Layer
重点是这一层上的改变,由一个stacked model encoder block而成(这部分只用了1个stacked model encoder block且里面只有一个encoder block,每个encoder block里面4个卷积层,每个卷积层的filter number是128、高度是7),每个 block 的结构是:[convolution-layer x # + self-attention-layer + feed-forward-layer]
单个block结构自底向上依次包含位置编码(position encoding),卷积(conv)层,self attention层和前馈网络(fnn)层,具体参考图下图:
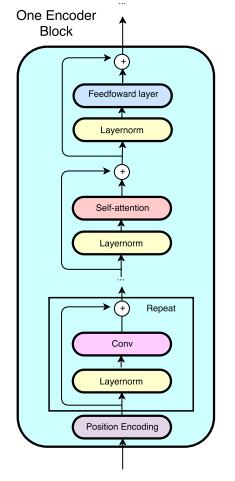
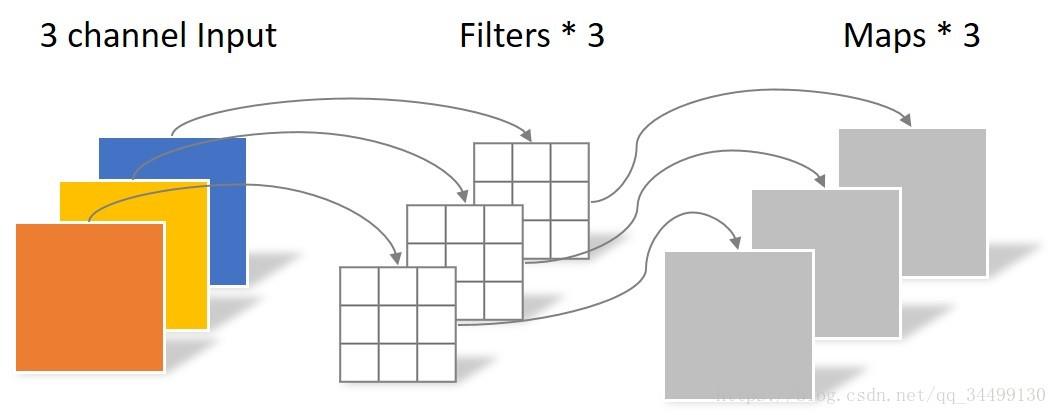
这里出去CNN之外,几乎照搬的是transformer,关于transformer可以查看我之前的文章:paper:Attention Is All You Need(模型篇) ,那接下来说下这里的CNN部分,卷积用的 separable convolutions 而不是传统的 convolution,因为更加 memory efficient,泛化能力也更强。核心思想是将一个完整的卷积运算分解为 Depthwise Convolution 和 Pointwise Convolution 两步进行,两幅图简单过一下概念:
- 先做 depthwise conv, 卷积在二维平面进行,filter 数量等于上一次的 depth/channel,相当于对输入的每个 channel 独立进行卷积运算,然后就结束了,这里没有 ReLU。
假设输入是 64 ∗ 64 64*64 64∗64的3通道图片,使用 3 ∗ 3 ∗ 1 3*3*1 3∗3∗1大小的卷积核,filter 数量等于上一层的depth,对输入的每个 channel 独立进行卷积运算,得到与上层depth相同个数的feature map。对应到图里即3个filter分别对3个channel进行卷积,得到3个feature map。如下图:
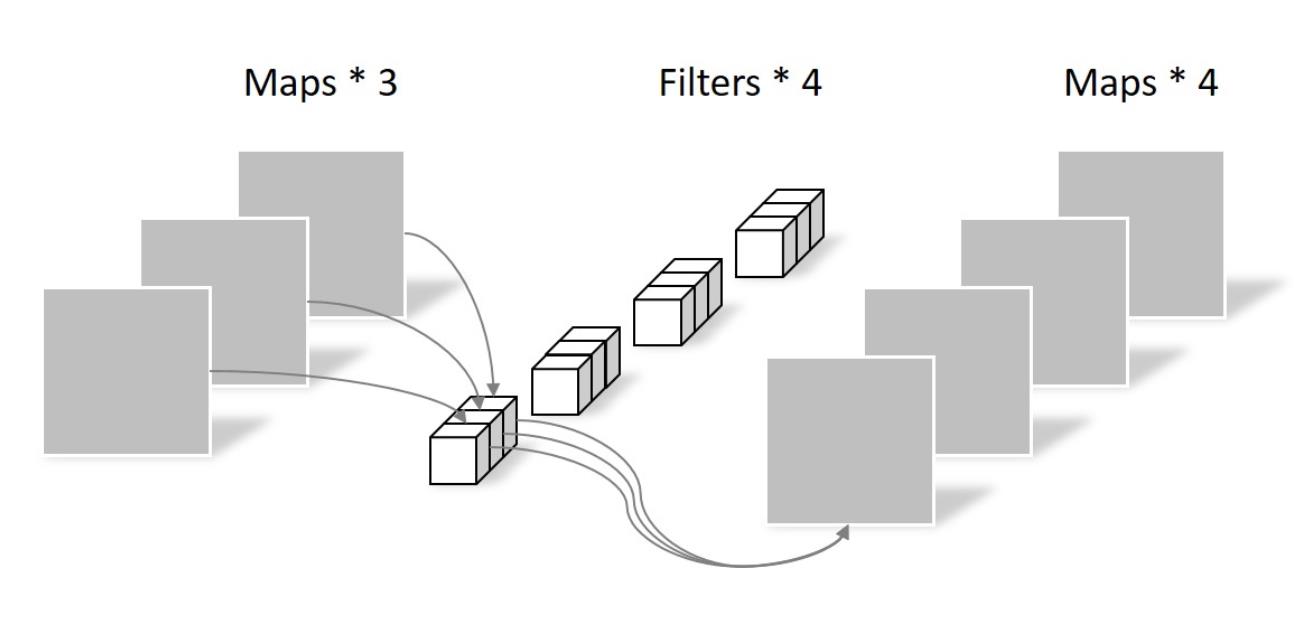
动画见https://www.slideshare.net/DongWonShin4/depthwise-separable-convolution。
编者按:
如果看过capsule的童鞋,应该还记得capsule是cnn的一个升级,所以在这里我也在想,如果把这里面的cnn替换成capsule会不会有奇效。之后有时间尝试
2.3.Context-Query Attention Layer
几乎所有 machine reading comprehension 模型都会有,而这里依旧用了 context-to-query 以及 query-to-context 两个方向的 attention:
- 先计算相关性矩阵,
- 再归一化计算 attention 分数,
- 最后与原始矩阵相乘得到修正的向量矩阵。
这里的attention步骤和BIDAF也有点像,context-to-query完全相同,但是在query-to-context的时候稍有不同。
根据上一层得到的context和query的encoder表示来计算context-to-query attention和query-to-context attention矩阵。分别用C和Q来表示编码后的context和query, C ∈ R n ∗ d C \\in R^n*d C∈Rn∗d、 Q ∈ R m ∗ d Q \\in R^m*d Q∈Rm∗d。则步骤如下:
- 首先计算context和query单词之间的相似度,结果矩阵记为S,
S
∈
R
n
×
m
S\\inR^n×m
S∈Rn×m。其中相似度计算公式为:
f
(
q
,
c
)
=
W
0
[
q
,
c
,
q
⊙
c
]
f(q,c)=W_0[q,c,q⊙c]
f(q,c)=W0[q,c,q⊙c]
其中:q、c分别为单个单词的中间表示, W 0 W_0 W0是一个可训练的参数。 - 用softmax对S的行、列分别做归一化得到 S ˉ \\barS Sˉ、 S ˉ ˉ \\bar\\barS Sˉˉ,则 context-to-query attention矩阵A= S ˉ ⋅ Q T ∈ R n ∗ d \\barS·Q^T \\in R^n*d Sˉ⋅QT∈Rn∗d,query-to-context attention矩阵B= S ˉ ⋅ S ˉ ˉ T ⋅ C T ∈ R n ∗ d \\barS·\\bar\\barS^T·C^T \\in R^n*d Sˉ⋅SˉˉT⋅CT∈Rn∗d(参考DCN模型)。
2.4.Model Encoder Layer
和 BiDAF 差不多,不过这里依旧用 CNN 而不是 RNN。这一层的每个位置的输入是 [c, a, c⊙a, c⊙b],a, b 是 attention 矩阵 A,B 的行,参数和embedding encoder layer大致相同,但是cnn 层数不一样,这里是每个 block 2 层卷积,一共7个block,并且一共用了3个这样的组合stack,并且这三个stack共享参数
更易懂地说,这里的Model Encoder Layer包含三个stacked model encoder blocks,每个stack model encoder blocks包含7个block,每个block的结构如图2-1,而每个block内部包含2个cnn卷积(也就是[convolution-layer x # + self-attention-layer + feed-forward-layer]里面的#=2)。
2.5 Output layer
分别预测每个位置是answer span的起始点和结束点的概率,分别记为
p
1
p^1
p1、
p
2
p^2
p2,计算公式如下:
p
1
=
s
o
f
t
m
a
x
(
W
1
[
M
0
;
M
1
]
)
p^1=softmax(W_1[M_0;M_1])
p1=softmax(W1[M0;M1])
p
2
=
s
o
f
t
m
a
x
(
W
2
[
M
0
;
M
2
]
)
p^2=softmax(W_2[M_0;M_2])
p2=softmax(W2[M0;M2])
其中
W
1
W_1
W1、
W
2
W_2
W2是两个可训练变量,
M
0
M_0
M0、
M
1
M_1
M1、
M
2
M_2
M2依次对应结构图中三个model encoder block的输出(自底向上)。
目标函数:
L
(
θ
)
=
−
1
N
∑
i
N
[
l
o
g
(
p
y
i
1
1
)
+
l
o
g
(
p
y
i
2
2
)
]
L(θ)=-\\frac1N\\sum_i^N[log(p_y_i^1^1)+log(p_y_i^2^2)]
L(θ)=−N1i∑N[log(pyi11)+log(pyi22)]
其中
y
i
1
y_i^1
y