presto的安装部署
Posted weixin_42412601
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了presto的安装部署相关的知识,希望对你有一定的参考价值。
目录
- 1、简介
- 2、下载presto安装包
- 3、解压,并同级新建一个data目录
- 4、生成配置
- 5、配置 connector
- 6、启动presto
- 7、命令行界面
- 8、presto可视化client安装
- 9、presto优化之数据存储
- 10、presto优化之查询SQL
- 11、注意事项
1、简介
presto是一个开源的分布式sql查询引擎,数据量支持GB到PB字节,主要用来处理秒级查询的场景
注意:虽然presto可以解析sql,但它不是一个标准的数据库。不是mysql,oracle的替代品,也不能用来处理在线事务(OLTP)
1.1、架构:主从架构,一个协调者和多个worker组成
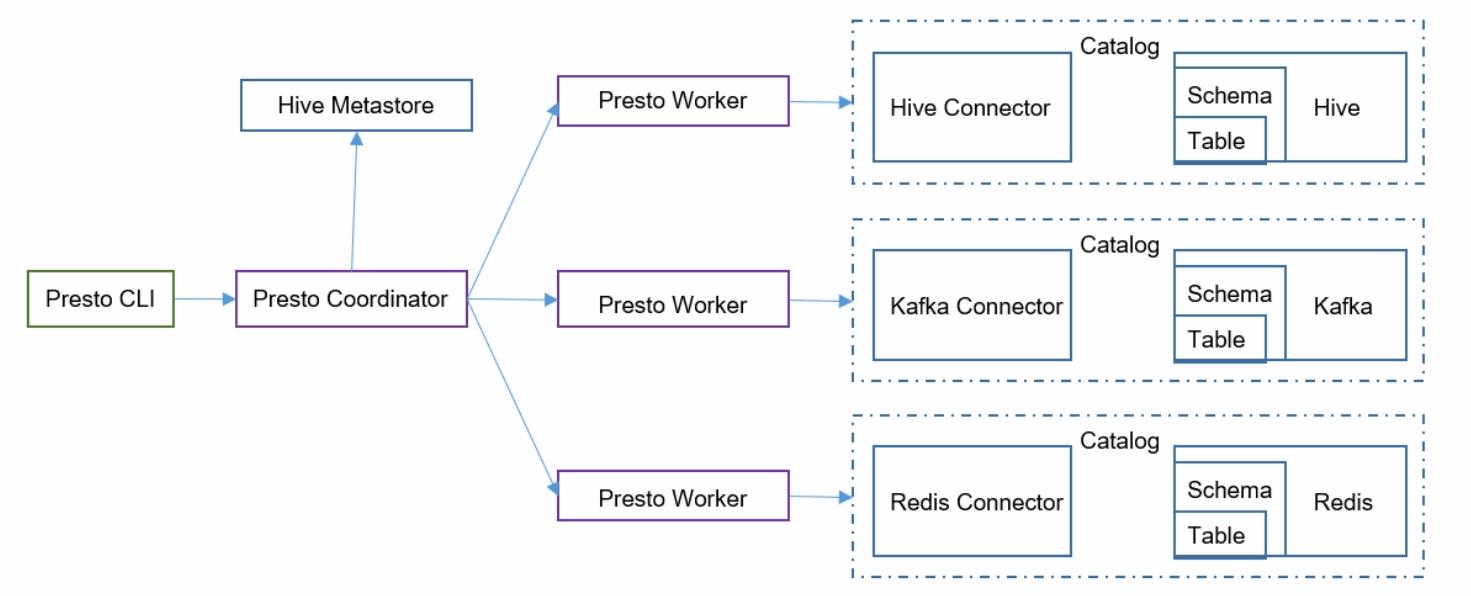
presto Coordinator协调者:
- 接受客户端请求,即接受sql,并把sql解析成具体的计算任务,然后将任务分配给worker
- 能够对接多种数据源,hive/kafka/redis/mysql等。比如:对接hive,需要去访问Hive的元数据【hive metastore】,就可以去访问数据
presto worker:执行任务的节点,负责计算和读写
catalog:数据源,例如:hive/kafka/redis/mysql等
connector:连接器,不同的数据源有不同的连接器。你想要的对接hive,你就需要配置一个hive的connector
schema:可以和数据库类比
table:就是表
补充:
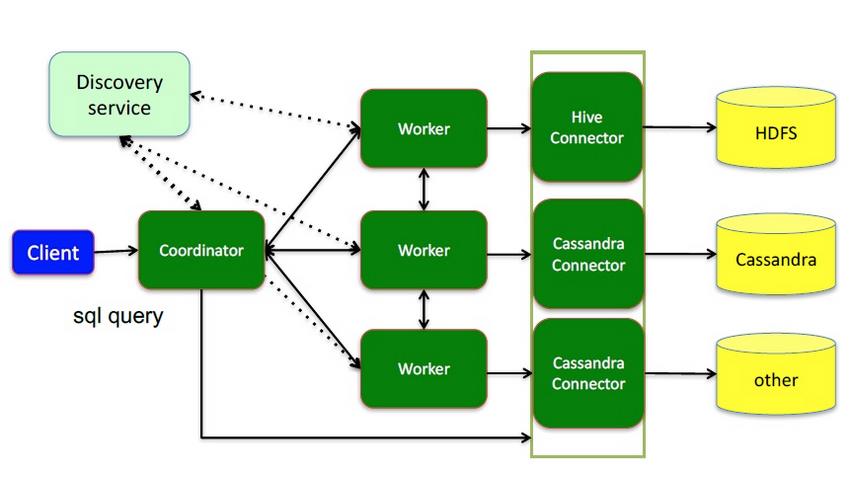
discovery service:内嵌在coordinator节点中,也可以单独部署,用于节点心跳;worker节点启动后向discovery service服务注册,coordinator通过discovery service获取注册的worker节点
1.2、优缺点
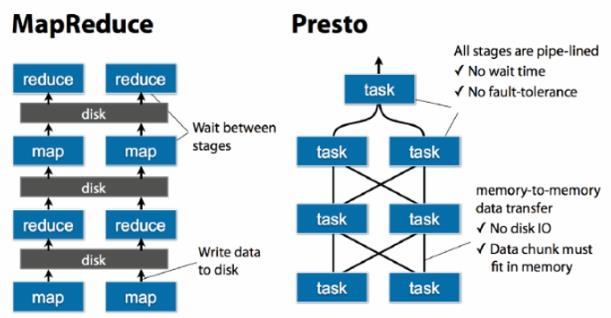
mapreduce中的计算中间结果是保存在磁盘上的,这样必然影响整体运行速度。
presto如果内存足够大,数据可以在内存中完成计算,不需要持久化到磁盘,但是如果内存不足,数据量比较大,计算的中间结果还是会保存在磁盘中的
优点:
- presto基于内存运算,减少了硬盘IO,计算更快
- 能够连接多个数据源,跨数据源连表查询,如从Hive查询大量网站访问记录,然后从Mysql中匹配出设备信息。
- 为什么能连表查询?不用管数据源是什么,hive也好,kafka也好,还是redis也好。到了presto中,它都是一个schema下的table,相当于在presto中,两个表进行join
缺点:
presto能够处理PB级别的海量数据分析,但presto并不是把PB级数据都放在内存中计算的。而是根据场景,如count,avg等聚合运算,是边读数据边计算,再清内存,再读数据,再计算,这种耗内存并不高。但是连表查询,就可能产生大量的临时数据,因此速度会变慢,反而hive此时会更擅长
2、下载presto安装包
https://prestodb.io/docs/current/installation/deployment.html
3、解压,并同级新建一个data目录

data 用于存储日志、本地元数据等的数据目录。 建议在安装目录的外面创建一个数据目录。这样方便Presto进行升级。
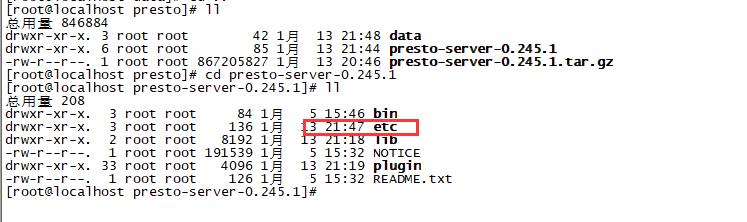
4、生成配置
在安装目录中创建一个目录 etc , 加入以下配置:
节点属性:特定于每个节点的环境配置 --- etc/node.properties
JVM Config:Java虚拟机的命令行选项 --- etc/jvm.config
配置属性:Presto服务器的配置 --- etc/config.properties
日志级别配置文件 --- etc/log.properties
目录属性:连接器(数据源)的配置
3.1、节点属性
vi etc/node.properties
#环境的名称。群集中的所有Presto节点必须具有相同的环境名称。
node.environment=production
#此Presto安装的唯一标识符。对于每个节点,这必须是唯一的
node.id=presto1
#Presto将在此处存储日志和其他数据。
node.data-dir=/root/presto/data
3.2、JVM Config
vi etc/jvm.config
-server
-Xmx1G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
-Djdk.attach.allowAttachSelf=true
3.3、配置属性
vi etc/config.properties
#允许此Presto实例充当协调器,接受来自客户端的查询并管理查询执行
coordinator=true
#允许在协调器上安排工作。
#对于较大的集群,协调器上的处理工作可能会影响查询性能,因为计算机的资源不可用于调度,管理和监视查询执行的关键任务。
node-scheduler.include-coordinator=true
#指定HTTP服务器的端口
http-server.http.port=8081
#查询可能使用的最大分布式内存量
query.max-memory=100MB
#查询可在任何一台计算机上使用的最大用户内存量
query.max-memory-per-node=100MB
#查询可在任何一台计算机上使用的最大用户和系统内存量,其中系统内存是读取器,
#写入程序和网络缓冲区等执行期间使用的内存。
query.max-total-memory-per-node=100MB
#Presto使用Discovery服务查找集群集中的所有节点。
discovery-server.enabled=true
#Discovery服务器的URI。因为我们在Presto协调器中启用了Discovery的嵌入式版本,所以它应该是Presto协调器的URI。
#替换example.net:8080以匹配Presto协调器的主机和端口。此URI不得以斜杠结尾。
discovery.uri=http://localhost:8081
3.4、日志级别配置文件
[root@localhost etc]# cat log.properties
com.facebook.presto = INFO
添加完,所有配置文件后,etc目录如下:

5、配置 connector
这里演示mysql的connector。
etc目录下新建目录catalog,创建一个mysql connector,vi mysql.properties
connector.name=mysql
connection-url=jdbc:mysql://192.168.169.129:3306
connection-user=root
connection-password=123456
如果是hive的connector
vi hive.properties
connector.name=hive-hadoop2 #注意 connector.name 只能是 hive-hadoop2
hive.metastore.uri=thrift://hadoop101:9083
hive.config.resources=/etc/hadoop/core-site.xml,/etc/hadoop/hdfs-site.xml
6、启动presto
bin目录下
[root@localhost bin]# ./launcher start
访问:http://192.168.169.129:8081/ui/
7、命令行界面
下载:https://prestodb.io/docs/current/installation/cli.html
Presto CLI提供了一个基于终端的交互式shell,用于运行查询。CLI是一个 自动执行的 JAR文件,这意味着它的行为类似于普通的UNIX可执行文件。
下载 presto-cli-0.219-executable.jar,将其重命名为presto-cli(自定义)
#增加执行权限,并绑定调度器端口
[root@localhost presto]# chmod +x pre-cli
[root@localhost presto]# ./presto-cli --server localhost:8081
### 简单的使用
presto> show schemas from mysql;
Schema
--------------------
gulimall_admin
gulimall_oms
gulimall_pms
gulimall_sms
gulimall_ums
gulimall_wms
information_schema
performance_schema
sys
(9 rows)
Query 20210113_142113_00001_4rcgr, FINISHED, 1 node
Splits: 19 total, 19 done (100.00%)
0:01 [9 rows, 158B] [6 rows/s, 108B/s]
presto:default> use gulimall_wms;
USE
presto:gulimall_wms> show tables;
Table
----------------------------
undo_log
wms_purchase
wms_purchase_detail
wms_ware_info
wms_ware_order_task
wms_ware_order_task_detail
wms_ware_sku
(7 rows)
Query 20210113_153210_00013_4rcgr, FINISHED, 1 node
Splits: 19 total, 19 done (100.00%)
0:01 [7 rows, 263B] [4 rows/s, 180B/s]
presto:gulimall_wms> select * from wms_ware_sku;
id | sku_id | ware_id | stock | sku_name
----+--------+---------+-------+-----------------------------------------------------------------------------------
1 | 1 | 3 | 139 | 华为
2 | 2 | 2 | 100 | 华为 HUAWEI P30 Pro 亮黑色 8GB+128GB 超感光徕卡四摄10倍混合变焦麒麟980芯片屏内指纹
3 | 3 | 2 | 100 | 华为 HUAWEI P30 Pro 天空之镜 8GB+256GB 超感光徕卡四摄10倍混合变焦麒麟980芯片屏内指
#可以设置默认的schema,数据库
[root@localhost presto]# ./presto-cli --server localhost:8081 --catalog mysql --schema default
8、presto可视化client安装
下载:
https://github.com/zhaolianchao/yanagishima/releases
9、presto优化之数据存储
1、合理设置分区
与hive类似,presto会根据元数据信息读取分区数据,合理的分区能减少presto数据读取量,提升查询性能
2、使用列式存储
presto对ORC文件读取做了特定优化,因此在Hive中创建presto使用的表时,建议采用ORC格式存储。相对于parquet,parquet对ORC支持更好。
3、使用压缩
数据压缩可以减少节点间数据传输对IO带宽压力,对于即席查询需要快速解压,建议采用Snappy压缩
10、presto优化之查询SQL
1、只选择使用的字段
由于采用列式存储,选择需要的字段可加快字段的读取、减少数据量。减少采用*读取所有字段
good: select time,user,host from tb1;
bad: select * from tb1;
2、过滤条件必须加上分区字段
对于分区的表,where语句中优先使用分区字段进行过滤。acct_day是分区字段,visit_time是具体访问时间。
good: select time,user,host from tb1 where acct_day=12456
bad: select time,user,host from tb1 where visit_time=xxx
3、group by语句优化
合理安排group by语句中字段顺序对性能有一定的提升。将group by语句中字段按照每个字段distinct数据多少进行降序排序。
good: select group by uid,gender;
bad : select group by gender,uid;
4、order by时使用limit
order by需要扫描数据到单个worker节点进行排序,导致单个worker需要大量内存。如果是查询Top N或者Bottom N,使用limit可减少排序计算和内存压力。
good: select * from tb1 order by time limit 100
bad: select * from tb1 order by time
5、使用join语句时将大表放在左边
presto中join默认算法是broadcast join,即将join左边的表分割多个到worker,然后将join右边的表数据整个复制一份发送到每个worker进行计算。如果右边的表数据量太大,则可能会报内存溢出的错误。
good:select xx from big_table a join small_table b on a.id=b.id
bad: select xx from small_table a join big_table b on a.id=b.id
11、注意事项


以上是关于presto的安装部署的主要内容,如果未能解决你的问题,请参考以下文章