基于bert模型的文本分类研究:“Predict the Happiness”挑战
Posted 沈子恒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于bert模型的文本分类研究:“Predict the Happiness”挑战相关的知识,希望对你有一定的参考价值。
1. 前言
在2018年10月,Google发布了新的语言表示模型BERT-“Bidirectional Encoder Representations from Transformers”。根据他们的论文所言,在文本分类、实体识别、问答系统等广泛的自然语言处理任务上取得了最新的成果。
2017年12月,参加了Hackerreath的一个挑战“Predict the Happiness”。在这个挑战中,我为这个文本分类问题(Predict the Happiness)构建了一个多层全连接神经网络通过提交的测试数据,我可以得到87.8%的准确率,排名是66。
在互联网上围绕BERT进行了大量的讨论之后,我选择将BERT应用到同一个Challenge中,以证明调整BERT模型是否能将我带到这个挑战的更好排名。
2. Bert安装与预训练模型
-
将BERT Github项目Copy到自己的机器上:
git clone https://github.com/google-research/bert.gitGoogle提供了四个预训练模型:
BERT-Base, Uncased: 12-layer, 768-hidden, 12-heads, 110M parametersBERT-Large, Uncased: 24-layer, 1024-hidden, 16-heads, 340M parametersBERT-Base, Cased: 12-layer, 768-hidden, 12-heads , 110M parametersBERT-Large, Cased: 24-layer, 1024-hidden, 16-heads, 340M parameters
本文下载了BERT-Base, Cased第一个进行文本分类实验。这里,我们需要以符合bert模型的格式准备文本数据。Google规定了数据的格式:
对于train.tsv or dev.tsv:
- 每行需要一个ID
- 每行需要一个整数值作为标签 ( 0,1,2,3 etc)
- 一列完全相同的字母
- 要分类的文本示例
对于test.tsv:
- 每行需要一个ID
- 想要测试的文本示例
下面的python代码片段将读取hackerreath训练数据(train.csv),并根据bert模型机型数据准备:
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from pandas import DataFrame
le = LabelEncoder()
df = pd.read_csv("data/train.csv")
# Creating train and dev dataframes according to BERT
df_bert = pd.DataFrame('user_id':df['User_ID'],
'label':le.fit_transform(df['Is_Response']),
'alpha':['a']*df.shape[0],
'text':df['Description'].replace(r'\\n',' ',regex=True))
df_bert_train, df_bert_dev = train_test_split(df_bert, test_size=0.01)
# Creating test dataframe according to BERT
df_test = pd.read_csv("data/test.csv")
df_bert_test = pd.DataFrame('User_ID':df_test['User_ID'],
'text':df_test['Description'].replace(r'\\n',' ',regex=True))
# Saving dataframes to .tsv format as required by BERT
df_bert_train.to_csv('data/train.tsv', sep='\\t', index=False, header=False)
df_bert_dev.to_csv('data/dev.tsv', sep='\\t', index=False, header=False)
df_bert_test.to_csv('data/test.tsv', sep='\\t', index=False, header=True)原始训练数据格式如下:
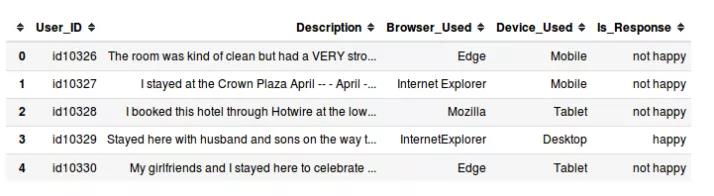
符合Bert的训练数据格式如下:
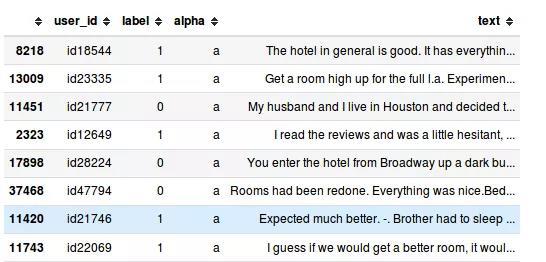
3. 使用BERT预训练模型进行模型训练
进行训练前的检查(太重要了):
- 所有的.tsv文件都在“data”的文件夹中
- 创建文件夹“bert_output”,保存经过微调的模型,并以“test_results.tsv”的名称生成测试结果
-
检查是否下载了“cased_l-12_h-768_a-12”中的预先训练的bert模型到当前目录
-
确保命令中的路径是相对路径(以“/”开头)
在终端上运行以下命令:
python run_classifier.py
--task_name=cola
--do_train=true
--do_eval=true
--do_predict=true
--data_dir=./data/
--vocab_file=./cased_L-12_H-768_A-12/vocab.txt
--bert_config_file=./cased_L-12_H-768_A-12/bert_config.json
--init_checkpoint=./cased_L-12_H-768_A-12/bert_model.ckpt
--max_seq_length=400
--train_batch_size=8
--learning_rate=2e-5
--num_train_epochs=3.0
--output_dir=./bert_output/
--do_lower_case=False在输出目录中生成“test_results.tsv”,作为对测试数据集的预测的结果它包含所有类在列中的预测概率值。
4. 提交结果
下面的python代码将结果从BERT模型转换为.csv格式,以便提交给hackerreath Challenge:
df_results = pd.read_csv("bert_output/test_results.tsv",sep="\\t",header=None)
df_results_csv = pd.DataFrame('User_ID':df_test['User_ID'],
'Is_Response':df_results.idxmax(axis=1))
# Replacing index with string as required for submission
df_results_csv['Is_Response'].replace(0, 'happy',inplace=True)
df_results_csv['Is_Response'].replace(1, 'not_happy',inplace=True)
# writing into .csv
df_results_csv.to_csv('data/result.csv',sep=",",index=None)下图显示了将概率值转换为提交结果的过程:
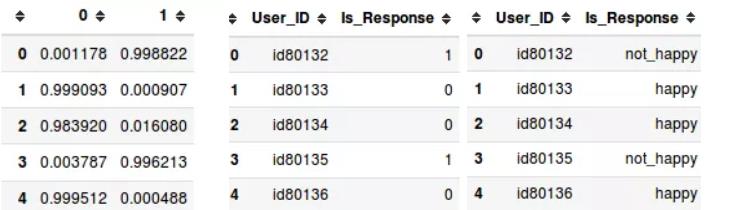
BERT的威力就是可以将排名从66升到第4!!!
5. 总结
- Bert的训练环节:
该模型使用两个新的无监督预测任务进行预训练:
BERT使用了一种简单的方法:MASK输入中15%的单词,通过一个深度Bidirectional Transformer encoder运行整个序列,然后只预测MASK的单词例如:
Input: the man went to the [MASK1] . he bought a [MASK2] of milk.
Labels: [MASK1] = store; [MASK2] = gallon为了学习句子之间的关系,BERT还训练了一个可以从任何单语语料库生成的简单任务:给定两个句子a和b,预测b是a之后的实际下一个句子,还是只是语料库中的一个随机句子。
Sentence A: the man went to the store.
Sentence B: he bought a gallon of milk.
Label: IsNextSentence
Sentence A: the man went to the store.
Sentence B: penguins are flightless.
Label: NotNextSentence- 根据模型体系结构的规模,有两个预先训练的模型,即BASE和LARGE。
BERT BASE:
Number of Layers =12
No. of hidden nodes = 768
No. of Attention heads =12
Total Parameters = 110M
BERT LARGE:
Number of Layers =24,
No. of hidden nodes = 1024
No. of Attention heads =16
Total Parameters = 340M
以上是关于基于bert模型的文本分类研究:“Predict the Happiness”挑战的主要内容,如果未能解决你的问题,请参考以下文章