Redis学习笔记1819——波动的响应延迟:如何应对变慢的Redis
Posted qq_34132502
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis学习笔记1819——波动的响应延迟:如何应对变慢的Redis相关的知识,希望对你有一定的参考价值。
总的来说,从三个方面考虑:
- 问题认定
- 系统排查
- 应对方案
一、Redis真的变慢了么
最直接的方案就是查看Redis的响应延迟
redis-cli --latency -h host -p port
如果大部分时候Redis延迟很低,而偶尔会出现几秒甚至几十秒的延迟,这基本可以断定Redis变慢了
这种办法是看延迟的绝对值,但是由于不同的软硬件环境下,其延迟时间并不相同。所以还需要通过当前环境下的Redis基线性能做判断。
从 2.8.7 版本开始,redis-cli命令提供了--intrinsic-latency选项,可以用来监测和统计测试期间内的最大延迟,这个延迟可以作为 Redis 的基线性能。其中,测试时长可以用--intrinsic-latency选项的参数来指定。
./redis-cli --intrinsic-latency 120
Max latency so far: 17 microseconds.
Max latency so far: 44 microseconds.
Max latency so far: 94 microseconds.
Max latency so far: 110 microseconds.
Max latency so far: 119 microseconds.
36481658 total runs (avg latency: 3.2893 microseconds / 3289.32 nanoseconds per run).
Worst run took 36x longer than the average latency.
一般来说,你要把运行时延迟和基线性能进行对比,如果你观察到的 Redis 运行时延迟是其基线性能的 2 倍及以上,就可以认定 Redis 变慢了。
如果你想了解网络对 Redis 性能的影响,一个简单的方法是用iPerf这样的工具,测量从 Redis 客户端到服务器端的网络延迟。如果这个延迟有几十毫秒甚至是几百毫秒,就说明,Redis 运行的网络环境中很可能有大流量的其他应用程序在运行,导致网络拥塞了。这个时候,你就需要协调网络运维,调整网络的流量分配了。
二、如何应对Redis变慢
性能诊断通常是一件困难的事,所以我们一定不能毫无目标地“乱找”。这节课给你介绍的内容,就是排查和解决 Redis 性能变慢的章法,你一定要按照章法逐一排查,这样才可能尽快地找出原因。
下面是 Redis 架构图。我们需要重点关注三个红色模块,也就是 Redis 自身的操作特性、文件系统和操作系统,它们是影响 Redis 性能的三大要素。
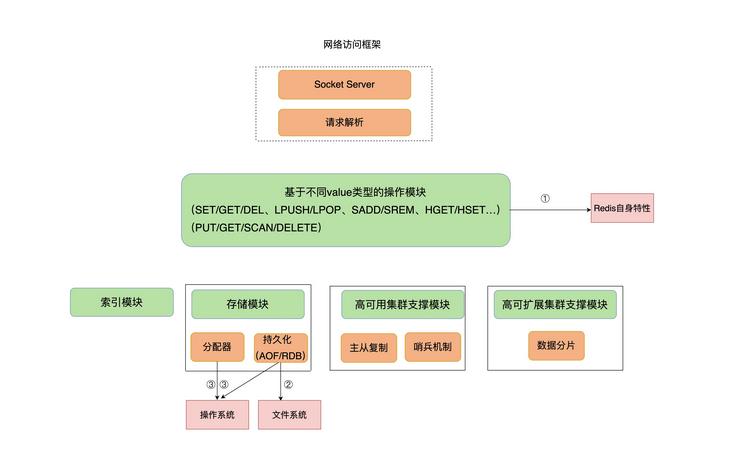
1、Redis自身操作特性的影响
首先,我们来学习下 Redis 提供的键值对命令操作对延迟性能的影响。我重点介绍两类关键操作:慢查询命令和过期 key 操作。
(1)慢查询命令
慢查询命令,就是指在 Redis 中执行速度慢的命令,这会导致 Redis 延迟增加。
比如说,Value 类型为 String 时,GET/SET 操作主要就是操作 Redis 的哈希表索引。这个操作复杂度基本是固定的,即 O(1)。但是,当 Value 类型为 Set 时,SORT、SUNION/SMEMBERS 操作复杂度都相当高。
当发现 Redis 性能变慢时,可以通过 Redis 日志,或者是latency monitor工具,查询变慢的请求,根据请求对应的具体命令以及官方文档,确认下是否采用了复杂度高的慢查询命令。
如果确实出现了大量的慢查询命令,可以采取两种办法:
- 用其他高效命令代替。比如说,如果你需要返回一个 SET 中的所有成员时,不要使用 SMEMBERS 命令,而是要使用 SSCAN 多次迭代返回,避免一次返回大量数据,造成线程阻塞。
- 当遇到排序、交并集操作时,可以在客户端完成,而不要用SORT、SUNION、SINTER这些命令。
还有一个比较容易忽略的慢查询命令,就是 KEYS。它用于返回和输入模式匹配的所有 key。因为 KEYS 命令需要遍历存储的键值对,所以操作延时高。所以,KEYS 命令一般不被建议用于生产环境中。
(2)过期key操作
过期 key 的自动删除机制是 Redis 用来回收内存空间的常用机制,应用广泛,本身就会引起 Redis 操作阻塞,导致性能变慢,所以,你必须要知道该机制对性能的影响。
Redis 键值对的 key 可以设置过期时间。默认情况下,Redis 每 100 毫秒会删除一些过期 key,具体算法如下:
- 采样
ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP个数的 key,并将其中过期的 key 全部删除; - 如果超过 25% 的 key 过期了,则重复删除的过程,直到过期 key 的比例降至 25% 以下。
ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP 是 Redis 的一个参数,默认是 20。如果按照默认参数,不触发算法第二条的话,每秒删除50条数据,并不会对Redis造成太大影响。
但如果反复触发了第二条,Redis会一直删除以释放内存空间,删除操作是阻塞的(在4.0以后可以使用异步线程来减少阻塞影响)。
如果频繁使用带有相同时间参数的EXPIREAT命令设置过期key,这就导致同一秒内有大量key同时过期。
所以可以在时间参数上加一个一定范围内的随机数,这样,既保证了 key 在一个邻近时间范围内被删除,又避免了同时过期造成的压力。
2、文件系统
Redis 会持久化保存数据到磁盘,这个过程要依赖文件系统来完成,所以,文件系统将数据写回磁盘的机制,会直接影响到 Redis 持久化的效率。
而且,在持久化的过程中,Redis 也还在接收其他请求,持久化的效率高低又会影响到 Redis 处理请求的性能。
(1)AOF模式
为了保证数据可靠性,Redis 会采用 AOF 日志或 RDB 快照。其中,AOF 日志提供了三种日志写回策略:no、everysec、always。这三种写回策略依赖文件系统的两个系统调用完成,也就是write和fsync。
write 只要把日志记录写到内核缓冲区,就可以返回了,并不需要等待日志实际写回到磁盘;而 fsync 需要把日志记录写回到磁盘后才能返回,时间较长。下面这张表展示了三种写回策略所执行的系统调用。
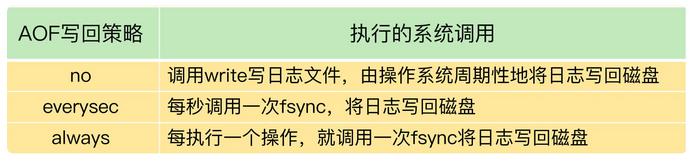 因为everysec允许丢失一秒的操作记录,所以可以使用子线程写日志;而因为always不允许丢失记录,所以不能使用子线程。
因为everysec允许丢失一秒的操作记录,所以可以使用子线程写日志;而因为always不允许丢失记录,所以不能使用子线程。
虽然fsync可以在子线程中执行,但如果上一次的fsync还没有执行完,主线程又来了新的fsync指令,则主线程会被阻塞。(比如当AOF文件不断增大,需要进行AOF重写。这时需要大量的IO操作,很容易造成这种情况)
解决办法
首先检查Redis配置文件中的apendfsync配置项,该配置项表明了Redis采用的是那种AOF写回策略。
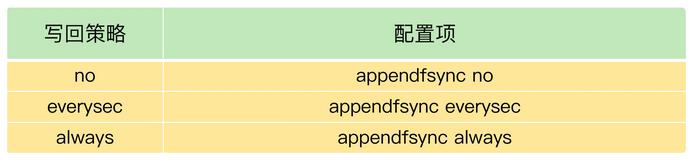 如果使用了everysec或always配置,就需要确认下业务方对数据可靠性的要求。
如果使用了everysec或always配置,就需要确认下业务方对数据可靠性的要求。
如果业务应用对延迟非常敏感,但同时允许一定量的数据丢失,那么,可以把配置项 no-appendfsync-on-rewrite 设置为 yes,如下所示:
no-appendfsync-on-rewrite yes
这个配置项设置为 yes 时,表示在 AOF 重写时,不进行 fsync 操作。也就是说,Redis 实例把写命令写到内存后,不调用后台线程进行 fsync 操作,就可以直接返回了。
3、操作系统
Redis 是内存数据库,内存操作非常频繁,所以,操作系统的内存机制会直接影响到 Redis 的处理效率。比如说,如果 Redis 的内存不够用了,操作系统会启动 swap 机制,这就会直接拖慢 Redis。
(1)swap操作
正常情况下,Redis 的操作是直接通过访问内存就能完成,一旦 swap 被触发了,Redis 的请求操作需要等到磁盘数据读写完成才行。而且,和我刚才说的 AOF 日志文件读写使用 fsync 线程不同,swap 触发后影响的是 Redis 主 IO 线程,这会极大地增加 Redis 的响应时间。
通常,触发 swap 的原因主要是物理机器内存不足,对于 Redis 而言,有两种常见的情况:
- Redis 实例自身使用了大量的内存,导致物理机器的可用内存不足;
- 和 Redis 实例在同一台机器上运行的其他进程,在进行大量的文件读写操作。文件读写本身会占用系统内存,这会导致分配给 Redis 实例的内存量变少,进而触发 Redis 发生 swap。
解决办法
增加机器内存或使用Redis集群
我们可以先检查Redis的进程号,之后再检查进程的swap情况
$ redis-cli info | grep process_id
process_id: 5332
然后,进入 Redis 所在机器的 /proc 目录下的该进程目录中:
$ cd /proc/5332
最后,运行下面的命令,查看该 Redis 进程的使用情况。在这儿,我只截取了部分结果:
$cat smaps | egrep '^(Swap|Size)'
Size: 584 kB
Swap: 0 kB
Size: 4 kB
Swap: 4 kB
Size: 4 kB
Swap: 0 kB
Size: 462044 kB
Swap: 462008 kB
Size: 21392 kB
Swap: 0 kB
一旦发生内存 swap,最直接的解决方法就是增加机器内存。如果该实例在一个 Redis 切片集群中,可以增加 Redis 集群的实例个数,来分摊每个实例服务的数据量,进而减少每个实例所需的内存量。
(2)内存大页
虽然内存大页可以给 Redis 带来内存分配方面的收益,但是,不要忘了,Redis 为了提供数据可靠性保证,需要将数据做持久化保存。这个写入过程由额外的线程执行,所以,此时,Redis 主线程仍然可以接收客户端写请求。客户端的写请求可能会修改正在进行持久化的数据。在这一过程中,Redis 就会采用写时复制机制,也就是说,一旦有数据要被修改,Redis 并不会直接修改内存中的数据,而是将这些数据拷贝一份,然后再进行修改。
如果采用了内存大页,那么,即使客户端请求只修改 100B 的数据,Redis 也需要拷贝 2MB 的大页。相反,如果是常规内存页机制,只用拷贝 4KB。两者相比,你可以看到,当客户端请求修改或新写入数据较多时,内存大页机制将导致大量的拷贝,这就会影响 Redis 正常的访存操作,最终导致性能变慢。
那该怎么办呢?很简单,关闭内存大页,就行了。
首先,我们要先排查下内存大页。方法是:在 Redis 实例运行的机器上执行如下命令:
cat /sys/kernel/mm/transparent_hugepage/enabled
如果执行结果是 always,就表明内存大页机制被启动了;如果是 never,就表示,内存大页机制被禁止。
执行下面的命令可以取消内存大页:
echo never /sys/kernel/mm/transparent_hugepage/enabled
小结
- 获取 Redis 实例在当前环境下的基线性能。
- 是否用了慢查询命令?如果是的话,就使用其他命令替代慢查询命令,或者把聚合计算命令放在客户端做。
- 是否对过期 key 设置了相同的过期时间?对于批量删除的 key,可以在每个 key 的过期时间上加一个随机数,避免同时删除。
- 是否存在 bigkey? 对于 bigkey 的删除操作,如果你的 Redis 是 4.0 及以上的版本,可以直接利用异步线程机制减少主线程阻塞;如果是 Redis 4.0 以前的版本,可以使用 SCAN 命令迭代删除;对于 bigkey 的集合查询和聚合操作,可以使用 SCAN 命令在客户端完成。
- Redis AOF 配置级别是什么?业务层面是否的确需要这一可靠性级别?如果我们需要高性能,同时也允许数据丢失,可以将配置项 no-appendfsync-on-rewrite 设置为 yes,避免 AOF 重写和 fsync 竞争磁盘 IO 资源,导致 Redis 延迟增加。当然, 如果既需要高性能又需要高可靠性,最好使用高速固态盘作为 AOF 日志的写入盘。
- Redis 实例的内存使用是否过大?发生 swap 了吗?如果是的话,就增加机器内存,或者是使用 Redis 集群,分摊单机 Redis 的键值对数量和内存压力。同时,要避免出现 Redis 和其他内存需求大的应用共享机器的情况。
- 在 Redis 实例的运行环境中,是否启用了透明大页机制?如果是的话,直接关闭内存大页机制就行了。
- 是否运行了 Redis 主从集群?如果是的话,把主库实例的数据量大小控制在 2~4GB,以免主从复制时,从库因加载大的 RDB 文件而阻塞。
- 是否使用了多核 CPU 或 NUMA 架构的机器运行 Redis 实例?使用多核 CPU 时,可以给 Redis 实例绑定物理核;使用 NUMA 架构时,注意把 Redis 实例和网络中断处理程序运行在同一个 CPU Socket 上。
以上是关于Redis学习笔记1819——波动的响应延迟:如何应对变慢的Redis的主要内容,如果未能解决你的问题,请参考以下文章