kotlin修炼指南9-Sequence的秘密
Posted eclipse_xu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kotlin修炼指南9-Sequence的秘密相关的知识,希望对你有一定的参考价值。

点击上方蓝字关注我,知识会给你力量

人们经常忽略Iterable和Sequence之间的区别。这是可以理解的,因为即使它们的定义也几乎是相同的。
interface Iterable<out T>
operator fun iterator(): Iterator<T>
interface Sequence<out T>
operator fun iterator(): Iterator<T>
你可以说它们之间唯一的正式区别就是名字。尽管Iterable和Sequence有着完全不同的用途(有不同的契约),它们的处理函数几乎都以不同的方式工作。Sequence是Lazy的,所以Sequence处理的中间函数不做任何计算。相反,它们返回一个新的Sequence,用新的操作来装饰以前的Sequence。所有这些计算在终端操作(如toList或count)中被处理。而另一方面,Iterable的处理在每一步都会返回一个类似List的集合。
public inline fun <T> Iterable<T>.filter(
predicate: (T) -> Boolean
): List<T>
return filterTo(ArrayList<T>(), predicate)
public fun <T> Sequence<T>.filter(
predicate: (T) -> Boolean
): Sequence<T>
return FilteringSequence(this, true, predicate)
❝Sequence过滤器是一个中间操作,所以它不做任何计算,而是用新的处理步骤来装饰Sequence。计算是在终端操作中完成的,比如toList。
❞
因此,集合处理操作一旦被使用就会被调用。Sequence处理函数直到终端操作(一个返回其他东西而不是Sequence的操作)才会被调用。例如,对于Sequence来说,filter是一个中间操作,所以它不做任何计算,而是用新的处理步骤来装饰Sequence。计算是在toList这样的终端操作中完成的。

val seq = sequenceOf(1,2,3)
val filtered = seq.filter print("f$it "); it % 2 == 1
println(filtered) // FilteringSequence@...val asList = filtered.toList() // f1 f2 f3
println(asList) // [1, 3]val list = listOf(1,2,3)
val listFiltered = list
.filter print("f$it "); it % 2 == 1 // f1 f2 f3
println(listFiltered) // [1, 3]在Kotlin中,Sequence是Lazy的,这有几个重要的优点。
它们保持了操作的自然顺序
它们只做最少的操作
它们可以是无限的
它们不需要在每个步骤中都创建集合
让我们来逐一讨论这些优点。
Order is important
由于iterable和Sequence处理的实现方式,它们的操作顺序是不同的。在Sequence处理中,我们取第一个元素并应用所有的操作,然后我们取下一个元素,以此类推。我们将其称为逐个元素或Lazy的顺序。在可迭代处理中,我们取第一个操作,并将其应用于整个集合,然后转到下一个操作。他们是一步一步被执行的。
sequenceOf(1,2,3)
.filter print("F$it, "); it % 2 == 1
.map print("M$it, "); it * 2
.forEach print("E$it, ") // Prints: F1, M1, E2, F2, F3, M3, E6,listOf(1,2,3)
.filter print("F$it, "); it % 2 == 1
.map print("M$it, "); it * 2
.forEach print("E$it, ") // Prints: F1, F2, F3, M1, M3, E2, E6,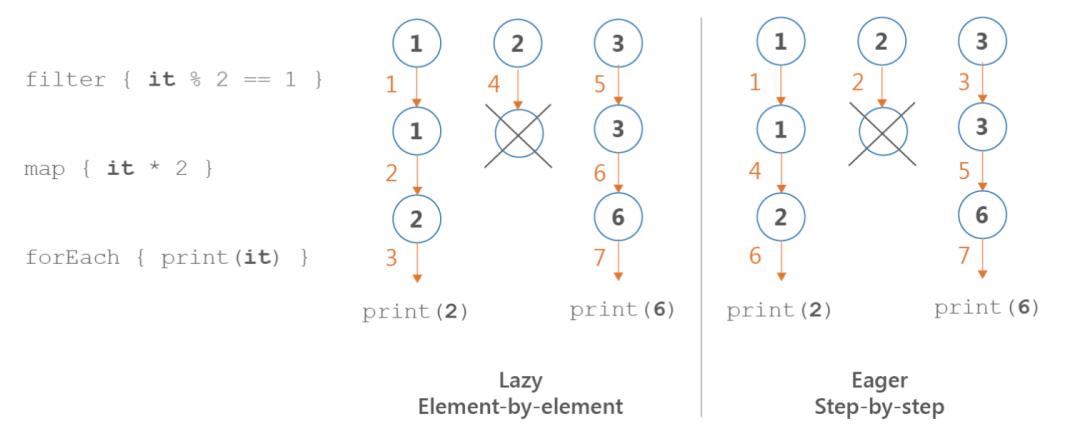
请注意,如果我们不使用任何集合处理函数来实现这些操作,而是使用经典的循环和条件,我们就会像在Sequence处理中一样是逐个元素的顺序。
for (e in listOf(1,2,3))
print("F$e, ")
if(e % 2 == 1)
print("M$e, ")
val mapped = e * 2
print("E$mapped, ")
// Prints: F1, M1, E2, F2, F3, M3, E6,因此,在Sequence处理中使用的逐个元素的顺序是比较自然的。它还为低级别的编译器优化打开了大门--Sequence处理可以被优化为基本的循环和条件。也许在未来,它将是这样。
Sequences do the minimal number of operations
通常我们不需要在每一步都处理整个集合来产生结果。比方说,我们有一个有数百万个元素的集合,在处理之后,我们只需要取前10个。为什么要处理其他所有的元素呢?Iterable处理没有中间操作的概念,所以整个集合的处理就像在每个操作上都要返回一样。Sequence不需要这样,所以它们会做最小数量的操作来获得结果。
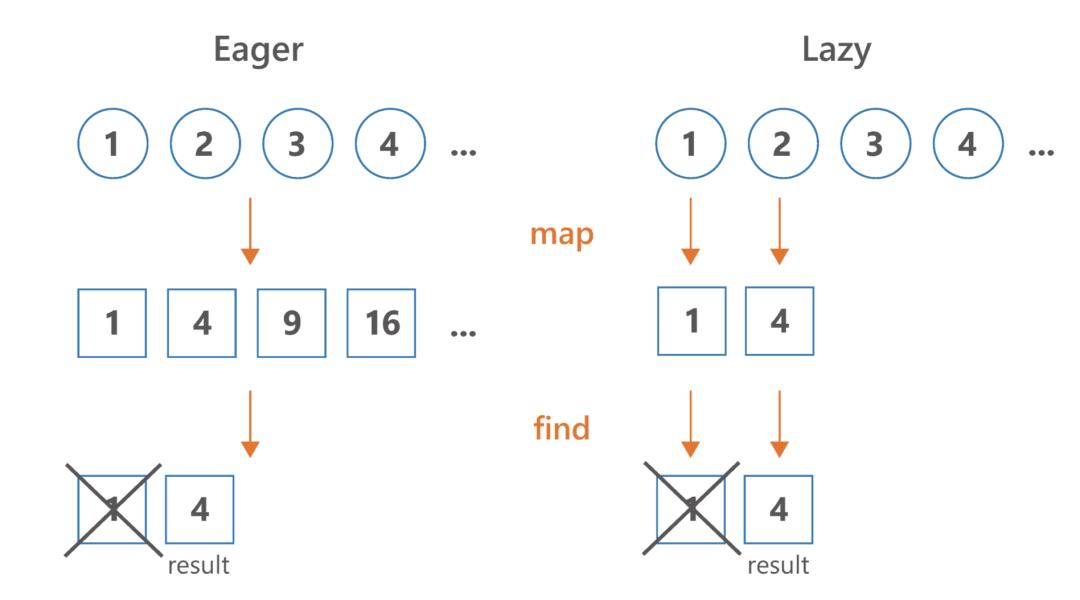
看一下这个例子,我们有几个处理步骤,我们用find来结束我们的处理。
(1..10).asSequence()
.filter print("F$it, "); it % 2 == 1
.map print("M$it, "); it * 2
.find it > 5
// Prints: F1, M1, F2, F3, M3,(1..10)
.filter print("F$it, "); it % 2 == 1
.map print("M$it, "); it * 2
.find it > 5
// Prints: F1, F2, F3, F4, F5, F6, F7, F8, F9, F10, M1, M3, M5, M7, M9,出于这个原因,当我们有一些中间处理步骤,并且我们的终端操作不一定需要遍历所有的元素时,使用一个Sequence很可能对你的处理性能更好。所有这些,同时看起来与标准的集合处理几乎一样。这类操作的例子有first, find, take, any, all, none或indexOf等。
Sequences can be infinite
由于Sequence是按需进行处理的,我们可以有无限的Sequence。创建一个无限Sequence的典型方法是使用Sequence生成器,如generateSequence或sequence。第一个生成器需要第一个元素和一个指定如何计算下一个元素的函数。
generateSequence(1) it + 1
.map it * 2
.take(10)
.forEach print("$it, ")
// Prints: 2, 4, 6, 8, 10, 12, 14, 16, 18, 20,第二个提到的Sequence生成器--sequence--使用一个suspend函数(coroutine),按要求生成下一个数字。每当我们要求下一个数字时,Sequence生成器就会运行,直到使用yield产生一个值。然后停止执行,直到我们要求得到另一个数字。下面是一个无限的下一个斐波那契数字的列表。
val fibonacci = sequence
yield(1)
var current = 1
var prev = 1
while (true)
yield(current)
val temp = prev
prev = current
current += temp
print(fibonacci.take(10).toList())
// [1, 1, 2, 3, 5, 8, 13, 21, 34, 55]请注意,无限Sequence在某些时候需要有有限的元素数量。我们不能在无穷大上迭代。
print(fibonacci.toList()) // Runs forever因此,我们要么需要使用像take这样的操作来限制它们,要么需要使用一个不需要所有元素的终端操作,比如first、find、any、all、none或indexOf。基本上,这些都是Sequence更有效的操作,因为它们不需要处理所有元素。尽管注意到对于大多数这些操作来说,很容易陷入无限循环。any操作符只能返回true或者永远运行。同样,all和none操作符在一个无限的集合上也只能返回false。因此,我们通常要么通过take来限制元素的数量,要么就用first来要求第一个元素。
Sequences do not create collections at every processing step
标准的集合处理函数在每一步都会返回一个新的集合。大多数情况下,它是一个列表。这可能是一个优势--在每一个点之后,我们都有一些准备好的东西可以使用或存储。但它也是有代价的。这样的集合在每一步都需要被创建并填充数据。
numbers
.filter it % 10 == 0 // 1 collection here
.map it * 2 // 1 collection here
.sum()
// In total, 2 collections created under the hoodnumbers
.asSequence()
.filter it % 10 == 0
.map it * 2
.sum()
// No collections created这是个问题,特别是当我们处理大的或重的集合时。让我们从一个极端但又常见的案例开始:文件读取。文件可以达到数千兆字节。在每个处理步骤中分配一个集合中的所有数据将是对内存的巨大浪费。这就是为什么我们默认使用Sequence来处理文件。
作为一个例子,让我们分析一下芝加哥市的犯罪。这个城市和其他许多城市一样,在互联网上分享了自2001年以来发生在那里的全部犯罪数据库(你可以在www.data.cityofchicago.org找到这些记录)。这个数据集目前的Size超过1.53GB。比方说,我们的任务是找出有多少犯罪行为的描述中有大麻。下面就是一个使用集合处理的天真解决方案的样子(readLines返回List)。
// BAD SOLUTION, DO NOT USE COLLECTIONS FOR
// POSSIBLY BIG FILES
File("ChicagoCrimes.csv").readLines()
.drop(1) // Drop descriptions of the columns
.mapNotNull it.split(",").getOrNull(6)
// Find description
.filter "CANNABIS" in it
.count()
.let(::println)我的电脑上的结果是OutOfMemoryError。
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space不难理解为什么。我们创建了一个集合,然后我们有3个中间处理步骤,加起来有4个集合。其中3个包含了这个数据文件的大部分,需要1.53GB,所以它们都需要消耗超过4.59GB。这是对内存的巨大浪费。正确的实现应该是使用一个Sequence,我们使用函数useLines来实现,它总是在一个单行上操作。
File("ChicagoCrimes.csv").useLines lines ->
// The type of `lines` is Sequence<String>
lines
.drop(1) // Drop descriptions of the columns
.mapNotNull it.split(",").getOrNull(6)
// Find description
.filter "CANNABIS" in it
.count()
.let println(it) // 318185在我的电脑上,这需要8.3秒。为了比较这两种方法的效率,我又做了一个实验,我通过删除不需要的列来减少这个数据集的大小。这样我就得到了CrimeData.csv文件,其中包含了同样的罪行,但大小只有728MB。然后我做了同样的处理。在第一个实现中,使用集合处理,大约需要13秒;而第二个实现中,使用Sequence,大约需要4.5秒。正如你所看到的,对较大的文件使用Sequence,不仅是为了内存,也是为了性能。
虽然一个集合不需要很重。事实上,每一步我们都在创建一个新的集合,这本身也是一种成本,当我们处理具有较大数量元素的集合时,这种成本就会体现出来。差别并不是非常巨大的原因是--主要是因为经过许多步骤创建的集合被初始化为预期的大小,所以当我们添加元素时,只是把它们放在下一个位置。但这种差异仍然是不可忽视的,这也是为什么我们更愿意使用Sequence来处理超过一个处理步骤的大集合的主要原因。
我所说的 "大集合 "是指许多元素和真正的大集合。它可能是一个有几万个元素的整数列表。它也可能是一个只有几个字符串的列表,但每个字符串都很长,以至于它们都需要很多兆字节的数据。这些情况并不常见,但它们有时会发生。
我所说的一个处理步骤,是指超过一个函数的集合处理。因此,如果你比较这两个函数。
fun singleStepListProcessing(): List<Product>
return productsList.filter it.bought
fun singleStepSequenceProcessing(): List<Product>
return productsList.asSequence()
.filter it.bought
.toList()
你会注意到在性能上几乎没有差别(实际上简单的列表处理更快,因为它的过滤功能是内联的)。尽管当你比较有多个处理步骤的函数时,比如下面的函数,它使用了过滤器,然后是Map,对于更大的集合来说,差异将是可见的。为了看到区别,让我们比较一下5000个产品的典型处理,有两个和三个处理步骤。
fun twoStepListProcessing(): List<Double>
return productsList
.filter it.bought
.map it.price
fun twoStepSequenceProcessing(): List<Double>
return productsList.asSequence()
.filter it.bought
.map it.price
.toList()
fun threeStepListProcessing(): Double
return productsList
.filter it.bought
.map it.price
.average()
fun threeStepSequenceProcessing(): Double
return productsList.asSequence()
.filter it.bought
.map it.price
.average()
下面你可以看到在MacBook Pro(处理器2.6 GHz Intel Core i7,内存16 GB 1600 MHz DDR3)上对产品清单中5000个产品的平均结果。
twoStepListProcessing 81 095 ns
twoStepSequenceProcessing 55 685 ns
twoStepListProcessingAndAcumulate 83 307 ns
twoStepSequenceProcessingAndAcumulate 6 928 ns很难预测我们应该期待什么样的性能改进。根据我的观察,在一个典型的有多个步骤的集合处理中,对于至少几千个元素,我们可以期望有20-40%左右的性能改进。
When aren’t sequences faster?
有一些操作我们不能从这种Sequence的使用中获益,因为我们必须对整个集合进行操作,sorted是Kotlin stdlib中的一个例子(目前是唯一的例子)。sorted使用了最佳实现。它将Sequence累积到List中,然后使用Java stdlib中的sort。缺点是,如果我们将其与在一个集合上的相同处理进行比较,这个积累过程需要一些额外的时间(尽管如果Iterable不是一个集合或数组,那么区别并不明显,因为它也需要进行积累)。
Sequence是否应该有sorted这样的方法是有争议的,因为Sequence流式的操作符中,只是部分操作符是Lazy的(当我们需要得到第一个元素时才进行计算),并且在无限的Sequence上不起作用。添加它是因为它是一个流行的函数,而且这样使用它要容易得多。尽管Kotlin开发者应该记住它的缺陷,特别是它不能用于无限Sequence。
generateSequence(0) it + 1 .take(10).sorted().toList()
// [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
generateSequence(0) it + 1 .sorted().take(10).toList()
// Infinite time. Does not return.sorted是一个罕见的处理例子,它在Collection上比在Sequence上快。尽管如此,当我们做一些处理步骤和单一的排序函数(或其他需要在整个集合上工作的函数)时,我们可以期望使用Sequence处理来提高性能。
// Benchmarking measurement result: 150 482 ns
fun productsSortAndProcessingList(): Double
return productsList
.sortedBy it.price
.filter it.bought
.map it.price
.average()
// Benchmarking measurement result: 96 811 ns
fun productsSortAndProcessingSequence(): Double
return productsList.asSequence()
.sortedBy it.price
.filter it.bought
.map it.price
.average()
What about Java stream?
Java 8引入了流,允许集合处理。它们的行为和代码外观类似于Kotlin的Sequence。
productsList.asSequence()
.filter it.bought
.map it.price
.average()productsList.stream()
.filter it.bought
.mapToDouble it.price
.average()
.orElse(0.0)Java 8的流是Lazy的,在最后一个(终端)处理步骤中开始计算。Java流和KotlinSequence的三大区别如下。
KotlinSequence有更多的处理函数(因为它们被定义为扩展函数),它们通常更容易使用(这是由于KotlinSequence是在Java streams已经被使用时设计的--例如,我们可以使用toList()来收集,而不是collectors.toList())。
Java流处理可以使用并行函数以并行模式启动。当我们的机器有多个经常未使用的内核时(这在现在很常见),这可以给我们带来巨大的性能提升。虽然要谨慎使用,因为这个功能有已知的隐患(问题来自于他们使用的常见的连接-分叉线程池。因为,一个Task可能会阻塞另一个Task。还有一个问题是单元素处理会阻塞其他元素。在此阅读更多信息:https://dzone.com/articles/think-twice-using-java-8)。
KotlinSequence可以在普通模块、Kotlin/JVM、Kotlin/JS和Kotlin/Native模块中使用。Java流只在Kotlin/JVM中使用,而且只在JVM版本至少为8时使用。
一般来说,当我们不使用并行模式时,很难给出一个简单的答案,Java流和KotlinSequence哪个更有效。我的建议是很少使用Java流,只在计算量大的处理中使用,这样可以从并行模式中获益。否则,使用Kotlin stdlib函数,以获得同质化的、干净的代码,可以在不同的平台上或共同的模块上使用。
Kotlin Sequence debugging
Kotlin Sequence和Java Stream都有支持,可以帮助我们在每一步调试元素流。对于Java Stream,它需要一个名为 "Java Stream Debugger "的插件。KotlinSequence也需要名为 "Kotlin Sequence Debugger "的插件,不过现在这个功能已经集成到Kotlin插件中了。下面是一个显示Sequence处理的每一步的屏幕。
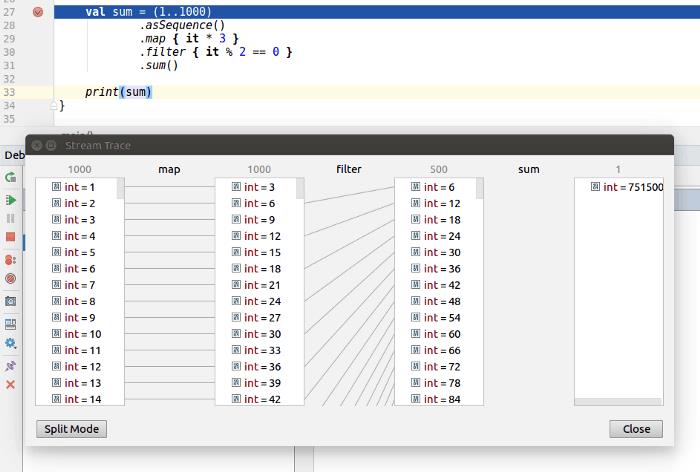
Summary
Collection和Sequence的处理非常相似,都支持几乎相同的处理方法。然而这两者之间有重要的区别。Sequence处理更复杂,所以我们通常将元素保存在集合中,然后转换集合为Sequence,最后往往还需要回到所需的集合。但Sequence是Lazy的,这带来了一些重要的优势。
它们保持操作的自然顺序
它们只做最少的操作
它们可以是无限的
它们不需要在每一步都创建集合
因此,它们更适合于处理大尺寸的对象或具有多个处理步骤的大型集合。Sequence也得到了KotlinSequence调试器的支持,它可以帮助我们直观地看到元素的处理情况。Sequence不能取代经典的集合处理。你应该只在有充分理由的情况下使用它们,而且你会得到显著的性能优化的回报。
原文翻译自 https://blog.kotlin-academy.com/effective-kotlin-use-sequence-for-bigger-collections-with-more-than-one-processing-step-649a15bb4bf
向大家推荐下我的网站 https://xuyisheng.top/ 点击原文一键直达
专注 android-Kotlin-Flutter 欢迎大家访问
往期推荐
本文原创公众号:群英传,授权转载请联系微信(Tomcat_xu),授权后,请在原创发表24小时后转载。
< END >
作者:徐宜生
更文不易,点个“三连”支持一下👇
以上是关于kotlin修炼指南9-Sequence的秘密的主要内容,如果未能解决你的问题,请参考以下文章