MySQL数据库系列二MySQL数据库增删改查(聚合查询多表查询)
Posted 飞人01_01
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL数据库系列二MySQL数据库增删改查(聚合查询多表查询)相关的知识,希望对你有一定的参考价值。
上次我们讲了数据库的创建和删除,还有一些没讲完的限制,本文我们就一起讲了,然后开始讲数据库的增删改查操作,涉及到基本的增删改查和聚合查询、多表查询等。都算是比较难的知识点,多敲敲代码。
前期文章:【MySQL数据库系列】一、认识数据库、建库建表操作
{kind=link}
文章目录
补充上一篇文章的部分内容
上一篇文章我们讲了如何进行新建数据库,删除数据库,新建表,删除表:
show databases;
drop database 数据库名;
create table 表名(列名 数据类型);
drop table 表名;
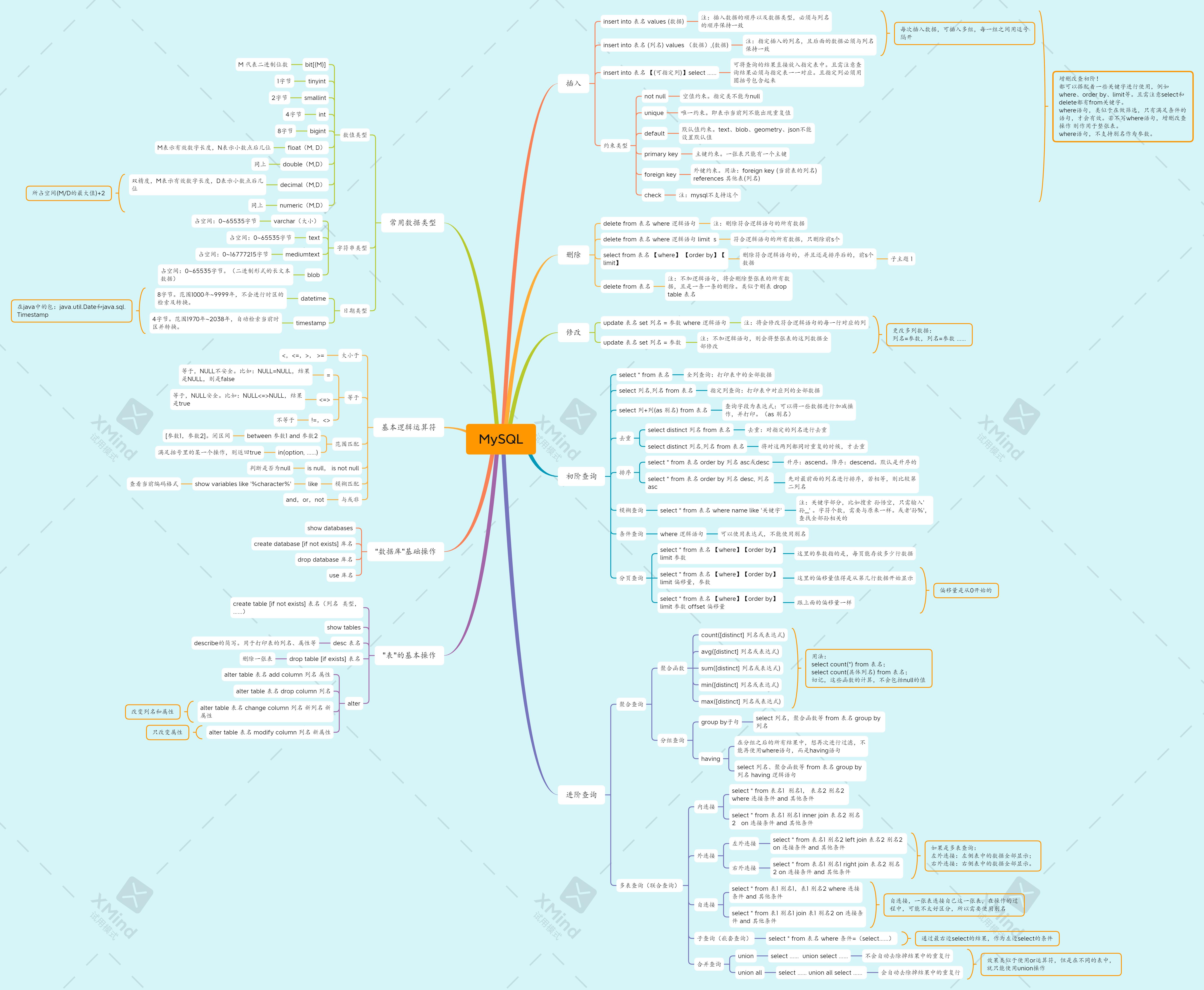
唯一需要补充一点就是在建表的时候,可以添加一些约束类型:
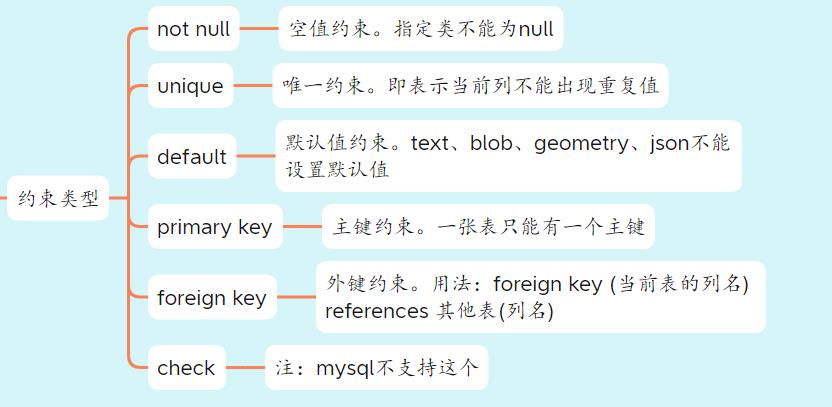
-
not null: 表示当前列的输入参数不能是空的或null。
-
unique:这个关键字会限制当前列的数据,不能出现重复值。
-
default:设置当前列的默认值。
-
primary key:主键约束。就类似于每个人都有一个身份证号,一张表只能有一个主键。(后面添加参数:auto_increment,表示自增主键)。
-
foreign key:外键约束。功能:当前表的某一列的所有参数,都来自于另外一张表的某一列。简单的说就是这一张表的某一列的所有数据,都必须是包含于另外一张表某一列的数据。二者属于子集关系:当前表某一列 是 另外一张表某一列的子集。(注意一下代码的两个圆括号不能省略)
foreign key (当前表的列名) references 其他表名(列名); -
check:用于检查当前列的输入参数,比如输入性别时,只能是男生或者女生,就可以使用这个约束。(mysql不支持这个约束类型)

以上的代码就演示了这个约束类型的使用,除了外键约束是写在最后一行外,其他的约束都是在列名的后面进行书写。
一、插入操作
在建表之后,我们就可以向表中插入一些数据,通查的插入方法有以下两种:
insert into 表名 values (数据);
insert into 表名(列名) values (数据),(数据);
以上两行代码中:
第一行的代码插入的是当前表中的每一列的数据。简单来说:假设当前表有5列,那么后面圆括号里面的数据必须是5个参数,且按照从左到右的顺序,第一个参数插入第一列,第二个参数插入第二列……
第二行的代码插入的是具体某一列的数据。也就是说,指定某一列或多列,进行插入,插入顺序也是必须从左到右的顺序。
然后还有一个点就是,可以一条SQL语句插入多行数据,比如上面的第二行代码,有两个圆括号的数据,这两个圆括号之间用逗号隔开。
还有一种插入方式,了解即可!!!
insert into 表名 select ……
这一行代码的意思就是,将select查询的结果,放入另外一张表中,但是值得注意的是,select返回来的数据可能有多列,在插入的时候,也必须指定插入到当前表的哪些列。
这个了解即可,知道有这个东西即可。
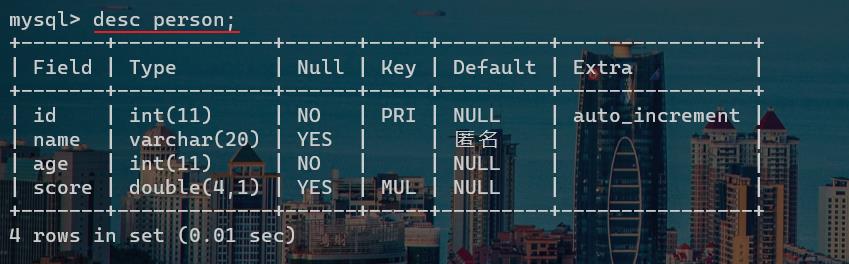
注意:在插入数据的时候,要了解当前表每一列的数据类型以及是否存在一些约束类型,不然在插入的时候,会出一些错误。可以使用describe来查看当前表结构,提前了解当前表的情况
describe 表名;
desc 表名;
以上两行的代码都可以用来查看表的结构,显示结果如下:
二、查询操作
1、全列查询
查询语句是:select …… from ……。
select 后面指定的是哪些列是需要被查询,from后面是指定查询哪一张表。
select * from 表名;
用“*”号表示,查询当前表的全部列,也就是全列。

2、指定列查询
指定某一列进行查询:
select 列名,列名 from 表名;
可以指定多列,进行查询操作。
3、表达式查询
可以以表达式的形式,来计算某一列的值,比如计算一个学生的语文、数学、英语的总成绩,则可以使用一下代码:
select name,chinese+math+english from student;
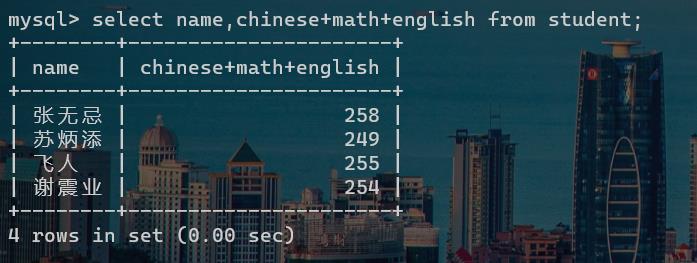
i后我们还可以给这个总成绩取别名,通过as来实现:
select name,chinese+math+english as sum from student;

4、去重
通过关键字distinct,可以对查询的列进行去重的效果:
select distinct 列名 from 表名;
select distinct 列名,列名 from 表名;
比如:select distinct math from student。这个代码会将表中所有的数据打印出来,假设有的同学的数学成绩相同,则只会打印最先遍历到的那个同学的数学成绩。
然后值得注意的是,第2行的代码,写了两列,这里记住,只有当这两列的数据都分别相同时,才会达到去重的效果。举个例子:小明的是数学成绩99,英语成绩89;小刘的数学成绩也是99,英语成绩也是89。此时这两位同学的数学和英语都同时相同,此时调用第2行的代码才能达到去重的效果。
5、排序(重点)
我们除了可以打印出查询的所有结果,也可以对查询的结果进行一个排序。
select * from 表名 order by 列名;
select * from 表名 order by 列名1 asc,列名2 desc;
order by,就是对数据进行排序。根据后面的列名来排序,而默认的是排升序。而到底是排升序还是降序,则是根据关键字:升序ascend,降序descend。
上面第2行代码,order by后面指定了两列,则排序规则是:先根据列名1进行排升序,假设某两行的这一列是相等的,则会根据列名2进行排降序。

6、条件查询(重点)
在上面的所有查询中,我们查询的都是表中全部数据,没有做任何筛选。其实在MySQL中,有一个做筛选的操作,也就是条件查询。满足条件的数据,才会被查询和打印出来。
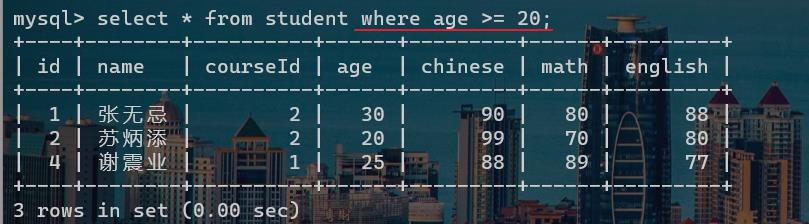
select * from 表名 where 条件;
where子句,写在表名的后面,这样写就是实现筛选操作。
这里的条件,就可以写上一篇文章中,给出的所有逻辑运算符。
特别注意:在前面我们只用order by的时候,可以使用一个别名来实现排序,但是where子句,不能使用别名来进行操作。
7、模糊查询
在生活中,我们也会看到一些模糊查询的场景,比如在网购时,记不清楚商品的名字,可以输入部分名字,来进行模糊匹配。
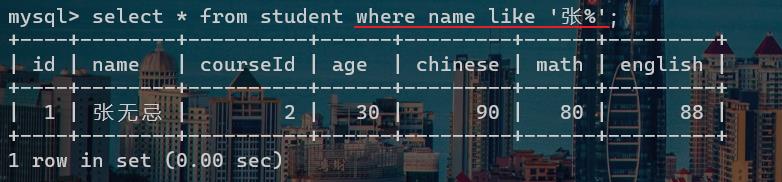
MySQL中,like关键字进行模糊匹配。
select * from 表名 where name like '张%';
select * from 表名 where name like '张_';
以上代码的意思就是,查找表中姓张的同学。
唯一需要记住的是这两个通配符:
- %,可以匹配任意多个任意字符。也就是不限字数。
- _,下划线,则是匹配一个任意字符。
8、分页查询
limit关键字,可以实现分页的操作。
select * from 表名 limit 参数;
select * from 表名 limit 参数1 offset 参数2;
上面两个代码,都能实现分页操作。区别就在于:
第一行代码,limit 后面的参数表示每一页最多有多少行数据。
第二行代码,多了一个offset关键字,意思就是:从参数2这一行开始打印输出,此处的参数2称为偏移量。偏移量是从0开始的,偏移量为0,在表中表示的是第一行的数据。
然后就是,表名和limit之间还可以加其他参数,比如where子句、order by排序。
select * from 表名 【where】【order by】【limit】
上述代码,中括号里面的参数,就是可以可无的,可以任意调用相关的操作,进行查询和打印。
三、修改操作
修改操作相对比较简单,如下:
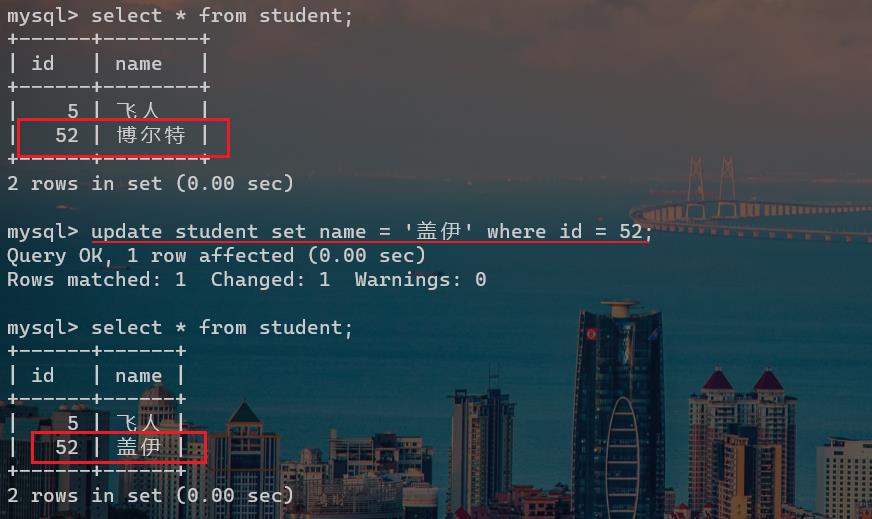
update 表名 set 列名=新数值 where 条件;
update 表名 set 列名=新数值,列名=新数值 where 条件;
如上述代码,第一行代码是修改某一列的值,第二行代码是修改许多列的值(修改很多列的值,只需每一列之间用逗号隔开即可)。但是有一个点值得注意的是:
符合where子句的某些数据,才会执行update操作。跟上面查询操作一样,也是类似于过滤的过程。当不写where子句时,将会对整张表进行update操作。
四、删除操作
删除操作,也是相对比较简单的,有如下代码:
delete from 表名;
delete from 表名 where 条件;
delete from 表名 where 条件 limit 参数;
delete from 表名 where 条件 order by 列名 asc或desc limit 参数;
有以上四种删除方式,看着比较多,但是只需要掌握第一条,其他3条都是根据第一条,添加一些逻辑语句即可实现。
第一行代码:没有添加where子句,则会删除这张表的所有数据,就类似于drop table 表名。(drop是将表都一起删了;delete还是会将表留下,只是里面的数据都没了)
第二行代码:加了where子句,有了过滤的效果,只有当某一行的数据满足where子句的条件,那么这一行数据就会被删除。
第三行代码:除了加where子句,还添加了limit;意思就是:满足where子句的数据,只会删除前limit子句的参数个。举个例子,假设limit 5,那么只会删除where子句过滤出来的,前5个数据。
第四行代码:除了有where、limit子句,还多加了个排序,也很好理解。将where子句过滤出来的数据先进行排序,然后再删除前(limit参数)行的数据。(既可以排升序,也可以降序)
五、聚合查询
前面我们所讲解的查询,都是以列为单位进行查询的,聚合查询则是以行为单位,进行一些操作。聚合查询分为两个部分:聚合函数和分组查询。
1、聚合函数
有以下5个聚合函数,也很好理解,就是一些求平均值、最大值等等,比较常见的函数:
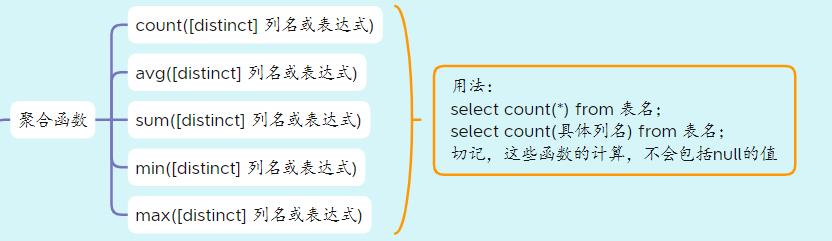
说以下count这个函数,可能有的人不知道这个事干啥的,说白了一句话,就是一个计数。举个例子:有一张学生表,现在问你这张表有多少个学生,就有以下代码:
select count(*) from student;
切记:聚合函数都是有一对圆括号的,不能搞掉了。
上面这行代码,圆括号里也可以填其他列名,比如name、id等等。但是,当这一列有null时,聚合函数是不会将它这一行的数据计算在内的,不仅仅是count,其他几个函数也是如此的。比如:现有5个学生数据,但是最后一个学生的name是null,此时通过count(name)计算时,只会得到4,而不是5。因为name为null的那个学生,没有计算在内。
然后就是这些聚合函数,可以添加distinct关键字,来去重。括号里的参数不仅仅可以是列名,还可以是表达式,比如min(语文+数学+英语),这样的代码就是计算谁的总成绩最小。
2、分组查询
分组查询:就是按照某一个参数值先进行分组,然后再进行其他的操作。

典型的例子就是:假设当前表中有1班和2班的所有学生的成绩,现在我需要分别计算两个班数学成绩的平均值,那么此时就需要通过分组的方式,来进行操作。
select classId,avg(math) from score group by classId;
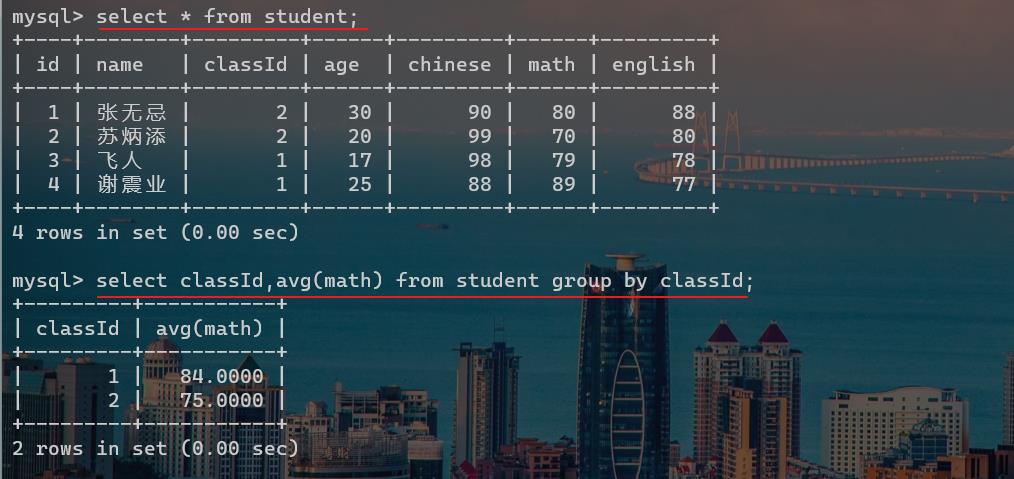
以上代码就是一个分组的例子,我们就可以通过关键字 group by进行分组。先根据班级进行分组,然后才是通过聚合函数进行计算平均值。
分组之后,就不能再使用where子句进行过滤了,而是使用having关键字,来进行过滤。
select classId,avg(math) from student group by classId having avg(math) > 80;

如上图,只有当数学的平均成绩超过80时,才会被打印出来。
六、多表查询(联合查询)
在实际开发过程中,我们的数据可能来自不同的表中,此时我们就需要使用多表联合查询。多表查询就是对多张表的数据取笛卡尔积,说的简单一点,就是对这多张表进行排列组合,从而得到多组数据。
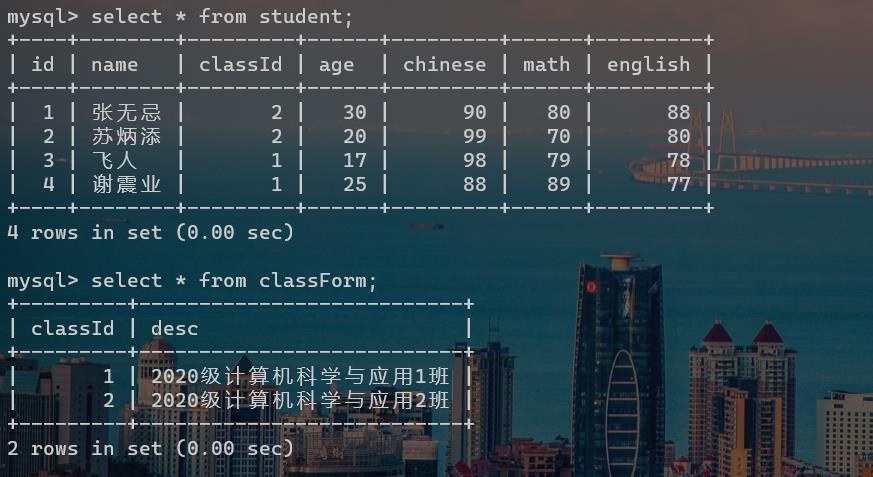
如上图,一张是学生表,另外一张是班级表。取笛卡尔积:将第一张表的每一行与第二张表的每一行进行组合,得到新的一行数据。
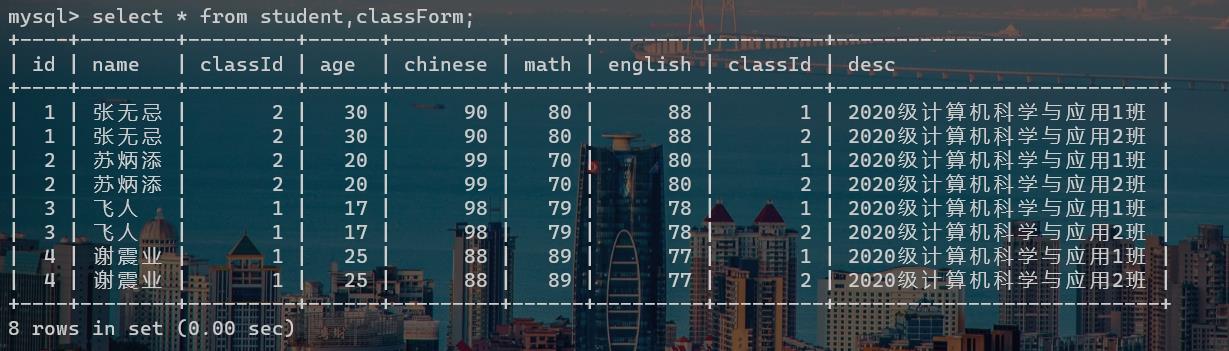
由上图,我们可以得到以下两点:这一张新的数据表
- 列数 = 第一张表的列数+第二张表的列数。
- 行数 = 第一张表的行数 * 第二张表的行数。
1、内连接
select * from 表名1 别名1,表名2 别名2 where 连接条件 and 其他条件;
select * from 表1 别名1 inner join 表2 别名2 on 连接条件 and 其他条件;
以上两种,就是多表查询的代码,下文中的外连接和自连接,也是在此基础之上,做一点点修改即可。
上面这两种书写方式都是可以,效果是一样的。from后面的表,都是可以起别名的,在上文我们也讲过起别名,那是在select后面起别名,需要使用as关键字,而在from后面的,不需要as,直接写别名即可。
对于第一行代码来说,需要多张表联合查询时,就书写多张表名即可;但是对于第二行代码来说,就需要书写多个inner join ……on语句。此处的inner是可以省略不写的。
对于上面的图片来说,只有当学生表的classId = classForm的classId时,才能说明当前这一行数据才是有效的数据,其他的都是无效的数据。这也是我们where子句或者on后面书写的连接条件,如下代码:
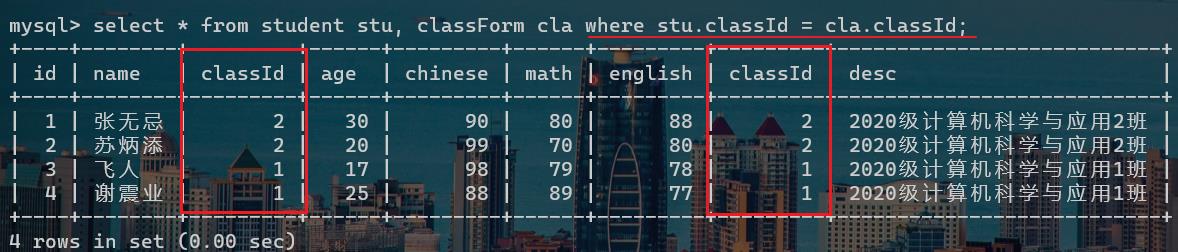
或者是join的写法:
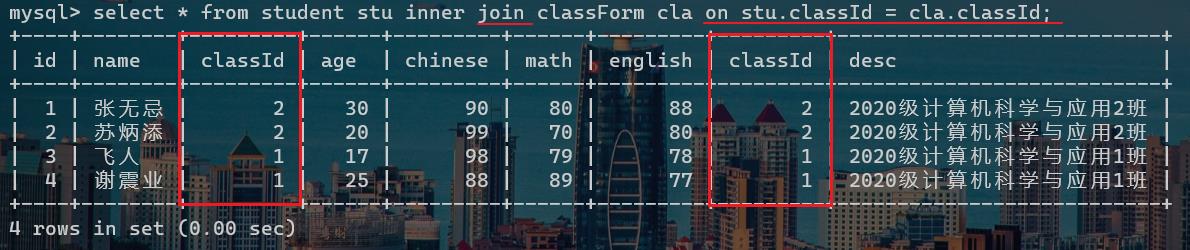
2、外连接
外连接,又分为左外连接和右外连接。
select * from 表名1 left join 表名2 on 连接条件 and 其他条件;
select * from 表名1 right join 表名2 on 连接条件 and 其他条件;
左外连接:会将左侧的表的所有数据显示。(第一行代码)
右外连接:会将右侧的表的所有数据显示。(第二行代码)
二者的区别就在于:还是拿上面的例子进行举例。假设现在有一位新同学的成绩也在表中,但是并不知道这位新同学是在哪个班,此时我们以班级id为关联点,再去多表查询两张表时,不会显示这位新同学的成绩。

此时我们使用左外连接,就能显示出这位新同学的成绩。因为student(null)是在左侧,也就是左侧表。
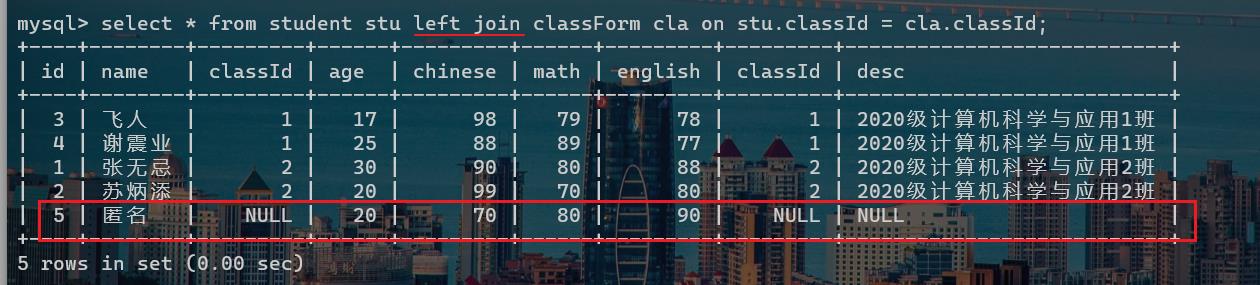
反之,假设null是在右侧表,那么使用右外连接即可显示所有的表。
3、自连接
自连接指的是在同一张表连接自身进行查询。这样的好处就是,将两张表进行了并列,能够做到行之间的查询。
假设现在有这样一张成绩表,专门记录每一门学科的成绩,表结构如下:
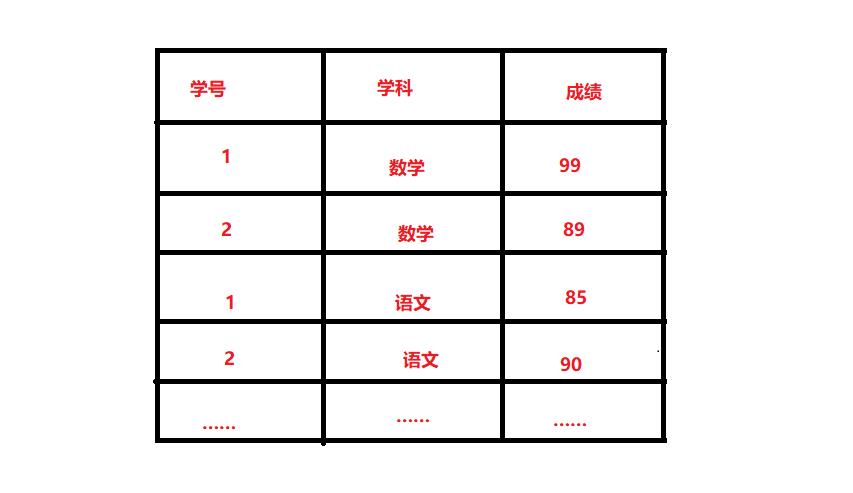
如上图,每一行只是某一课的学生成绩,此时问你:查询一个学校语文成绩超过80 并且 数学成绩超过90的同学??你该如何查询?
此时使用and逻辑运算符,就行不通了。只能通过自连接的形式,如下形式:
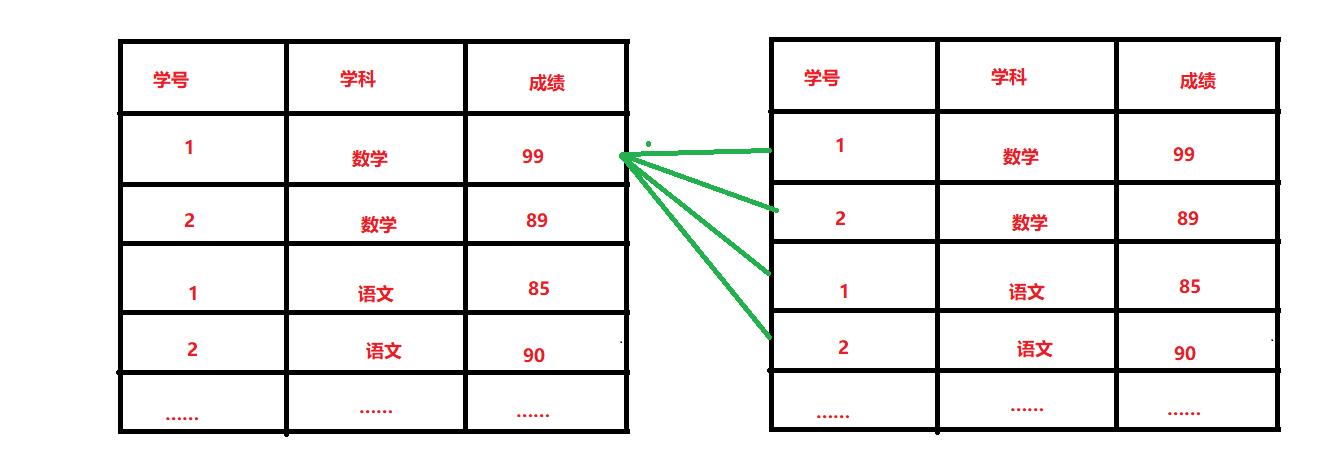
对这张表本身取笛卡尔积,就能得到一张新的表,此时每一行的数据,既有语文成绩,也有数学成绩了。那么通过这张表,就能找出语文成绩超过80 和 数学成绩超过90的同学了。
select * from score sco1 join score sco2
on sco1.id = sco2.id and (sco1.chinese > 80 and sco2.math > 90);
4、子查询
子查询就是嵌入在其他SQL语句的select语句,也称为嵌套查询。
单行子查询:返回一行记录的子查询
select * from 表名 where 条件= (select ……);
多行子查询:返回多行记录的子查询
-- 使用in
select * from score where course_id in
(select id from course where name = '语文' or name = '英文')
-- 使用 NOT IN
select * from score where course_id not in (select id from course where
name!='语文' and name!='英文');
5、合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all。使用UNION
和UNION ALL时,前后查询的结果集中,字段需要一致。 (也就是表1有id和name两个字段,那么表2查询的结果也必须是id和name这两个字段)
select * from 表名1 union select * from 表名2;
union 合并操作,会去除掉最终结果表的重复行。
select * from 表名1 union all select * from 表名2;
union all 合并操作,不会去除掉最终结果表的重复行。
这个合并操作,就类似于在同一张表中,where子句使用了or逻辑运算符。这个or呢,仅仅只局限在了同一张表,那么要是需要查询不同的表,级只能使用union操作了。
好啦,以上全部就是SQL的增删改查操作,除了阅读本文外,大家课外还需花大量的时间,来练习和巩固这些代码,深层次地理解每段代码背后的逻辑,更易于我们在后续的编码中,少一些bug。
好啦,本期更新就到此结束啦!!!我们下期再见吧!!!
以上是关于MySQL数据库系列二MySQL数据库增删改查(聚合查询多表查询)的主要内容,如果未能解决你的问题,请参考以下文章