Stable Diffusion7
Posted tt姐whaosoft
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Stable Diffusion7相关的知识,希望对你有一定的参考价值。
它也写到第七部了..
Stability AI宣布,Stable Diffusion 2.0版本上线!1.0版本在今年8月出炉,三个月不到,还热乎着呢,新版本就来了。
深度学习文本到图像模型的最新版本——Stable Diffusion 2.0。相较于1.0,新的算法比之前的更高效、更稳健。
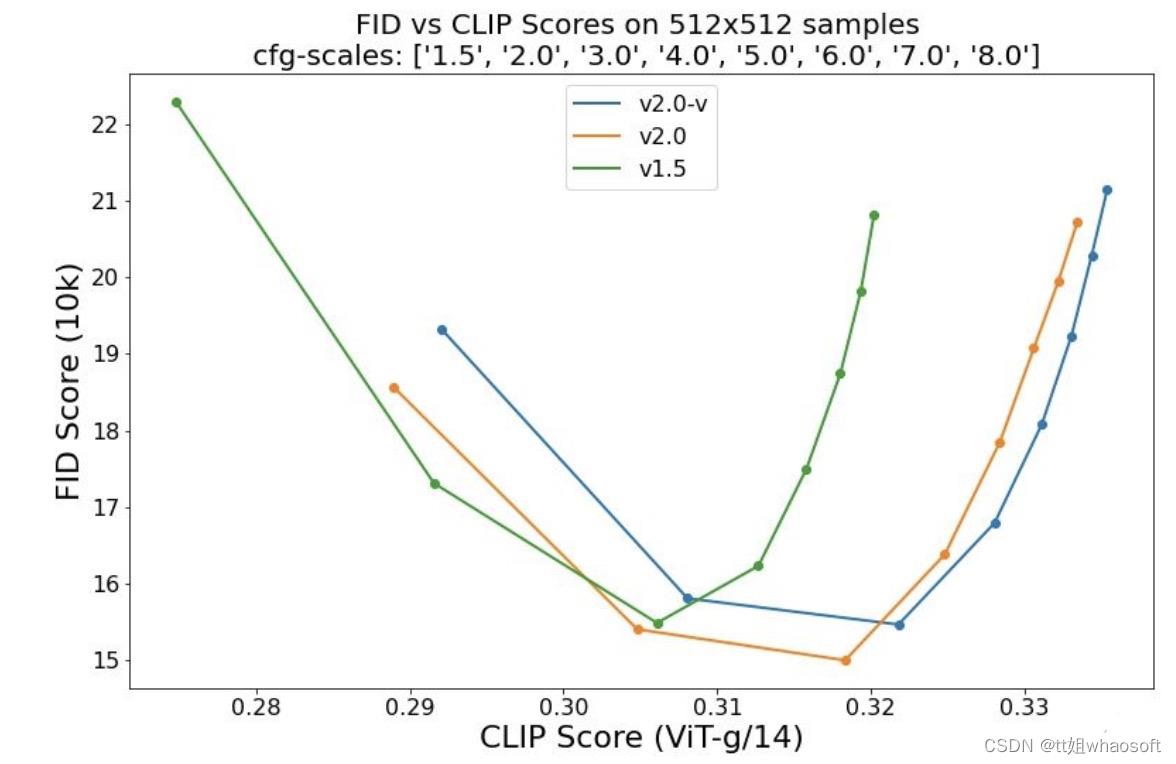
时间回到几个月前,Stable Diffusion的发布,掀起了一场文本到图像模型领域的新革命。
可以说,Stable Diffusion 1.0彻底改变了开源AI模型的性质,并且在全球范围内催生了数百种新模型,和其他方面的进步。
它是最快达到10K Github star星数的项目之一,在不到两个月的时间里飙升至33K星,在Github上的一众项目中可以封神了。
开发Stable Diffusion 1.0版本的团队是Robin Rombach(Stability AI)和 Patrick Esser(Runway ML),他们来自LMU Munich CompVis Group。
在实验室之前的Latent Diffusion Models基础上,他们开发出了Stable Diffuision 1.0,并且得到了 LAION 和 Eleuther AI 的大力支持。

这次的Stable Diffusion 2.0版本,具有强大的文本到图像模型。
这个模型是由LAION在全新的文本编码器OpenCLIP训练的,跟1.0版本相比,它显著提高了生成图像的质量——这次的模型可以输出默认分辨率为512×512像素和768×768像素的图像。 
使用Stable Diffusion 2.0生成的图像示例,分辨率为768x768
模型在Stability AI的DeepFloyd团队创建的LAION-5B数据集上进行训练。
LAION-5B是一个包含58.5亿个CLIP过滤图像文本对的数据集,比LAION-400M大14倍,曾是世界上最大的可公开访问的图像文本数据集。
训练完成后,就使用LAION的NSFW过滤器进一步过滤,删掉「成人内容」。
这对于很多网友来说,堪称是「史诗级削弱」了……
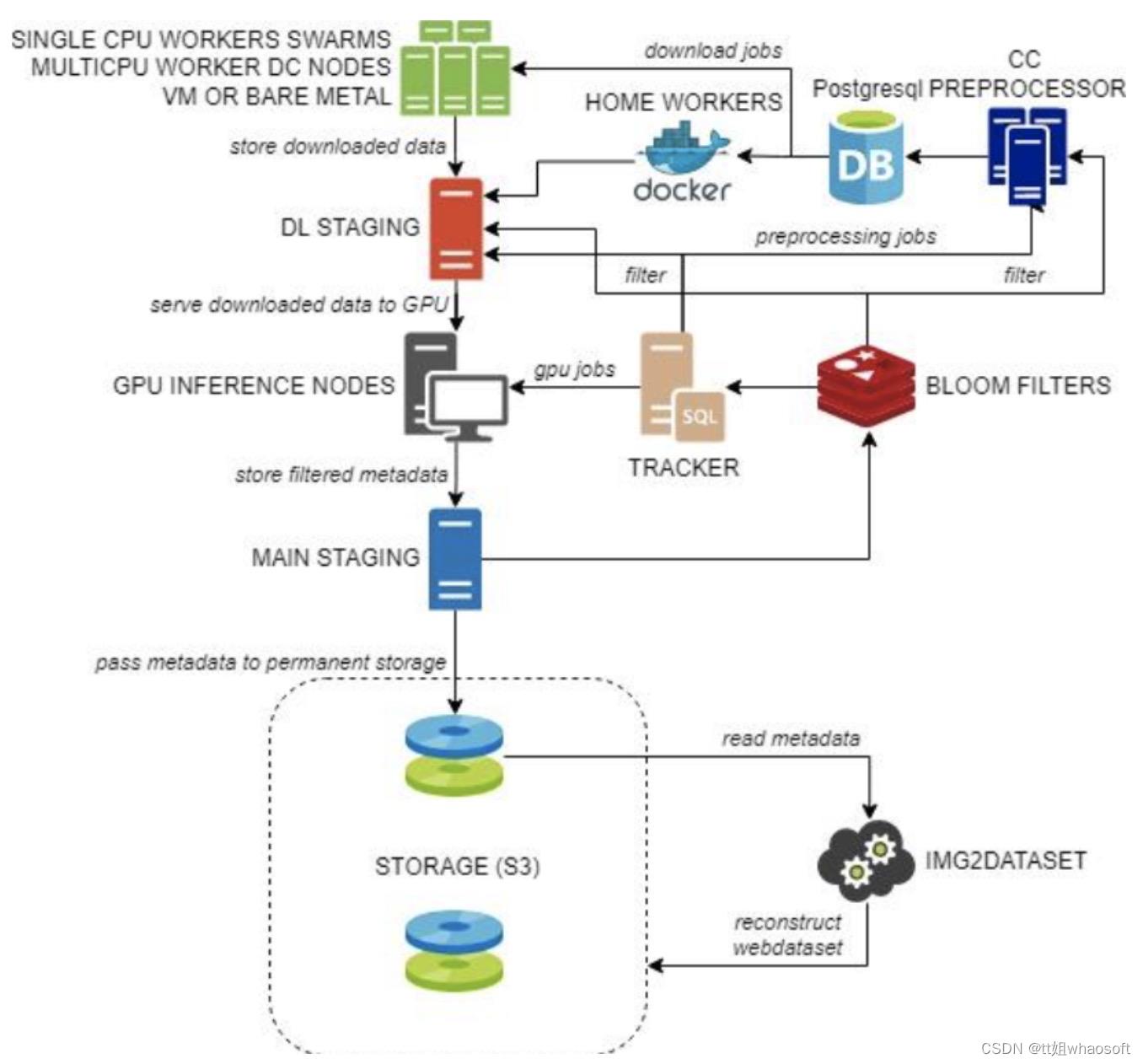
LAION 5B的采集管道流程图
2.0比1.0强在哪里?
具体来看,2.0比1.0有了哪些升级呢?
图像生成质量明显提升
上文我们已经看到,2.0版本中的文本转图像模型默认可以生成512x512 和 768x768 像素分辨率的图像。

超分辨率Upscaler扩散模型
Stable Diffusion 2.0包含了一个Upscaler Diffusion模型,这个模型可以将图像分辨率提高四倍。

左图:128x128 低分辨率图像。右图:Upscaler 生成的 512x512 分辨率图像
可以看出,这个模型将低质量生成图像 (128×128) 放大为更高分辨率图像 (512×512) 。
有了Upscaler Diffusion的加持,Stable Diffusion 2.0与以前的文本到图像模型结合使用时,可以生成分辨率为2048×2048或更高的图像。
depth2img深度图像扩散模型
团队采用了一种新的深度引导(depth-guided)稳定扩散模型——depth2img。
它扩展了1.0之前的图像到图像功能,为创意应用提供了全新的可能性。
通过使用现有模型,Depth2img能够推断输入图像的深度,然后使用文本和深度信息生成新图像。

左边的输入图像可以产生几个新图像(右边)。这种新模型可用于保持结构的图像到图像和形状条件图像合成(structure-preserving image-to-image and shape-conditional image synthesis)
Depth-to-Image
Depth-to-Image 可以提供各种新的创意应用程序,转换后的图像看起来与原始图像截然不同,但仍保持了图像的连贯性和深度。

更新文本引导修复扩散模型
此外,这次更新还引入了一个新的文本引导(text-guided)修复模型,在新的Stable Diffusion 2.0文本到图像的基础上进行了调整,这样,用户就可以非常智能、快速地替换图像的部分内容。

更新后的修复模型在 Stable Diffusion 2.0 文本到图像模型上进行了微调
过滤掉一些NSFW(不可描述)的内容
经过LAION的NSFW过滤器,「成人内容」都会被砍掉。
总结一下,Stable Diffusion 2 的更新如下——
-
新的SD模型提供了768×768的分辨率。
-
U-Net的参数数量与1.5版相同,但它是从头开始训练的,并使用OpenCLIP-ViT/H作为其文本编码器。一个所谓的v预测模型是SD 2.0-v。
-
上述模型是由SD 2.0-base调整而来,它也是可用的,并作为典型的噪声预测模型在512×512图像上进行训练。
-
增加了一个具有x4比例的潜在文本引导的扩散模型。
-
完善的SD 2.0基础的深度引导的稳定扩散模型。该模型可用于结构保留的img2img和形状条件合成,并以MiDaS推导的单眼深度估计为条件。
-
在SD2.0的基础上建立了一个改进的文字引导的绘画模型。
-
 在博客最后,Stability AI团队激动地说——
在博客最后,Stability AI团队激动地说——就像Stable Diffusion的第一次迭代一样,我们努力优化模型,让它在单个GPU 上运行,因为我们希望从一开始就让尽可能多的人可以使用它。
我们已经看到,当数百万网友接触到这些模型时,他们共同创造了一些令人惊叹的作品。
-
这就是开源的力量:挖掘数百万有才华的人的巨大潜力。他们可能没有资源来训练最先进的模型,但他们有能力用一个模型创造令人难以置信的成果。这个新版本及其强大的新功能,将成为无数应用程序的基础,并激发人们全新的创造潜力。
第一家AI绘画「独角兽」
作为机器学习模型的一种,「文本-图像模型」能够将自然语言描述作为输入并生成与该描述匹配的图像。
它们通常结合了语言模型和生成图像模型:语言模型将输入文本转换为潜在表示,生成图像模型则将该表示作为条件生成图像。
最有效的「文本-图像模型」,通常是根据从网络上抓取的大量图像和文本数据进行训练的。
依托深度神经网络技术的飞速进步,「文本-图像模型」从2015年开始获得广泛重视。
OpenAI的DALL-E、Google Brain的Imagen等,都能输出质量与真实照片相接近的绘画作品。
Stability AI创建的绘画平台Stable Diffusion,则成为领域杀出的一匹「黑马」。
Stable Diffusion的母公司Stability AI,成立于2020年,总部位于伦敦。
公司背后的出资人是数学家、计算机科学家Emad Mostaque,来自孟加拉国,今年39岁。
Mostaque毕业于牛津大学数学和计算机科学学院,曾在一家对冲基金公司工作过13年。

Stability AI首席执行官Emad Mostaque
凭借Stability AI和他的私人财富,Mostaque希望能够培育一个开源AI研究社区。他的创业公司之前就支持创建「LAION 5B」数据集。
为了训练Stable Diffusion的模型,Stability AI为服务器提供了4,000个Nvidia A100 GPU。
与OpenAI旗下多款AI工具平台不同,开发者可以免费下载Stability AI的底层代码,来训练自己的模型。
Stability AI官网顶部的Slogan「AI by the people,for the people」,正是这种价值观的最好诠释。

「人类面临的一些重大挑战有望通过AI解决,」Emad Mostaque表示,「但只有当这项技术面向所有人时,我们才可能达成这一目标。」
「除了我们的75名员工之外,没有任何其他人拥有决策权——无论是亿万富翁、大型基金,还是政府,我们是完全独立的。」Mostaque说,「我们计划使用我们的计算来加速基础人工智能的开源。」
Stable Diffusion是Stability AI独立研发的「文本到图像模型」,于2022年8月发布,一经推出便迅速被一众网友玩疯了。
比如被变成黑寡妇的马院士——

作为目前可用性最高的开源模型,Stable Diffusion在短短2个月的时间里已经被全球超过20万名开发者下载和使用。
Stability AI面向消费者的产品名为DreamStudio,目前已经拥有超过100万名注册用户——他们共同创建了超过1.7亿张图像。
今年10月,Stable Diffusion母公司Stability AI获得了由全球风险投资公司Lightspeed Venture Partners和Coatue Management领投的1.01亿美元融资,估值突破了10亿美元,也是AI绘画领域的第一家「独角兽」。
11月24日,刚刚完成融资的Stability AI便发布了2.0版本,这也让我们对Stable Diffusion的未来产生了更多期待。
网友:体验下降,差评!
不过在国外社交媒体上,不少网友却对Stable Diffusion的本次更新给出了「差评」,理由自然是「模型生成NSFW内容和图片的能力被削弱了」。
是的,这次模型的关键组件功能被改进,使得Stable Diffusion更难生成某些引起争议和批评的图像了,比如广受欢迎的裸体和色情内容、名人的逼真照片以及模仿特定艺术家作品的图像。

「他们削弱了模型,」一位用户在Stable Diffusion的reddit上评论道,还获得了208次点赞,完全能代表广大网友的心声。

另一位用户则表示:「他们切除并『阉割』了模特。没有艺术,没有人体的自然美,没有画家和摄影师最好的作品中描绘的生死戏剧,这比丑陋本身还要糟糕。」

NSFW的全称是「Not Suitable For Work」,简单讲就是一些不适合上班时间浏览的东东。
与OpenAI的DALL-E等「竞争对手」不同,Stable Diffusion是一款完全开源的软件。这允许社区的小伙伴一同开发、改进这款产品,并让开发人员免费将其集成到他们的产品中。
Stable Diffusion「背后的男人」Emad Mostaque曾将它比作「披萨基地」,任何人都可以添加他们选择的成分(训练数据)。
「一个好的模型应该可以供所有人使用,如果你想添加东西,那就加。」他在Discord上表示。
这意味着Stable Diffusion在使用方式上的限制比较少,但也因此,它招致了大量批评。
Stable Diffusion和其他图像生成模型在未经艺术家同意的情况下,在他们的作品上进行训练,并重现他们作品的风格,许多艺术家大为光火。

Stable Diffusion生成特定艺术家风格图像的能力十分强大
这种AI式复制是否合法?目前,这在法律上还是一个悬而未决的问题。
专家表示,在受版权保护的数据上训练人工智能模型可能是合法的,但某些用例可能会在法庭上受到质疑。
可以猜测,Stability AI对模型所做的更改是为了减轻这些潜在的法律挑战。

这次2.0版本的更新,对软件编码和检索数据的方式进行更改,因此,模型复制艺术家作品的能力大大降低。
正统艺术家满意了,创造力爆棚的「成人艺术家」们却很愤怒。
此前,Stable Diffusion就因「涩图生成神器」之名蜚声海内外。
老司机们用它生成一些极具真实感和动漫风格的NSFW内容,甚至包括一些特定个人的NSFW图像(也称非自愿色情)和虐待儿童的图像。

前两天,一款专门生成高质量色情内容而量身定制的AI系统「Unstable Diffusion」应运而生。
此后,大量Reddit和4chan的网民火速用Unstable Diffusion生成了逼真的裸体图像,被「老司机」们玩出了花。
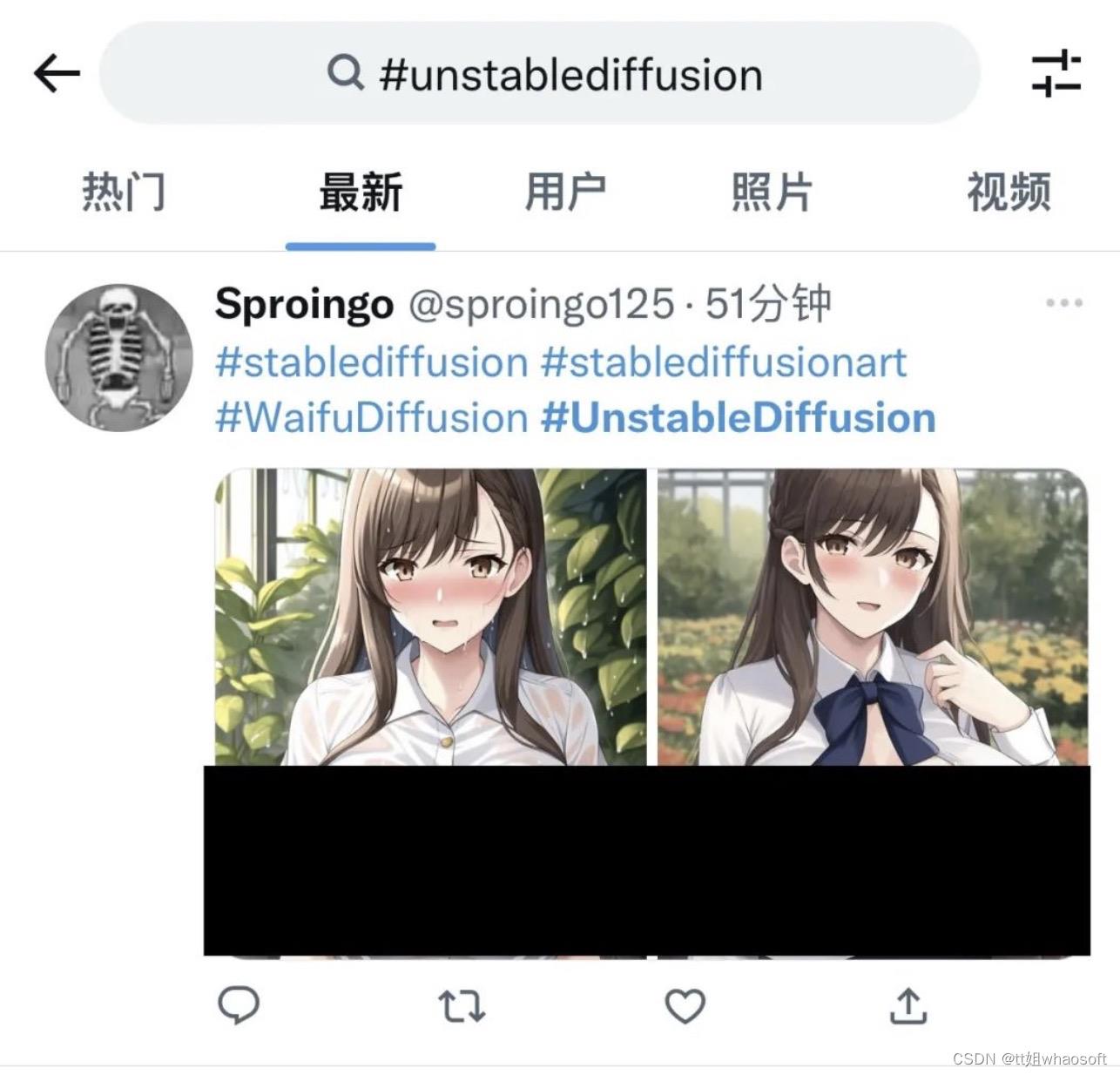

在软件官方Discord中谈到2.0版本的变化时,Mostaque也承认这正是Stable Diffusion从训练数据中删除裸体和色情图片的初心。
「在开放模式中不能有儿童和NSFW,」Mostaque说,「因为这两种图像可以结合起来制作儿童性虐待素材。」
「在儿童和NSFW中,我们只能选择一个。」
不过在Stable Diffusion的reddit上,一位用户认为「违背了开源社区的精神哲学」,因为删除NSFW内容设立了「审查制度」。
「选择是否制作NSFW内容的权力,应该掌握在用户手中,而不是由审查模式来评判。」
但已经有聪明的网友很快就想通了,安慰了他——
Stable Diffusion是开源的,这意味着「这类」训练数据可以很容易地添回第三方版本,而且新软件不会影响早期版本。
参考资料:
https://stability.ai/blog/stable-diffusion-v2-release
https://twitter.com/StabilityAI/status/1595590319566819328?ref_src=twsrc%5Etfw
https://www.reddit.com/r/StableDiffusion/comments/z3ferx/comment/ixlmkkj/?utm_source=share&utm_medium=web2x&context=3
https://theverge.vip/2022/11/24/23476622/ai-image-generator-stable-diffusion-version-2-nsfw-artists-data-changes
whaosoft aiot http://143ai.com
以上是关于Stable Diffusion7的主要内容,如果未能解决你的问题,请参考以下文章