读《基于深度学习的跨视角步态识别算法研究》
Posted Mighty_Crane
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了读《基于深度学习的跨视角步态识别算法研究》相关的知识,希望对你有一定的参考价值。
2020
背景:
作为一种新兴的识别技术,步态识别具有在非受控、远距离、低分辨率的场景下进行身份识别的优点,并且步态不易改变和伪装,所以近年来得到的关注逐渐增多。
步态识别作为一种新兴的身份识别技术,可以根据人们走路姿势的不同来区分个体身份。与现有的如人脸、指纹等需要近距离采集且需要人员配合的生物特征相比,步态具有低分辨率、受环境影响小、易采集等优点。此外,行人步态可以在个体毫无觉察的情况下被采集到以进行识别,而且行人走路姿势也难以伪装和模仿。步态识别的这些优势使得其最近受到研究人员的关注越来越多。目前,在丹麦、英国等国家和地区,步态分析己经在刑事犯罪案件中投入使用,办案人员通过步态识别系统分析可疑人员的走路姿态,以提升筛查效率和准确性,降低了因人脸识别、行人重识别等技术失效和人工筛查的低效性所导致嫌犯逃离的可能性。
但是在日常生活中,监控系统中捕获的步态样本与注册的步态样本往往存在视角差异,这会大大的削弱经典步态识别算法的有效性。所以,解决跨视角步态识别问题、提高步态识别的准确性和实时性,是步态识别产品必须要攻克的技术难题。
当前困难
目前跨角度步态识别的困难在于行人步态在不同视角下的视觉差别巨大。由于步态特征仅包含行人的体型轮廓以及走路姿态信息,不包含颜色和纹理特征,这使得从不同视角的步态中,很难提取表征行人身份的视角不变性特征。为了解决步态识别在跨角度时识别率低的问题
当前解决方法
第一类是通过全景相机或多个校准相机进行3D步态信息构建的跨角度识别方法
这些方法需要复杂的可控摄像机的设置,这在实际应用中难以实现。另一方面,这些方法计算负荷大,进一步限制了其实际应用的可能。
第二类是基于视角转换模型VTM的跨视角识别方法。这种方法利用来自其他视角的信息集中使用诸如奇异值分解和回归等技术来构建步态特征。
VTM方法仅仅减小了变换视角的步态特征与原始特征之间的差异,并没有考虑不同个体间的判别性因素,且这类方法在建模计算时很容易造成噪声传播,导致识别率不佳。
第三类是提取具有视角不变性的步态特征。
受限于步态数据跨视角步态标签不足的问题,很难完成模型训练,并且通常使用的损失函数都是生搬硬套人脸识别任务中广泛使用的损失函数
提取对视角变化不敏感的特征可以减小现实场景中视角多变对步态识别技术有效性的影响,实现无论行人以何种角度经过摄像头,都能准确识别出目标身份的目的,这会大大提高步态识别技术的鲁棒性和实际应用价值,推进步态识别技术产业化和标准化,形成完整的产品或服务以在现实生活中发挥作用
当前困难的本质
同一个人的步态从各个角度拍摄成像的步态轮廓是不同的,而且拍摄视角差别越大,同一行人的差异就越大。对于人类而言,这个问题往往可以通过大脑中复杂的运算推理和三维转换判断出这些不同视角的步态是否来自同一个人。但是,对于计算机而言,其输入仅仅是由离散像素点排列而成的二维数字图像,要通过这些像素点来解决视角不变问题是非常有挑战性的。另外一方面,步态特征是不包含行人的穿着等颜色和纹理特征,仅包括行人的轮廓以及行走姿势特征,所以我们无法从颜色和纹理上推理出视角的转换关系,这无疑增加了跨视角的识别难度。对于步态特征而言,可以认为其仅包含三类信息:视角信息、身份信息以及由不同穿着、背包、轮廓分割误差所产生的噪声千扰信息。因此,如果能够将步态特征中的视角信息和身份信息进行分离,仅用只包含身份信息的特征进行识别,会大大提升跨视角步态识别的精度,提高抗视角千扰能力。
给定一个查询样本,跨视角步态识别的目的是从与该查询样本视角不同的某视角的注册数据集中正确找到与该查询样本身份相同的注册样本。
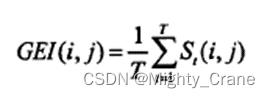
其中,G表示生成的步态能量图中位置(i,j)的像素值,s表示步态序列中/时刻的步态剪影图的位置(i,j)的像素值,T表示此步态序列的长度。实际应用中,在计算步态能量图之前,要先进行步态的矫正和对齐,使每个时刻的步态剪影图的重心位置重合。
(将仅有的两个特征视角和身份拆开分析)
本章提出了身份与视角特征分离的跨视角步态识别算法,将步态特征中的视角信息和身份信息进行分离,仅用只包含身份信息的特征进行识别,提升了跨视角步态识别的精度,提高了抗视角干扰能力。为了保证所提取的身份特征与视角特征是来自该步态样本的全部信息,本章采用了自编码器的方式来恢复原始输入的步态样本,设计了视角编码器、身份编码器和步态解码器。
(将仅有的两个特征视角和身份一起分析)
在步态识别任务中,如何提取既具有身份判别能力还具有视角不变性的特征是提高步态识别精度的关键。而在现实生活中,人们往往只需要关注行人走路时身体的一部分运动特点和体型特点就可以判断出该行人的身份,这意味着行人身体的不同部分在步态特征表达中所占的权重是不一样的,所以对行人身体进行分块是很有必要的。在具体特征表达方面,水平金字塔是一种在水平方向上的多尺度特征提取方法,并且己经被证明在行人再识别任务上有出色的表现。
展望:
虽然提纯身份特征的损失可以提高识别率,但是这只说明组合损失有利于增强表征判别性,但可能特征里还有干扰。解决思路:研究特征的分布,可视化(TSNE?);GAN分解步态样本
在数据集上的效果并没有明显超越前人,原因是数据集视角较少且相邻视角跨度很小。说明此方法在视角差别很小时对步态样本的身份和视角特征分离的作用不明显,所以未来可以设计更精细的网络来解决此问题;
背包、不同穿着等情况下存在泛化性能挑战。未来可以尝试通过特征选择来解决,对于那些表达背包和穿着的干扰信息,用特征选择的方法将其滤除,可能会取得更好的识别效果。(行人重识别还好说,有颜色啥的分割,这全是白块怎么知道哪是背包,哪是穿着)
以上是关于读《基于深度学习的跨视角步态识别算法研究》的主要内容,如果未能解决你的问题,请参考以下文章