Elasticsearch最佳实践之使用场景
Posted Mr-Bruce
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch最佳实践之使用场景相关的知识,希望对你有一定的参考价值。
序
最开始使用Elasticsearch是两年多前,在一家创业公司负责数据系统的建设,当时也有写一些博文来分享使用方法。然而回过头去想,觉得当时的很多认知不够深入,或者说是当时的业务场景下没有遇到更多的问题。很多时候,一个技术或工具,只有在更复杂的业务场景和更大的数据量下经历实践,才能有更深的体会与认识。
过去一段时间,有幸在项目中继续实践Elasticsearch,从设计、研发到调优,逐渐对Elasticsearch有了些新的认知与心得,因此计划撰写一个专栏来较系统的整理一下。也许,一段时间后,又会觉得这些认识不够深入,奈何这就是认知的过程。
对于Elasticsearch的实践,主要分为两块:应用层面的研发和集群的运维,本专栏侧重于前者。计划撰写5篇左右:
- 使用场景,探讨几种常见的业务场景,以及集群建设的选择
- 核心概念与原理,以图文形式整理出核心的概念与原理
- Index与Shard设计,分享如何结合业务来设计Index和合理分配Shard
- 项目应用,分享Elasticsearch在笔者项目中的实践
- 性能调优,分享数据写入与查询过程的性能调优方法
需要首先指出的是,本专栏所使用的Elasticsearch版本是5.5。
正文
作为专栏的第一篇,本文将尝试从两个角度来探讨一下当前Elasticsearch的使用场景。一个是常见的业务场景,目的在于让大家能够感性的认识到Elasticsearch可以做什么。在遇到类似业务场景时,可以想到Elasticsearch,用其形成解决方案或者作为评估对象之一。另一个是集群建设方面,探讨的问题是:自己搭建Elasticsearch集群还是使用云服务。
常见的业务场景
下图是官方的定位,Elasticsearch的核心特征是数据搜索与分析。与这两个特征相关的需求都可以考虑使用Elasticsearch,其本身是单纯的,复杂的是具体业务。在不同的业务中,Elasticsearch扮演着不同的角色,也有着不同的实践和优化方法。归纳起来,目前主要有三类常见的业务场景,笔者将逐一分析。
- ELK日志系统
- 数据聚合分析
- 业务内搜索

ELK日志系统
大概很多互联网的朋友接触Elasticsearch都是从ELK开始的,用来解决Log的集中式管理问题。这样的需求来自于互联网的快速发展,出现越来越多的集群部署与分布式系统,导致服务产生的Log信息分散在不同的机器上,无法有效的检索与统计。以下面的应用服务集群为例,为了做集中式Log管理,需要有一个Agent负责从每台机器收集信息,送到一个存储系统集中存储(该系统需要具备快速的文本搜索功能),然后通过一个可视化UI来查看和分析信息。

ELK以全家桶的形式为这一问题提供了解决方案,Logstash负责收集、解析数据,Elasticsearch负责存储、检索数据,Kibana提供可视化功能。笔者曾在创业公司做数据分析(四)ELK日志系统一文介绍过相关的使用方法。
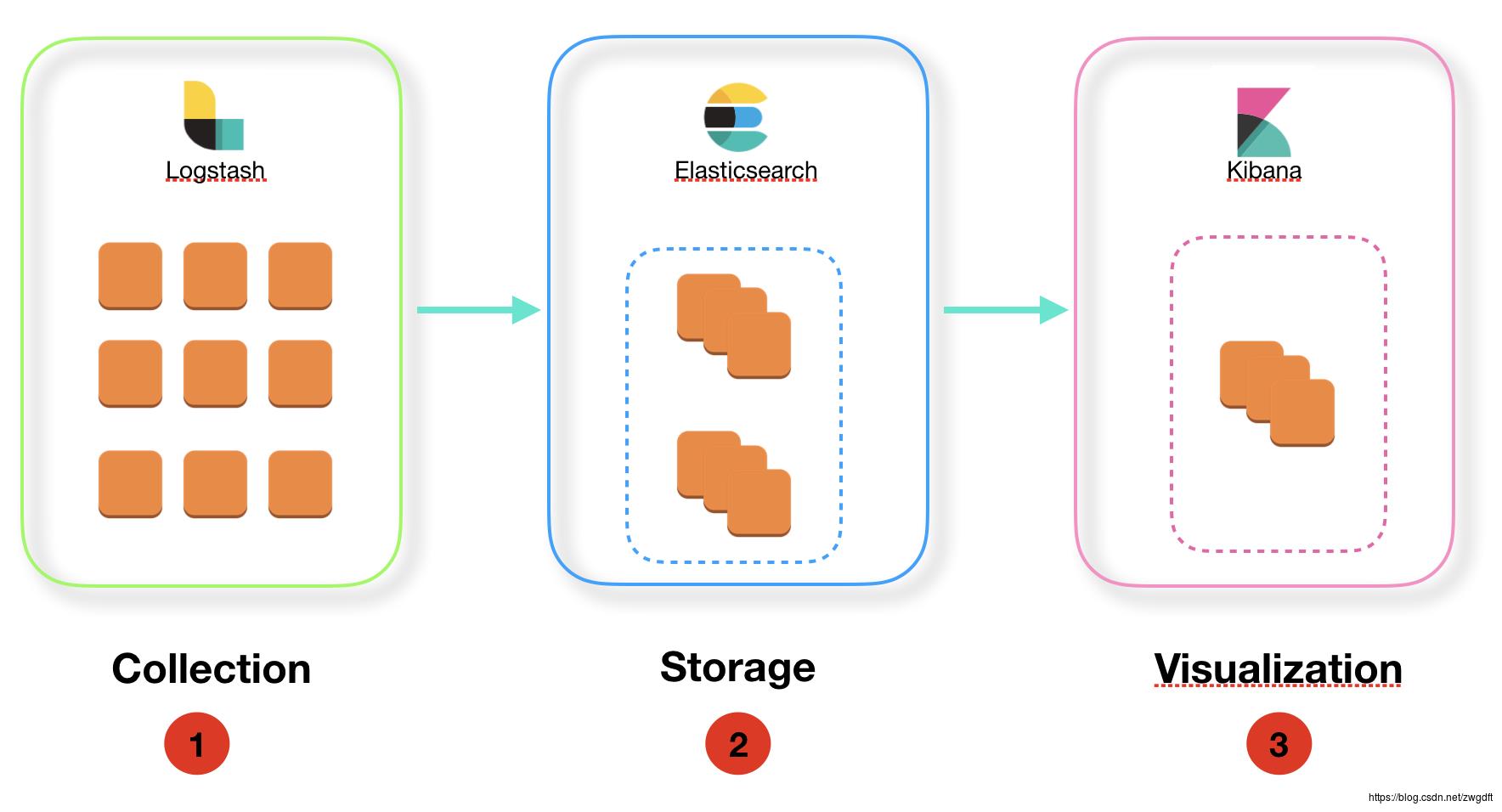
当然,这并不意味着ELK必须捆绑使用。一方面,Logstash是基于JRuby编写,在部署和性能上的表现并不能满足所有需求,所以很多人会将其替换为自己编写的数据采集工具。同时Elastic官方也有提供Beats相关轻量级组件,可与Logstash组合使用。另一方面,也有很多人在Kibana的基础上做二次开发,来增强相应的查询功能,集成开源的告警功能等。但是Elasticsearch始终是核心组件,很少有人将其替换掉,源于其强大的搜索功能恰好满足Log的检索需求。有一点建议是,ELK本身已经很好使用,除非有强烈的业务需求,否则没有必要刻意去替换,先考虑用对、用好它。
数据聚合分析
数据的维度统计查询,是当前数据业务的一个主要需求。其配合相应的可视化UI可以帮助用户直观的获取信息、做出决策等。比如,针对网络流量数据,查看上班时间段,员工访问视频类网站的流量占比。
这样的统计查询基本可以归纳为:按照某些条件过滤 --> 针对某个维度分组 --> 统计数据(Sum/Count)。在海量数据下,如何实现快速查询?(亿级以上数据量,秒级查询)

首先,诸如mysql这类关系型数据基本是无法胜任的,其无法突破单机的存储和处理能力限制,而引入分片又会带来应用层面的复杂度。其次,面对这样的海量数据,通常有两个思路:一个是根据需求,制定相应的预计算方案,通过ETL来提前算好相关的统计数据,但是不能很好的应对未知的维度数据。另一个就是不做预计算,Elasticsearch便是其中一个选择,其他方案还有Presto/Spark SQL这样基于内存的Map/Reduce计算框架等。
Elasticsearch强大的搜索与分析聚合能力使其可以很好的适用于这一业务场景。以笔者当前的项目来看,百亿级数据可以做到秒级查询。另外,Elasticsearch的一些特性,诸如alias等可以很好的帮助我们完成一些业务逻辑。
当然,任何事情都不是完美的,选择Elasticsearch得有两个前提:第一,受限于其工作机制,聚合结果可能存在较小的偏差的;第二,数据需要规划好,保持扁平结构,不能有JOIN的需求。
业务内搜索
现如今,搜索功能几乎是互联网产品的标配,用于帮助用户快速在产品中找到所需的信息。笔者将这样一类需求定义为业务内搜索,其特性是在业务范围内提供搜索功能。比如下图中的食谱类App,只需要支持对菜谱、食材这些业务内容进行搜索,而无需关注其他信息。
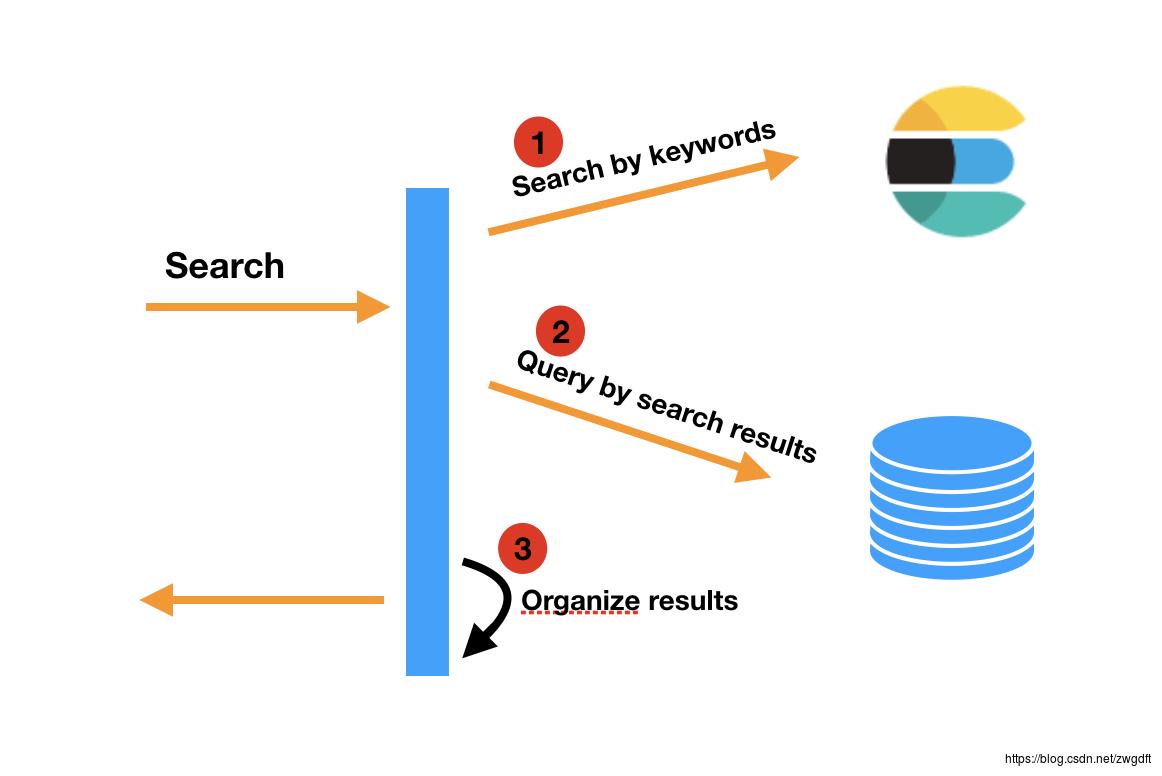
基于Elasticsearch,可以快速构建这样的搜索功能。通常是采用DB与Elasticsearch配合的方案,DB负责数据存储,Elasticsearch负责关键词检索。Elasticsearch可以在多维度上检索与关键词相关的数据,并为每个匹配结果生成一个相关度分数。当服务收到搜索请求时,首先根据关键词到Elasticsearch中进行检索,然后根据检索结果去DB中查询信息,并在应用层进行数据整理和排序。
搜索精度的调优是重点,也是最难的一部分。比如,如何建立业务内容的词库,如何进行合理分词建立索引,如何调整搜索权重等等。笔者曾经在做搜书系统(打造私人搜书系统之系统设计)时有过相关的简单实践,抽空会继续将其整理出来。
集群建设的选择
伴随着云服务的发展,Elasticsearch集群的建设出现了以下三种选择:
- 在自有的服务器上构建Elasticsearch集群,自己运维
- 在云厂商提供的EC2机器上构建Elasticsearch集群,自己运维
- 使用云厂商提供的Elasticsearch云服务构建Elasticsearch集群
第一种选择以大公司为主,多以平台的形式为整个公司提供服务;后面两种主要面向中小型企业,多以产品为导向,即每个产品维护自己的集群。对于第二种选择,通常是需要构建稳定运行的Elasticsearch集群,由专业的运维人员负责管理。而第三种选择,通常是企业需要构建稳定运行的Elasticsearch集群,并希望将更多的人力、物力放到业务层面而非集群运维上面。随着Elasticsearch云服务的成熟,越来越多处于第二种选择的企业开始考虑或正在迁移。
Elasticsearch云服务可帮助企业更好的做集群扩展,解放运维,把关注点放到业务层面。以AWS Elasticsearch云服务为例,它可以帮助用户实现没有downtime的扩展、版本升级等。目前,提供相关服务的有AWS、阿里云、Elastic官方等等。当然,任何事情都有两面性,在方便的同时也会带来不方便,比如无法触及到机器导致一些调优方案无法实施。
其实,究竟应该如何选择,更多是由一个企业所处的行业、企业战略以及历史背景来决定。
不同的业务场景,加上不同的集群构建方法,就会导致在使用Elasticsearch时的侧重点不同,相关设计与优化的方法也会有所不同。笔者当前项目是采用AWS Elasticsearch云服务构建,针对大数据聚合分析的业务场景,所以,在后面的博文中,会侧重于这方面。
(全文完,本文地址:https://blog.csdn.net/zwgdft/article/details/82917861 )
(版权声明:本人拒绝不规范转载,所有转载需征得本人同意,并且不得更改文字与图片内容。大家相互尊重,谢谢!)
Bruce
2018/10/08 晚
以上是关于Elasticsearch最佳实践之使用场景的主要内容,如果未能解决你的问题,请参考以下文章