大规模分布式图学习框架Euler——安装和使用
Posted xiaopihaierletian
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大规模分布式图学习框架Euler——安装和使用相关的知识,希望对你有一定的参考价值。
目录
一、Euler介绍
1. 框架
2. 应用
2.1 大规模图的分布式学习
2.2 支持复杂异构图的表征
2.3 图学习与深度学习的结合
2.4 分层抽象与灵活扩展
3. 内置算法
二、Euler安装
1. 编译
2. Euler安装
2.1 PyPI安装
2.2 源码编译安装
三、GraphSage模型训练
1. PPI数据
2. 模型训练
3. 模型评估
4. embedding输出
四、GraphSage模型分布式训练
1. 分布式训练
2. 启动
最近在调研graph embedding图机器学习算法,尝试了DeepWalk在推荐场景应用,碰到构造大规模节点,模型跑不下来问题。
阿里妈妈刚开源大规模分布式图学习框架Euler,其配合TensorFlow或者阿里开源XDL等深度学习工具,支持用户在数十亿点数百亿边的复杂异构图上进行模型训练。为graph embedding在推荐场景落地提供参考。
一、Euler介绍
1. 框架
Euler系统分为最底层的分布式图引擎,中间层图语义的算子,高层的图表示学习算法。如下图所示
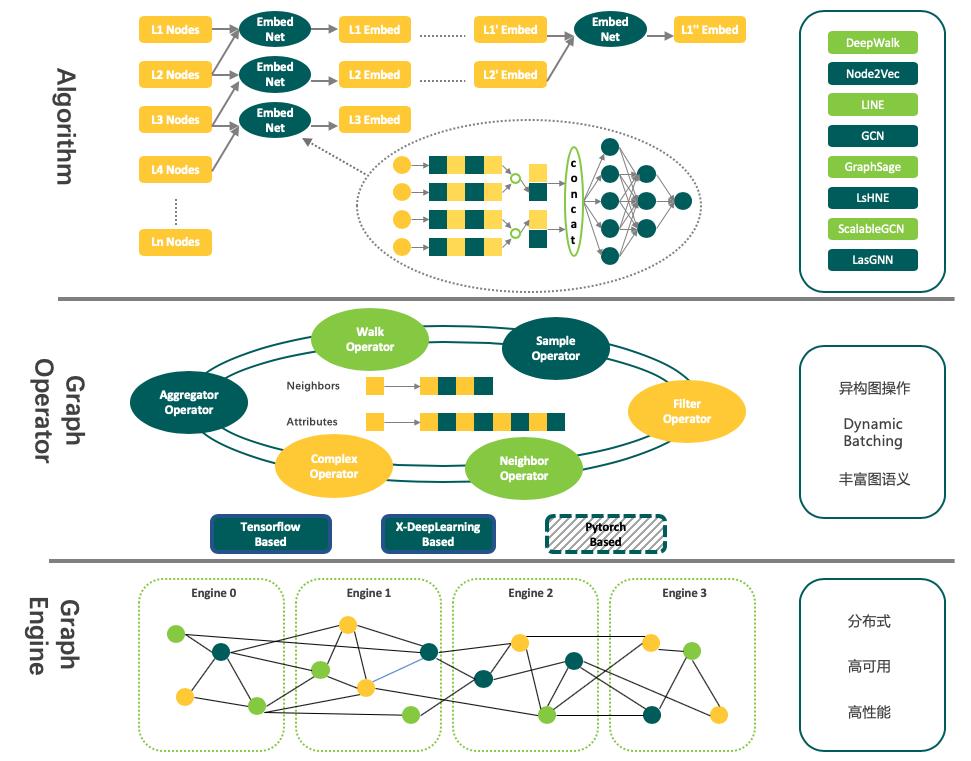
2. 应用
2.1 大规模图的分布式学习
工业界的图往往具有数十亿节点和数百亿边,有些场景甚至可以到数百亿节点和数千亿边,在这样规模的图上单机训练是不可行的。Euler支持图分割和高效稳定的分布式训练,可以轻松支撑数十亿点、数百亿边的计算规模。
2.2 支持复杂异构图的表征
工业界的图关系大都错综复杂,体现在节点异构、边关系异构,另外节点和边上可能有非常丰富的属性,这使得一些常见的图神经网络很难学到有效的表达。Euler在图结构存储和图计算的抽象上均良好的支持异构点、异构边类型的操作,并支持丰富的异构属性,可以很容易的在图学习算法中进行异构图的表征学习。
2.3 图学习与深度学习的结合
工业界有很多经典场景,例如搜索/推荐/广告场景,传统的深度学习方法有不错效果,如何把图学习和传统方法结合起来,进一步提升模型能力是很值得探索的。Euler支持基于深度学习样本的mini-batch训练,把图表征直接输入到深度学习网络中联合训练。
2.4 分层抽象与灵活扩展
Euler系统抽象为图引擎层、图操作算子层、算法实现层三个层次,可以快速的在高层扩展一个图学习算法。实际上,Euler也内置了大量的算法实现供大家直接使用。
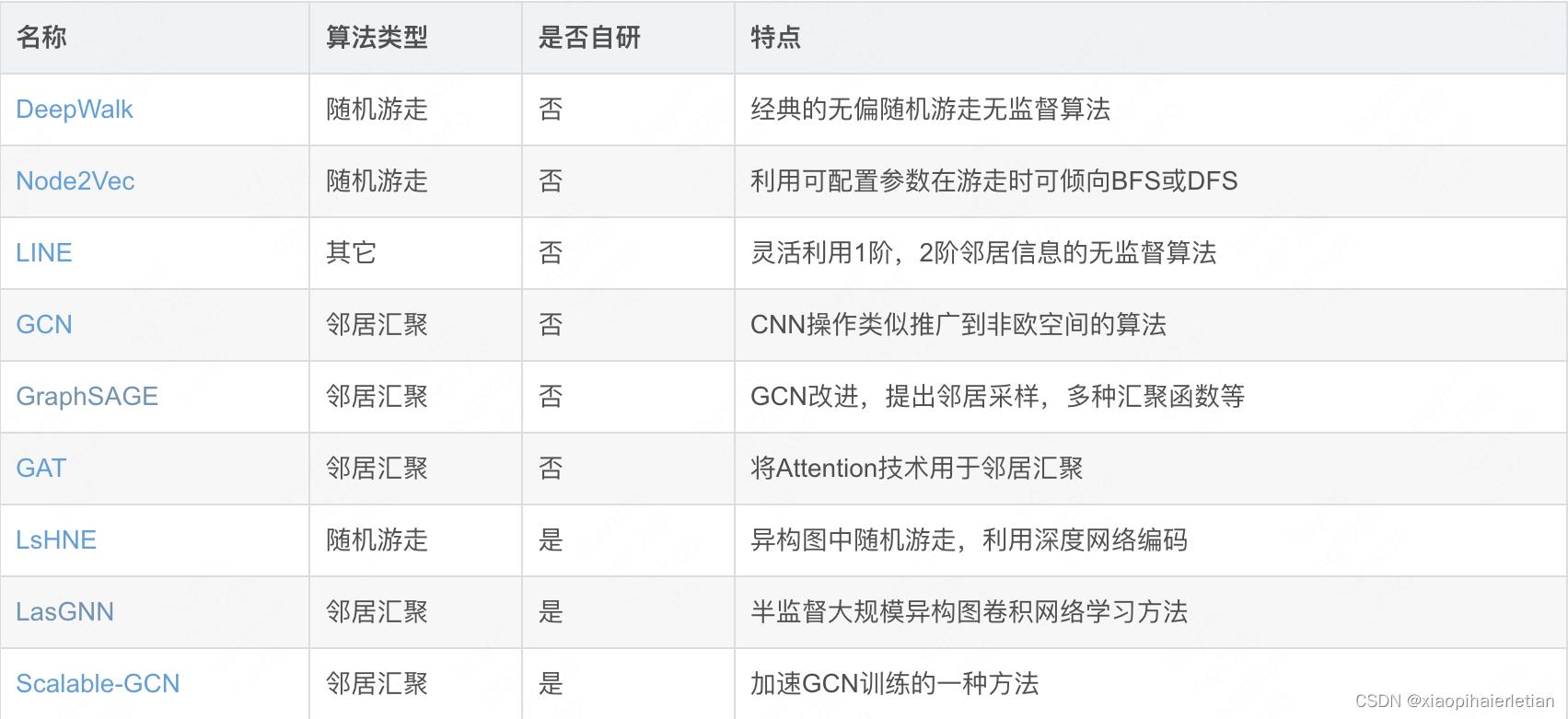
3. 内置算法
二、Euler安装
1. 编译
Euler的编译和启动依赖libhdfs.so和libjvm.so存在于$LD_LIBRARY_PATH中,因此需要添加环境变量如下
sudo vi ~/.bashrc
# 添加环境变量
# $JAVA_HOME=/opt/modules/jdk1.8.0_172/jre
# $HADOOP_HOME=/opt/modules/hadoop-2.7.7
export LD_LIBRARY_PATH=/opt/modules/jdk1.8.0_172/jre/lib/server:$LD_LIBRARY_PATH
export LIBRARY_PATH=/opt/modules/hadoop-2.7.7/lib/native:$LIBRARY_PATH
export LD_LIBRARY_PATH=/opt/modules/hadoop-2.7.7/lib/native:$LD_LIBRARY_PATH
export CLASSPATH=$(/opt/modules/hadoop-2.7.7/bin/hadoop classpath --glob):$CLASSPATH
2. Euler安装
Euler目前仅支持Python2,可以选择从PyPI或者源码编译安装Euler,推荐PyPI安装。
2.1 PyPI安装
目前PyPI上的wheel基于TensorFlow 1.12编译,仅能与TensorFlow 1.12二进制兼容。如需使用其他版本的TensorFlow需要重新编译。
pip install euler-gl
2.2 源码编译安装
git clone --recursive https://github.com/alibaba/euler.git
递归third_party失败,没有采用该方法安装。
三、GraphSage模型训练
GraphSage是由Stanford提出的一种Inductive的图学习方法,具有GCN模型的良好性质,同时在实际使用中可以扩展到十亿顶点的大规模图。接下来尝试使用Euler和TensorFlow进行GraphSage模型训练。
1. PPI数据
准备Euler引擎可以读取的图数据,这里我们以PPI(Protein-Protein Interactions)为例:
curl -k -O https://raw.githubusercontent.com/alibaba/euler/master/examples/ppi_data.py
pip install networkx==1.11 sklearn
python ppi_data.py
在当前目录下生成一个ppi目录(如下),其中包含构建好的PPI图数据。
ppi
├── ppi-class_map.json
├── ppi_data.dat
├── ppi_data.json
├── ppi-feats.npy
├── ppi-G.json
├── ppi-id_map.json
├── ppi_meta.json
├── ppi_test.id
├── ppi_train.id
├── ppi_val.id
└── ppi-walks.txt
2. 模型训练
在训练集上训练一个半监督的GraphSage模型:
python -m tf_euler \\
--data_dir ppi \\
--max_id 56944 --feature_idx 1 --feature_dim 50 --label_idx 0 --label_dim 121 \\
--model graphsage_supervised --mode train
在当前目录生成一个ckpt目录(如下),其中包含训练好的TensorFlow模型。
ckpt/
├── checkpoint
├── events.out.tfevents.1548073220.lee
├── graph.pbtxt
├── model.ckpt-0.data-00000-of-00001
├── model.ckpt-0.index
├── model.ckpt-0.meta
├── model.ckpt-2220.data-00000-of-00001
├── model.ckpt-2220.index
├── model.ckpt-2220.meta
└── timeline-2209.json
3. 模型评估
在测试集上评估模型的效果:
python -m tf_euler \\
--data_dir ppi --id_file ppi/ppi_test.id \\
--max_id 56944 --feature_idx 1 --feature_dim 50 --label_idx 0 --label_dim 121 \\
--model graphsage_supervised --mode evaluate
使用Euler算法包默认参数训练得到的模型在测试集上的mirco-F1 score大概在0.6左右。
4. embedding输出
导出顶点的embedding
python -m tf_euler \\
--data_dir ppi \\
--max_id 56944 --feature_idx 1 --feature_dim 50 --label_idx 0 --label_dim 121 \\
--model graphsage_supervised --mode save_embedding
在当下目录下的ckpt目录中生成一个embedding.npy文件和一个id.txt文件,分别表示图中所有顶点的embedding和id。
四、GraphSage模型分布式训练
1. 分布式训练
Euler算法包及其底层的图查询引擎支持分布式的模型训练,用户需要在原始的训练命令上加入四个参数--ps_hosts、--worker_hosts、--job_name、--task_index指定分布式角色。如下提供脚本在本机的1998至2001端口上启动两个ps和两个worker进行分布式训练。
#!/usr/bin/env bash
NUM_PSES=2
NUM_WORKERS=2
PS_HOSTS=""
for I in $(seq $(($NUM_PSES - 1)) -1 0)
do
PS_HOST="localhost:$((1999 - $I))"
if [ "$PS_HOSTS" == "" ]; then
PS_HOSTS="$PS_HOST"
else
PS_HOSTS="$PS_HOSTS,$PS_HOST"
fi
done
WORKER_HOSTS=""
for I in $(seq 0 $(($NUM_WORKERS - 1)))
do
WORKER_HOST="localhost:$((2000 + $I))"
if [ "$WORKER_HOSTS" == "" ]; then
WORKER_HOSTS="$WORKER_HOST"
else
WORKER_HOSTS="$WORKER_HOSTS,$WORKER_HOST"
fi
done
for I in $(seq 0 $(($NUM_PSES - 1)))
do
python -m tf_euler \\
--ps_hosts=$PS_HOSTS \\
--worker_hosts=$WORKER_HOSTS \\
--job_name=ps --task_index=$I &> /tmp/log.ps.$I &
done
for I in $(seq 0 $(($NUM_WORKERS - 1)))
do
python -m tf_euler \\
--ps_hosts=$PS_HOSTS \\
--worker_hosts=$WORKER_HOSTS \\
--job_name=worker --task_index=$I $@ &> /tmp/log.worker.$I &
WORKERS[$I]=$!
done
trap 'kill $(jobs -p) 2> /dev/null; exit' SIGINT SIGTERM
wait $WORKERS[*]
kill $(jobs -p) 2> /dev/null
2. 启动
使用分布式训练时,数据需要放置在HDFS上。
hdfs dfs -mkdir /data
hdfs dfs -put ppi /data/
启动脚本如下,进行分布式训练。
bash scripts/dist_tf_euler.sh \\
--data_dir hdfs://lee:8020/data/ppi \\
--euler_zk_addr lee:2181 \\
--max_id 56944 --feature_idx 1 --feature_dim 50 --label_idx 0 --label_dim 121 \\
--model graphsage_supervised --mode train
参考资料
https://blog.csdn.net/baymax_007/article/details/86093856
https://yq.aliyun.com/articles/625340
以上是关于大规模分布式图学习框架Euler——安装和使用的主要内容,如果未能解决你的问题,请参考以下文章