精通系列-案例开发-巨细HttpClient5 + jsoup + WebMagic + spider-flow万字长文一篇文章学会
Posted 蓝匣子itbluebox
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了精通系列-案例开发-巨细HttpClient5 + jsoup + WebMagic + spider-flow万字长文一篇文章学会相关的知识,希望对你有一定的参考价值。
网络爬虫 ( web crawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,在java的世界里,我们经常用HttpClient ,jsoup ,WebMagic,spider-flow 这四种技术来实现爬虫。
Java之爬虫【一篇文章精通系列】HttpClient + jsoup + WebMagic + ElasticSearch导入数据检索数据
一、入门程序
1、环境准备
- JDK1.8
- lntelliJ IDEA
- IDEA自带的Maven
2、环境搭建
创建Maven工程并给pom.xml加入依赖

在Maven当中搜索对应的依赖
https://mvnrepository.com/
搜索HttpClient
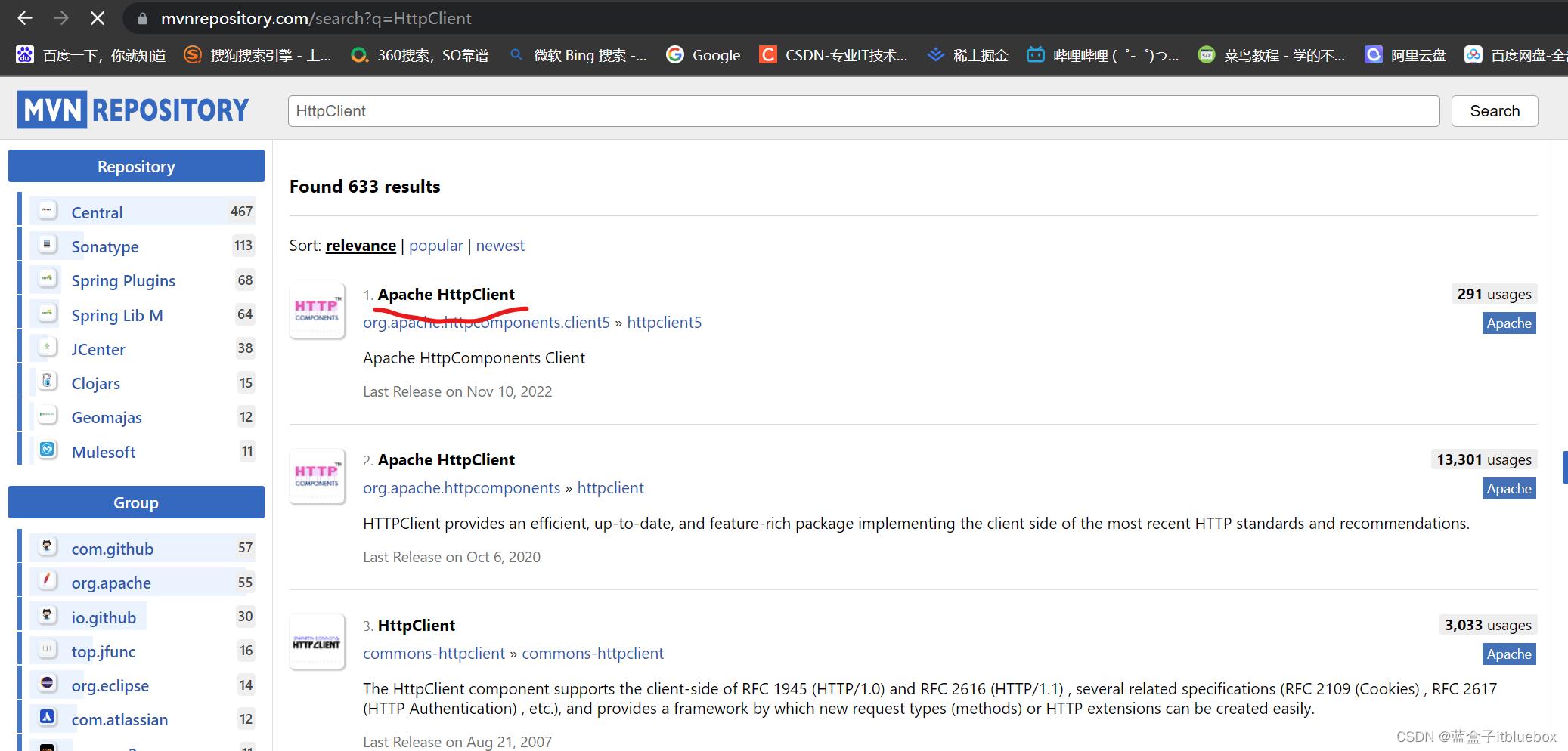
我们选择使用量最多的


将依赖引入工程当中

<dependency>
<groupId>org.apache.httpcomponents.client5</groupId>
<artifactId>httpclient5</artifactId>
<version>5.1.3</version>
</dependency>
搜索slf4j
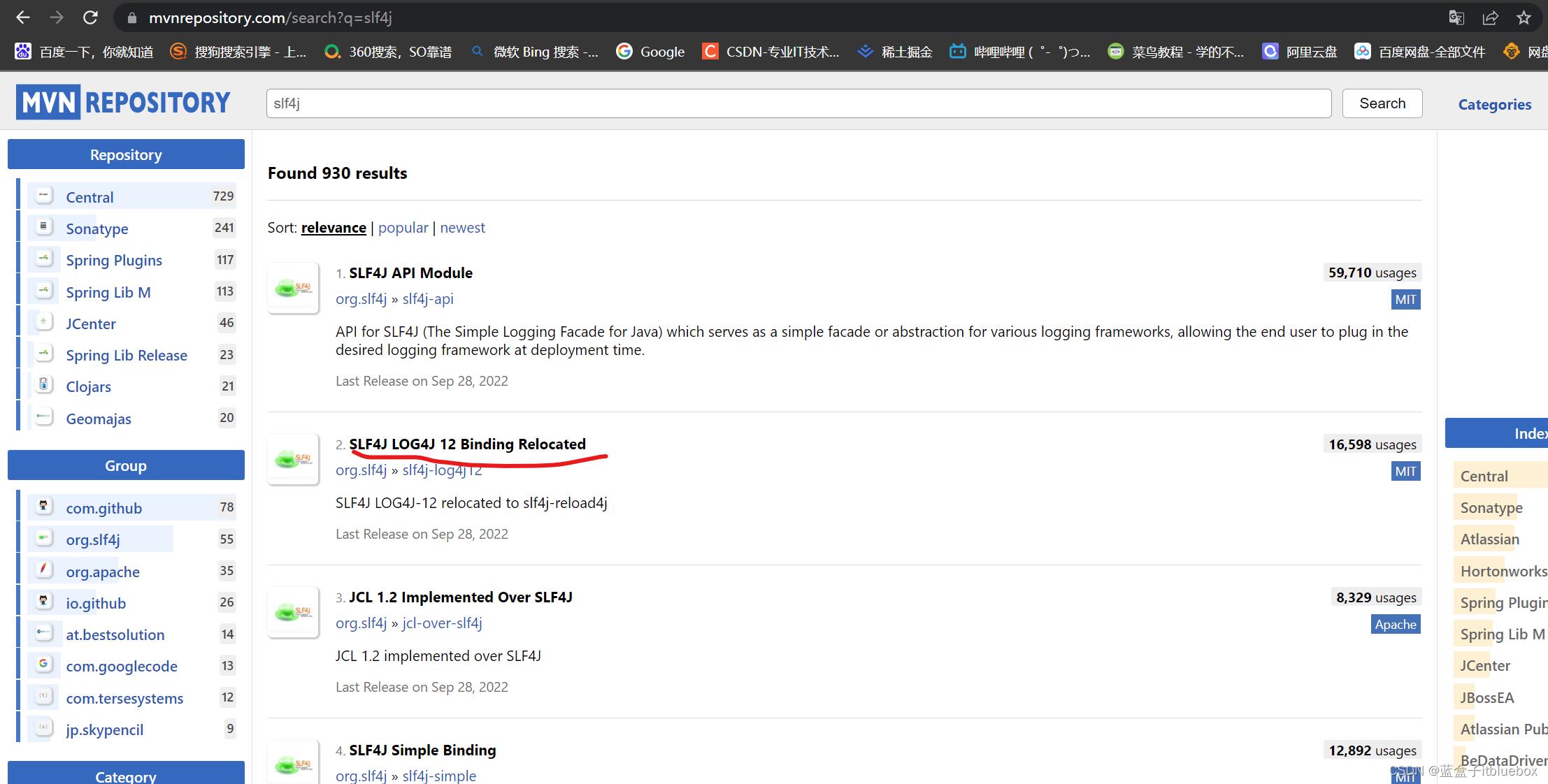

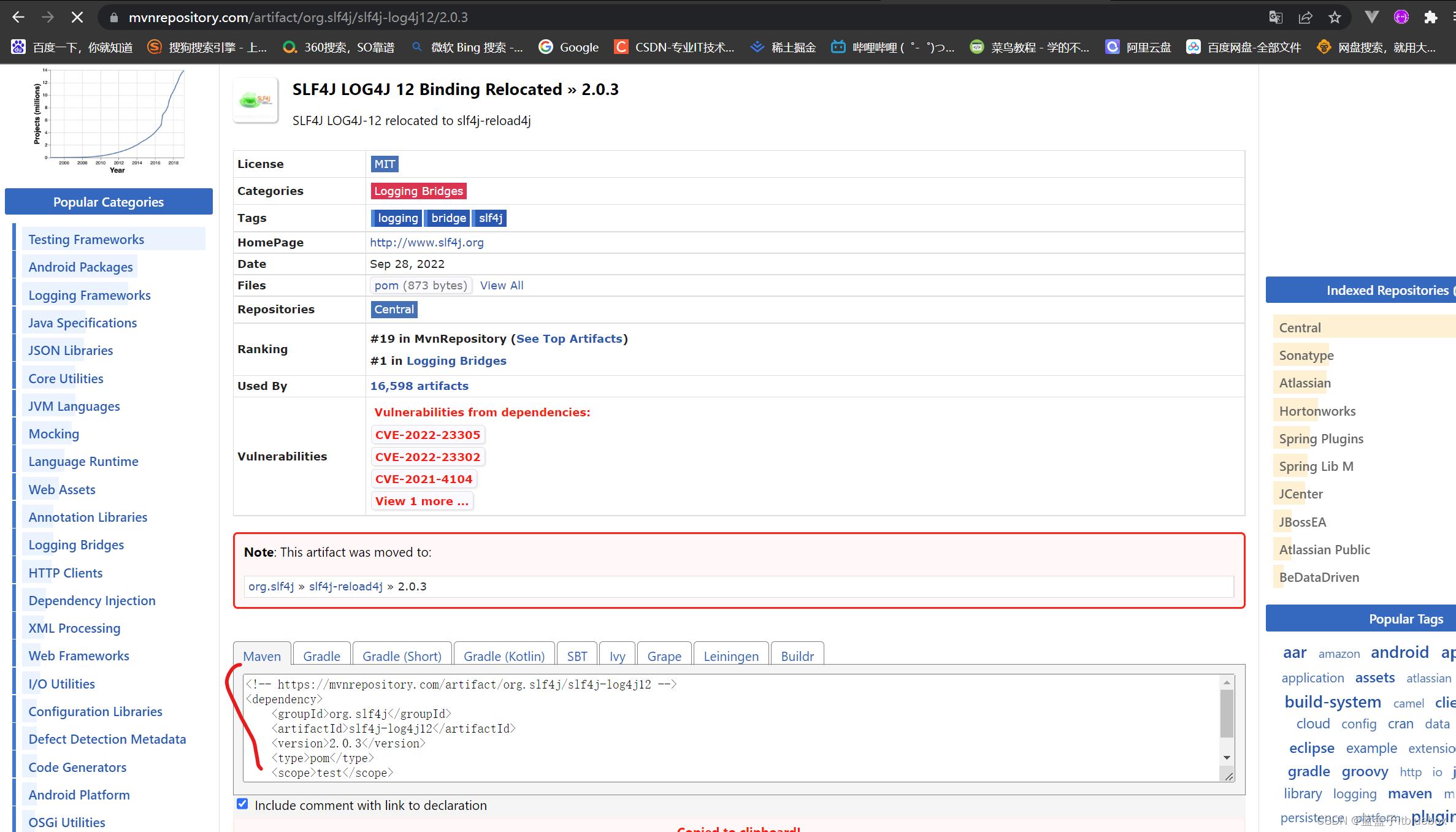

<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.25</version>
<scope>test</scope>
</dependency>
完善日子配置文件
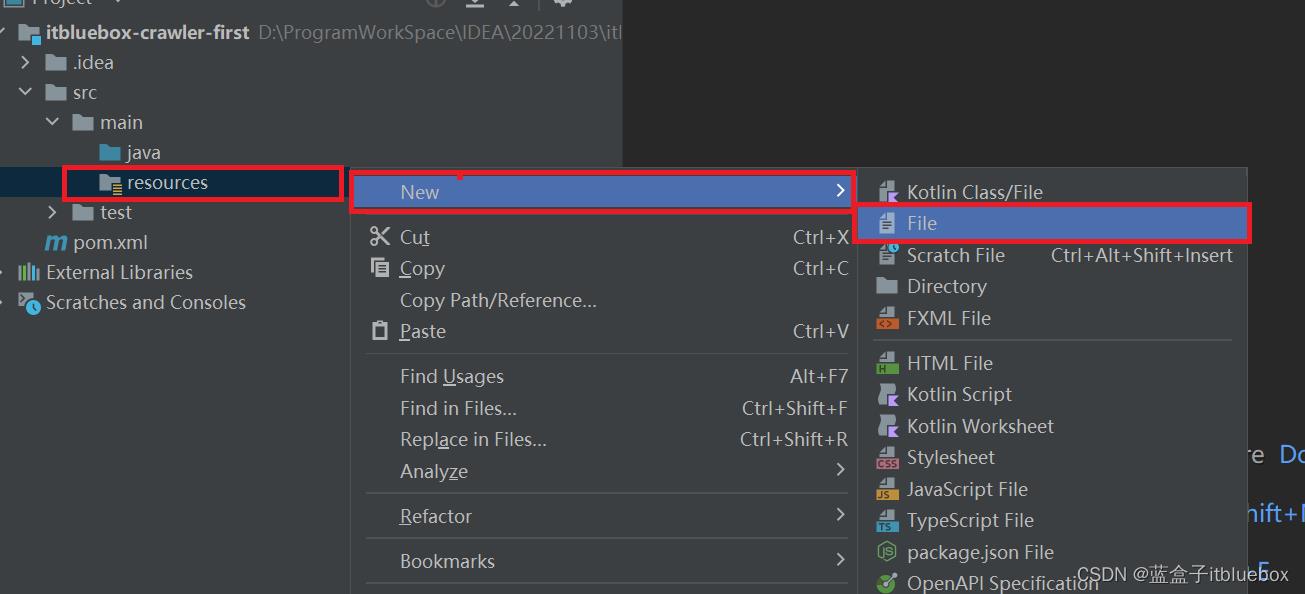
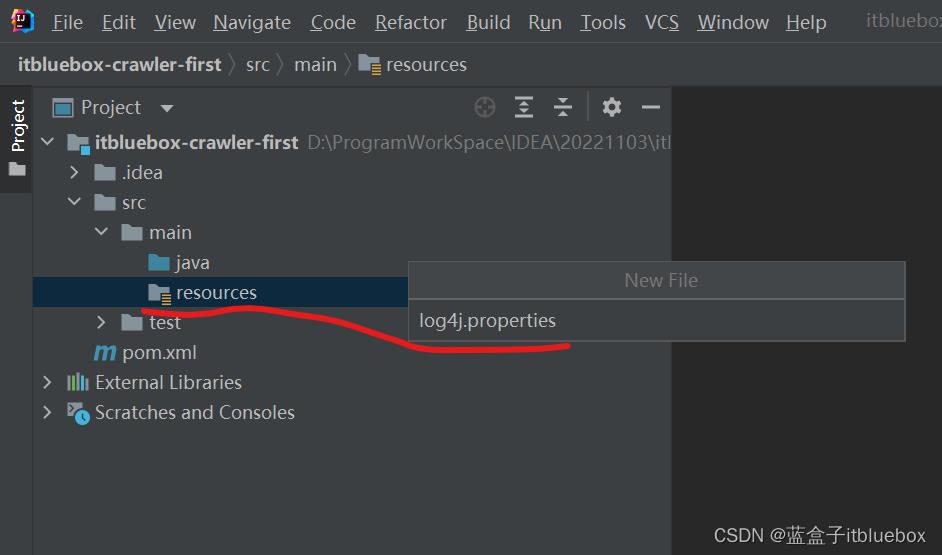
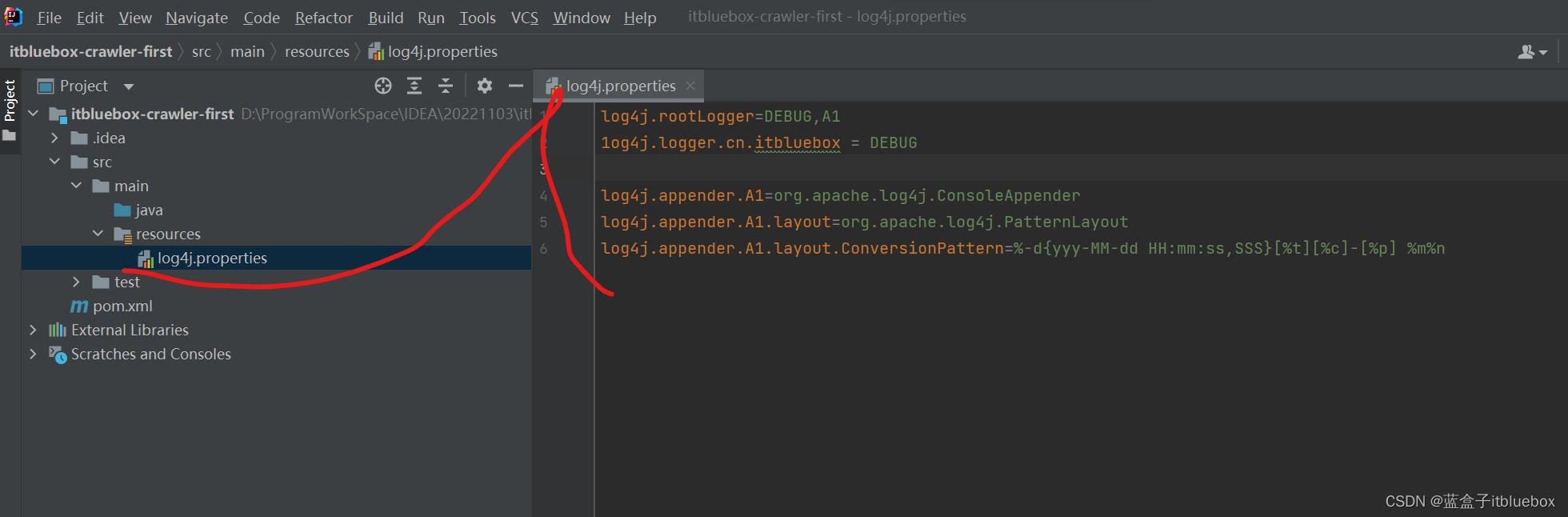
log4j.rootLogger=DEBUG,A1
1og4j.logger.cn.itbluebox = DEBUG
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-dyyy-MM-dd HH:mm:ss,SSS[%t][%c]-[%p] %m%n
3、使用httpclient爬取数据
这里我们爬取菜鸟教程的内容
完善:
CrawlerFirst
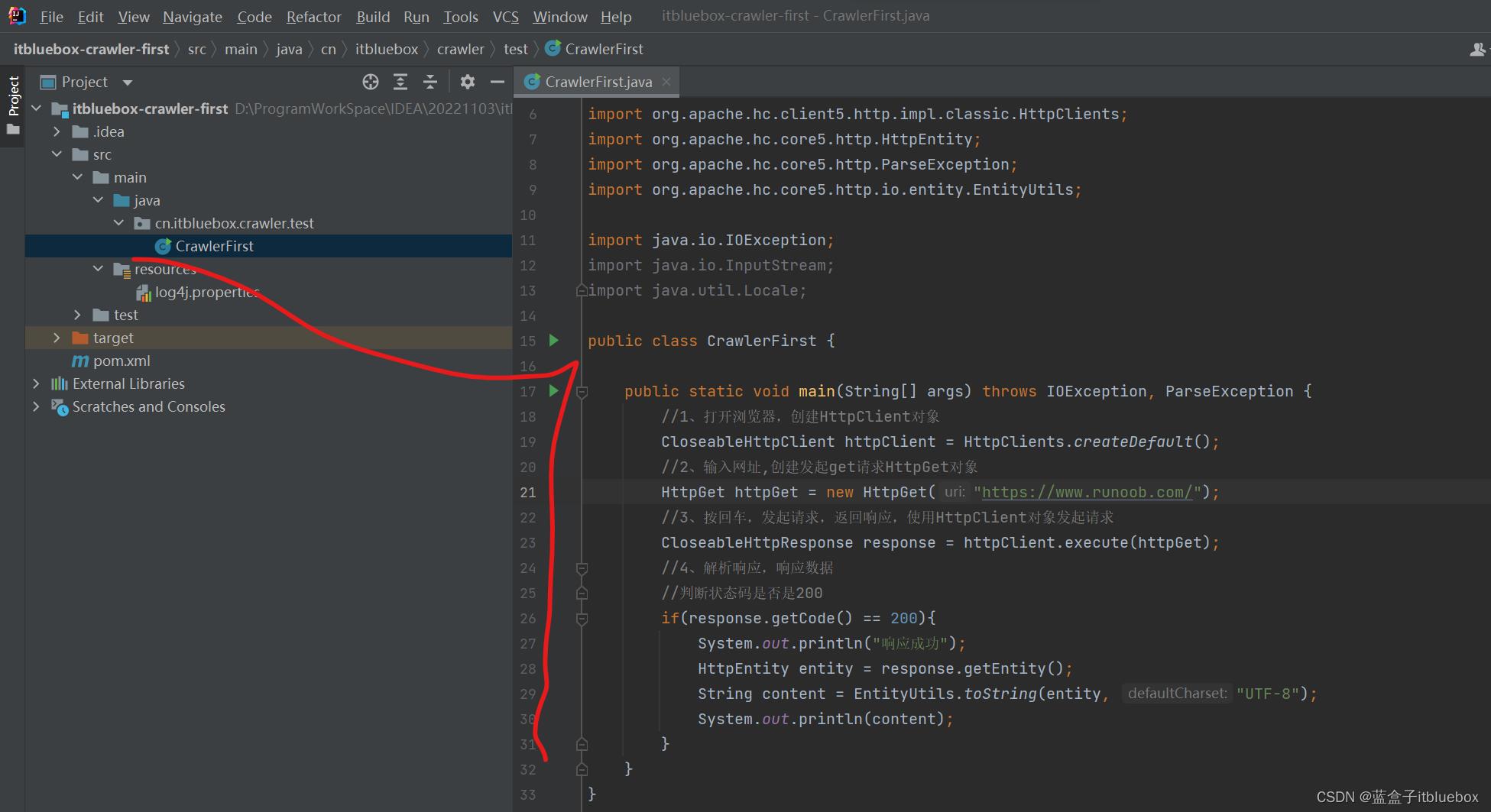
public class CrawlerFirst
public static void main(String[] args) throws IOException, ParseException
//1、打开浏览器,创建HttpClient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
//2、输入网址,创建发起get请求HttpGet对象
HttpGet httpGet = new HttpGet("网站地址");
//3、按回车,发起请求,返回响应,使用HttpClient对象发起请求
CloseableHttpResponse response = httpClient.execute(httpGet);
//4、解析响应,响应数据
//判断状态码是否是200
if(response.getCode() == 200)
System.out.println("响应成功");
HttpEntity entity = response.getEntity();
String content = EntityUtils.toString(entity, "UTF-8");
System.out.println(content);
运行测试

获得响应的内容

二、更多教程(因为CSDN的限制更多内容请看)
https://gitee.com/itbluebox/java-crawler-tutorial
以上是关于精通系列-案例开发-巨细HttpClient5 + jsoup + WebMagic + spider-flow万字长文一篇文章学会的主要内容,如果未能解决你的问题,请参考以下文章