深度学习前言综述
Posted Vinicier
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习前言综述相关的知识,希望对你有一定的参考价值。
本博客中的系列笔记主要针对Github 上这本有关深度学习的书——《deep learning book》相关的读书笔记。针对当前热门的深度学习做一个基本的梳理,感兴趣的朋友可以看看!
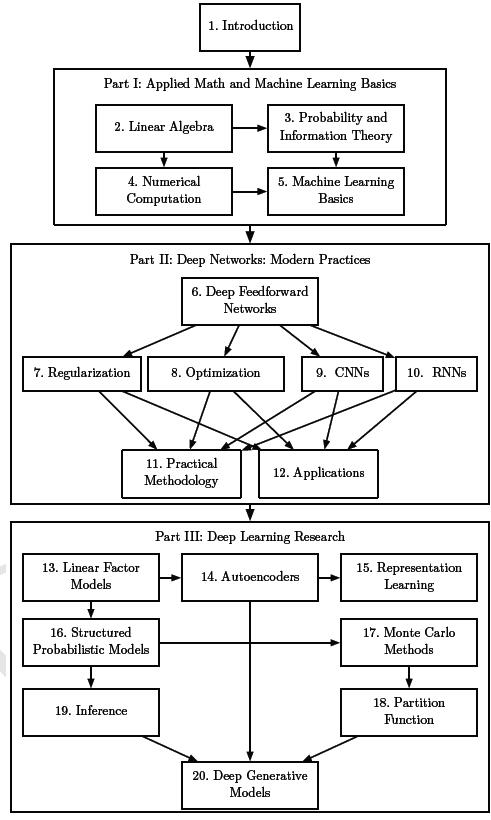
本书的章节安排结构如下
人工智能
人工智能(AI) 是一个具有许多实际应用和活跃研究课题的领域,并蓬勃发展着。我们指望通过智能软件自动化处理常规劳动、理解语音或图像、帮助医学诊断和支持基础科学研究。
机器学习
机器学习(Machine Learning) 是指AI系统具有自己获取知识的能力,即从原始数据中提取模式的能力。
引入机器学习使计算机可以解决设计现实世界知识的问题,并能做出看似“主观”的决策。
常见的机器学习算法包括逻辑回归(Logistics Regression) 、 朴素贝叶斯(Navie Bayes) 等… 这些机器学习算法的性能很大程度上依赖于给定数据的表示(Representation) 。
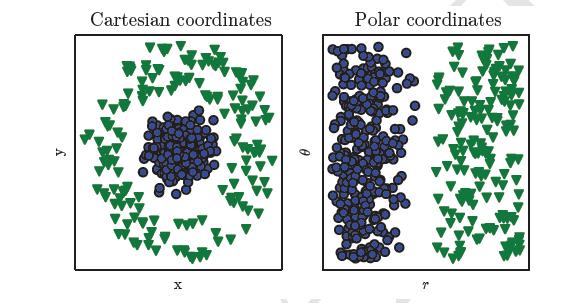
上图就是一个简单的可视化例子,左图是数据在笛卡尔坐标系中的表示,右边是数据在极坐标中的表示。
但是我们很难知道应该提取哪些特征。例如,我们编写一个识别程序来检测照片中的车辆,我们想用车轮的存在作为特征,不幸的是,我们很难准确地从像素值的角度描述一个车轮看起来如何。车轮有简单的几何形状,但它的图像可以因为环境变得很复杂,如落在车轮上的阴影、太阳照亮的车轮金属零件、汽车挡泥板或遮挡的前景物体等。
表示学习
解决这个问题的一个途径就是用机器学习来发现表示本身,而不仅仅把表示映射到输出。这种学习方法被称为表示学习(Representation Learning) 。学习到的往往获得比手动设计的表示更好的性能。并且它们只需最少的人工干预, 就能让AI系统迅速适应新的任务。表示学习算法只需几分钟就可以为简单的任务发现一个很好的特征集,对于复杂任务则需要几小时到几个月。手动为一个复杂的任务设计特征需要耗费大量的人工时间和精力;甚至需要花费整个社群研究人员几十年时间。
自动编码器
一个典型的表示学习的例子就是自动编码器(autoencoder) 。自动编码器是组合了将输入转换到不同表示编码器(encoder) 函数和将新的表示转回原来形式的解码器(decoder) 函数。
自动编码器的目标是输入经过编码器和解码器之后尽可能多的保留信息,同时希望新的表示有各种好的属性。 不同种类的自动编码器的目标是实现不同种类的属性。
下图是一个自动编码器的示例:
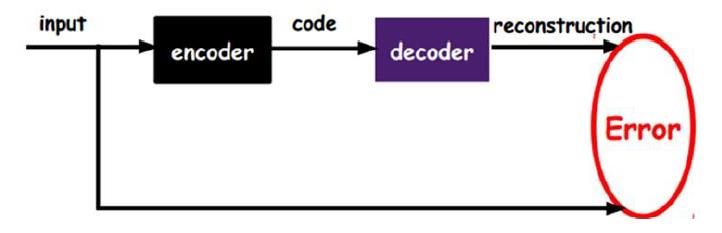
如上图,将input 输入一个encoder 编码器,就会得到一个code,这个code 就是输入的一个表示,那么我们怎么知道这个code 的表示就是输入input 呢?这时候我们加一个decoder 解码器,这时候解码器就会输出一个信息,那么如果这个输出信息和一开始的输入信号input很相似(理想情况一样),那么很明显,我们就有理由相信这个code是input的一个靠谱的表示。所以通过调整encoder 和decoder 的参数,使得重构误差最小,这时我们就得到输入信号input 的第一个表示了,也就是编码code 。因为使用的是无标签数据学习,所以误差的来源就是直接重构后与原输入相比得到。
然而现实世界中从原始数据中提取高层次、抽象的特征是非常困难的。 深度学习(Deep Learning)通过其他较简单的表示来表达复杂表示,解决了表示学习中核心问题 。
深度学习
深度学习让计算机通过较简单概念构建复杂的概念。下图显示了深度学习系统通过组合较简单的概念,例如转角和轮廓,转而定义边缘来表示图像中一个人的概念。深度学习模型的典型例子是前馈深度网络或多层感知机(MLP)。多层感知机仅仅是一个将一组输入值映射到输出的数学函数。该函数由许多较简单的函数组合而构成。我们可以认为每个应用具有不同的数学函数,并为输入提供新的表示。
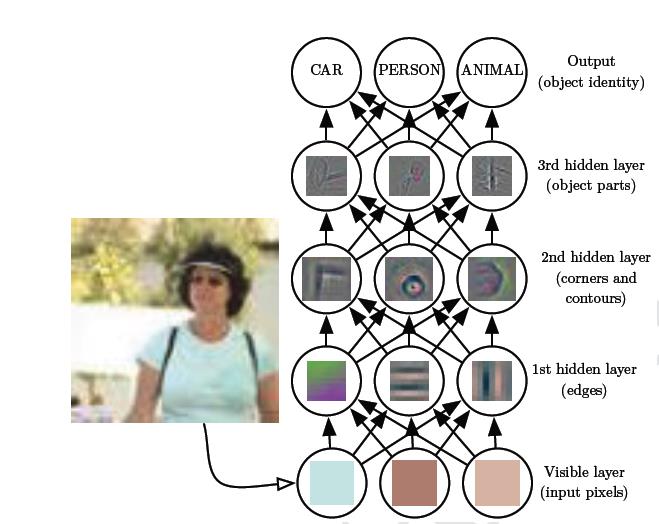
学习数据的正确表示的想法是深度学习的一个观点。另一个观点是深度允许计算机学习一个多步骤的计算机程序。
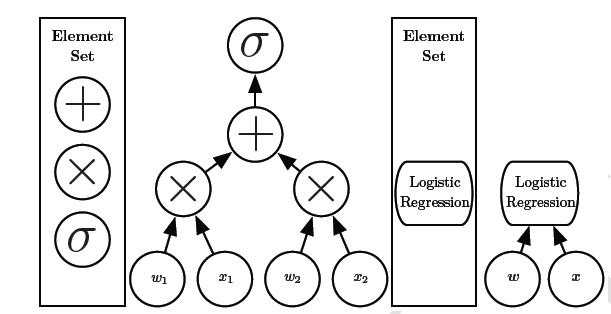
上图显示了语言的选择泽阳给相同的两个架构两个不同的衡量。
总结
总之,这本书的主题是——深度学习是AI的途径之一。具体地讲,它是机器学习地一种,一种允许计算机系统能从经验和数据中得到提高地技术。
本书主张机器学习是构建能在复杂实际环境下运行的AI系统的唯一可行方法。深度学习是一种特定类型的机器学习,通过将世界表示为由较简单概念定义复杂概念,从一般抽象到高级抽象的嵌套概念体系获得极大的能力和灵活性。
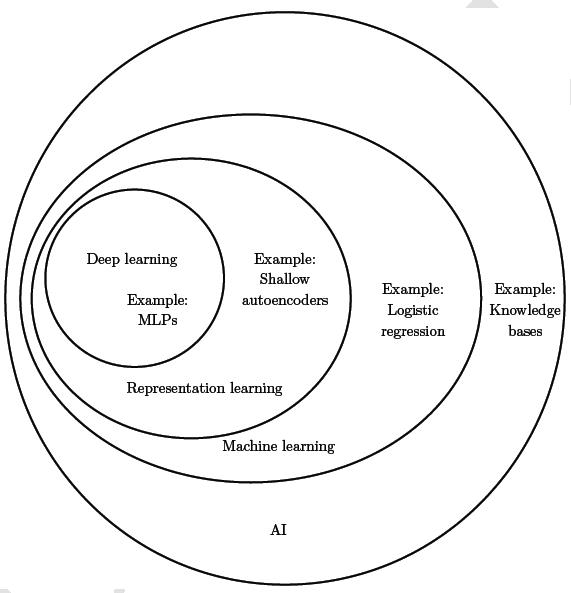
下图说明了这些不同地AI 学科之间地关系
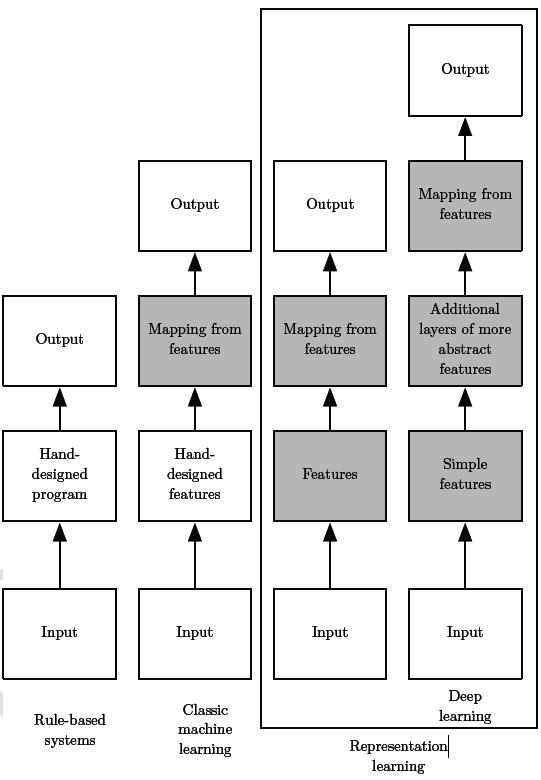
下图给出了每个学科如何工作地一个高层次原理
以上是关于深度学习前言综述的主要内容,如果未能解决你的问题,请参考以下文章