Java全栈数据库技术:2.数据库之Mysql下
Posted new nm个对象
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java全栈数据库技术:2.数据库之Mysql下相关的知识,希望对你有一定的参考价值。
第七章 关联查询(联合查询,多表联查)
7.0 笛卡尔积运算
表和表之间是如何关联的?——》通过笛卡儿积运算(将两张表里任意两条记录组合在一起形成新
的记录,最终生成一张大的表的过程)
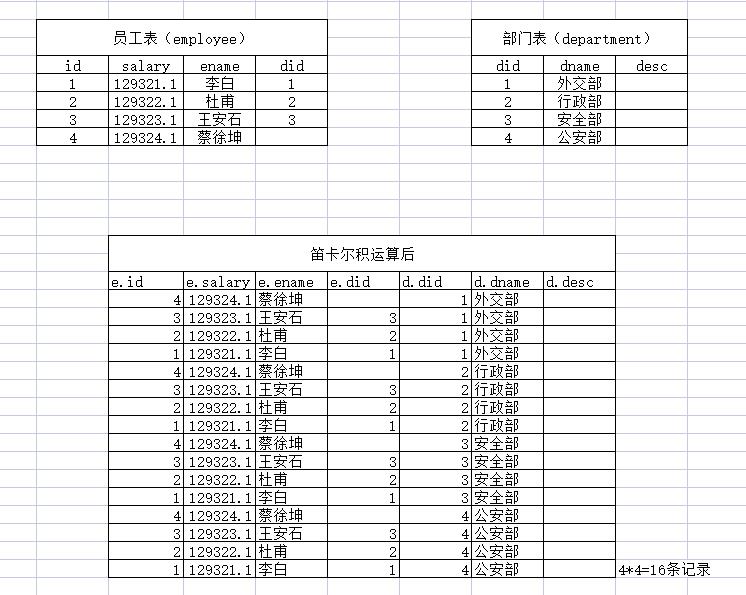
而mysql中的关联查询就是将多张表笛卡尔积运算后的结果中筛选出需要的记录。
7.1 关联查询的七种结果

(0)原始数据
(1)A∩B

(2)A

(3)A - A∩B

(4)B

(5)B - A∩B

(6)A ∪ B

(7)A∪B- A∩B 或者 (A - A∩B) ∪ (B - A∩B)

7.2 如何实现?
(1)内连接
(2)外连接:左外连接、右外连接、全外连接(mysql使用union代替全外连接)
1、内连接:实现A∩B
只返回满足关联条件的记录
# sql99标准,关联条件用on来设置,筛选条件用where来设置
select 字段列表
from A表 [A表别名] inner join B表 [B表别名]
on 关联条件
where 等其他子句;
或
# sql92标准,关联条件和筛选条件都用where来设置
select 字段列表
from A表 [A表别名] , B表 [B表别名]
where 关联条件 and 等其他子句;
代码示例:
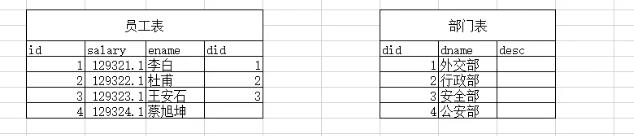
#查询员工的姓名和他所在的部门的名称
#员工的姓名在employee表中
#部门的名称在department表中
select e.ename as "员工姓名",d.dname as "部门姓名" from employee e INNER JOIN department d on e.did=d.did; # 方式1
select e.ename as "员工姓名",d.dname as "部门姓名" from employee e,department d where e.did=d.did; # 方式2
# 结果:
+--------------+--------------+
| 员工姓名 | 部门姓名 |
+--------------+--------------+
| 李白 | 外交部 |
| 杜甫 | 行政部 |
| 王安石 | 安全部 |
+--------------+--------------+
#查询薪资高于20000的男员工的姓名和他所在的部门的名称
SELECT ename "员工的姓名",dname "部门名称"
FROM t_employee INNER JOIN t_department
ON t_employee.did = t_department.did
WHERE salary>20000 AND gender = '男'
2、左外连接:实现A和(A - A∩B)
指的是除了返回满足关联条件的结果集以外,还会把左边的那张表完整的展示出来,
右边的那张表不满足关联条件的字段位置补空值(null)
#实现查询结果是A
select 字段列表
from A表 left join B表
on 关联条件
where 等其他子句;
#实现A - A∩B
select 字段列表
from A表 left join B表
on 关联条件
where 从表关联字段 is null and 等其他子句;
代码示例:
#查询所有员工的姓名和他所在的部门的名称
select e.ename as "员工姓名",d.dname as "部门姓名"
from employee e left join department d
on e.did=d.did;
+--------------+--------------+
| 员工姓名 | 部门姓名 |
+--------------+--------------+
| 李白 | 外交部 |
| 杜甫 | 行政部 |
| 王安石 | 安全部 |
| 蔡徐坤 | NULL |
+--------------+--------------+
#查询所有没有部门的员工
select e.ename as "员工姓名",d.dname as "部门姓名"
from employee e left join department d
on e.did=d.did
where e.did is null;
+--------------+--------------+
| 员工姓名 | 部门姓名 |
+--------------+--------------+
| 蔡徐坤 | NULL |
+--------------+--------------+
3、右外连接:实现B和(B - A∩B)
指的是除了返回满足关联条件的结果集以外,还会把右边的那张表完整的展示出来,
左边的那张表不满足关联条件的字段位置补空值(null)
#实现查询结果是B
select 字段列表
from A表 right join B表
on 关联条件
where 等其他子句;
#实现B - A∩B
select 字段列表
from A表 right join B表
on 关联条件
where 从表关联字段 is null and 等其他子句;
代码示例:
#查询所有部门的名称,以及所有部门下的员工姓名
select e.ename as "员工姓名",d.dname as "部门姓名"
from employee e right join department d
on e.did=d.did;
+--------------+--------------+
| 员工姓名 | 部门姓名 |
+--------------+--------------+
| 李白 | 外交部 |
| 杜甫 | 行政部 |
| 王安石 | 安全部 |
| NULL | 公安部 |
+--------------+--------------+
#查询那些没有员工属于它的部门名称
select e.ename as "员工姓名",d.dname as "部门姓名"
from employee e right join department d
on e.did=d.did
where e.did is null;
+--------------+--------------+
| 员工姓名 | 部门姓名 |
+--------------+--------------+
| NULL | 公安部 |
+--------------+--------------+
4、全外连接:实现(A∪B)和(A∪B - A∩B)
- 指的是除了返回满足关联条件的结果集以外,还会把两边的表完整的展示出来,
两边不满足关联条件的字段位置补空值(null) - mysql中使用union 将两个结果集合并起来实现全外了,连接
#实现查询结果是A∪B
#用左外的A union 右外的B
select 字段列表
from A表 left join B表
on 关联条件
where 等其他子句
union
select 字段列表
from A表 right join B表
on 关联条件
where 等其他子句;
#实现A∪B - A∩B
#使用左外的 (A - A∩B) union 右外的(B - A∩B)
select 字段列表
from A表 left join B表
on 关联条件
where 从表关联字段 is null and 等其他子句
union
select 字段列表
from A表 right join B表
on 关联条件
where 从表关联字段 is null and 等其他子句
代码示例:
#查询所有员工姓名,所有部门名称,包括没有员工的部门,和没有部门的员工
select e.ename as "员工姓名",d.dname as "部门姓名"
from employee e left join department d
on e.did=d.did
union
select e.ename as "员工姓名",d.dname as "部门姓名"
from employee e right join department d
on e.did=d.did;
+--------------+--------------+
| 员工姓名 | 部门姓名 |
+--------------+--------------+
| 李白 | 外交部 |
| 杜甫 | 行政部 |
| 王安石 | 安全部 |
| 蔡徐坤 | NULL |
| NULL | 公安部 |
+--------------+--------------+
#查询那些没有部门的员工姓名和所有没有员工的部门名称
#没有部门的员工
SELECT *
FROM t_employee LEFT JOIN t_department
ON t_employee.did = t_department.did
WHERE t_employee.did IS NULL
UNION
#所有没有员工的部门
select e.ename as "员工姓名",d.dname as "部门姓名"
from employee e left join department d
on e.did=d.did where e.did is null
union
select e.ename as "员工姓名",d.dname as "部门姓名"
from employee e right join department d
on e.did=d.did where e.did is null;
+--------------+--------------+
| 员工姓名 | 部门姓名 |
+--------------+--------------+
| 蔡徐坤 | NULL |
| NULL | 公安部 |
+--------------+--------------+
7.3 特殊的关联查询:自连接
两个关联查询的表是同一张表,通过取别名的方式来虚拟成两张表。
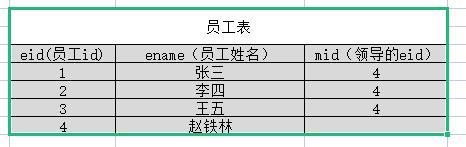
如上图所示:员工表中有mid字段,表示该员工领导的id编号。即mid是eid字段的外键
select 字段列表
from 表名 别名1 inner/left/right join 表名 别名2
on 别名1.关联字段 = 别名2的关联字段
where 其他条件
代码示例:
查询员工的id,姓名,以及领导的姓名。
# 创建表
create table employee2(
eid int primary key,
ename char(10),
mid int,
foreign key(mid) references employee2(eid)
);
# 插入数据
insert into employee2(eid,ename) values(4,"赵铁林");
insert into employee2 values(1,"张三",4),(2,"李四",4),(3,"王五",4);
select * from employee2;
+-----+-----------+------+
| eid | ename | mid |
+-----+-----------+------+
| 1 | 张三 | 4 |
| 2 | 李四 | 4 |
| 3 | 王五 | 4 |
| 4 | 赵铁林 | NULL |
+-----+-----------+------+
#查询员工的编号,姓名,以及员工领导的名字
select e.eid as "员工编号",e.ename as "员工姓名",m.ename as "领导姓名"
from employee2 e inner join employee2 m
on e.mid=m.eid; # 注意:这里的关联条件应该是`员工表的mid=领导表的员工id`
+--------------+--------------+--------------+
| 员工编号 | 员工姓名 | 领导姓名 |
+--------------+--------------+--------------+
| 1 | 张三 | 赵铁林 |
| 2 | 李四 | 赵铁林 |
| 3 | 王五 | 赵铁林 |
+--------------+--------------+--------------+
#表的别名不要加"",给列取别名,可以用"",列的别名不使用""也可以,但是要避免包含空格等特殊符号。
7.4 三表查询
三表查询本质跟两表查询一样,它是先将两表进行关联查询后的结果,再跟第三张表进行关联查询。
如下:学生表和教室表、教师表都关联在了一起。
需求:查找所有学生的姓名、上课的教室名、上课的老师名

select s.sname,c.cname,t.tname
from student s INNER JOIN class c
on s.cid=c.cid
INNER JOIN teacher t # 使用前面已经关联后的表与第三张teacher表进行关联
on s.tid=t.tid;
+--------+--------------+-----------+
| sname | cname | tname |
+--------+--------------+-----------+
| 张三 | JAVA班 | 李老师 |
| 李四 | JAVA班 | 黄老师 |
| 王五 | 大数据班 | 赵老师 |
| 赵六 | 大前端班 | 马老师 |
| 黑七 | 大前端班 | 田老师 |
| 吴八 | JAVA班 | 田老师 |
+--------+--------------+-----------+
第八章 select语句的七大子句
8.1 七大子句书写顺序
(1)from:从哪些表中筛选
(2)on:关联多表查询时,去除笛卡尔积
(3)where:从表中筛选的条件
(4)group by:分组依据
(5)having:在统计结果中再次筛选
(6)order by:排序
(7)limit:分页
必须按照(1)-(7)的顺序【编写】子句。
连续原始数据如下:

# 查找每个职位的男生人数
select e_pid as "职位id",count(*) as "人数"
from employ3
where sex="男"
group by e_pid;
+----------+--------+
| 职位id | 人数 |
+----------+--------+
| 1 | 4 |
| 2 | 2 |
| 3 | 2 |
| 4 | 2 |
| 5 | 2 |
| 11 | 1 |
+----------+--------+
# 查找男生人数大于等于2的职位,并按照人数降序排列
select e_pid as "职位id",count(*) as "人数"
from employ3
where sex="男"
group by e_pid
having count(*)>=2
order by count(*) desc;
+----------+--------+
| 职位id | 人数 |
+----------+--------+
| 1 | 4 |
| 2 | 2 |
| 3 | 2 |
| 4 | 2 |
| 5 | 2 |
+----------+--------+
# 查找男生人数大于等于2的职位,并按照人数降序排列,并分页显示(每页只能显示2条,我要第2页)
select e_pid as "职位id",count(*) as "人数"
from employ3
where sex="男"
group by e_pid
having count(*)>=2
order by count(*) desc
limit 2,2; # 第一个2表示跳过前面多少条记录,第二个2表示需要显示多少条记录
+----------+--------+
| 职位id | 人数 |
+----------+--------+
| 3 | 2 |
| 4 | 2 |
+----------+--------+
8.2 group by与分组函数

-
group by是将所有的数据,按照一定条件进行分组,组内再进行处理。 -
group by需要放到where的后面 -
group by后面的字段最好要是select后面声明过的,不然没有意义select e_pid as "职位id",count(*) as "人数" from employ3 where sex="男" group by e_pid; -
在有
group by的前提下,select后的分组函数(AVG(),SUM(),MAX(),MIN(),COUNT())是对group by分组后的每个组内的数据进行处理,每个组返回一个数据select e_pid as "职位id",count(*) as "人数",avg(salary) as "平均工资" from employ3 where sex="男" group by e_pid; +----------+--------+--------------+ | 职位id | 人数 | 平均工资 | +----------+--------+--------------+ | 1 | 4 | 20516.227500 | | 2 | 2 | 20250.290000 | | 3 | 2 | 15282.340000 | | 4 | 2 | 15348.105000 | | 5 | 2 | 13932.080000 | | 11 | 1 | 4000.330000 | +----------+--------+--------------+ -
包含在 GROUP BY 子句中的列也可以不必包含在SELECT 列表中
SELECT AVG(salary) FROM employees GROUP BY department_id ; -
可以使用多个字段来进行分组
SELECT department_id dept_id, job_id, SUM(salary) FROM employees GROUP BY department_id, job_id ;
8.3 having与分组函数
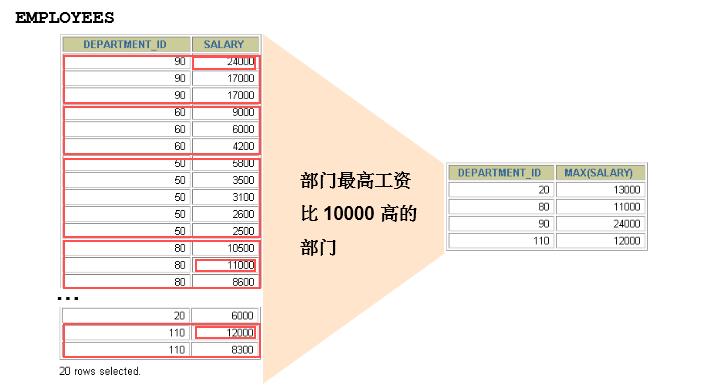
having是对group by分组后的结果再次进行筛选,需要放在group by之后having后面可以直接使用select后面的字段或者分组函数结果来进行筛选,也可以直接使用分组函数select e_pid as "职位id",count(*) as "人数" from employ3 where sex="男" group by e_pid having count(*)>=2 and e_pid%2=0; +----------+--------+ | 职位id | 人数 | +----------+--------+ | 2 | 2 | | 4 | 2 | +----------+--------+
-
获取最小工资小于2000的职位
-- min(sal) job min(sal)<2000 -- 获取各个职位的最小工资 select job,min(sal) from emp group by job order by min(sal) -- 获取各个职位的最小工资,筛选出小于2000的 select job,min(sal) from emp group by job having min(sal)<2000 order by min(sal) -- 统计[人数小于4的]部门的平均工资。 select deptno,count(1),avg(sal) from emp group by deptno having count(1)<4 -- 统计各部门的最高工资,排除最高工资小于3000的部门。 select deptno,max(sal) from emp group by deptno having max(sal) >=3000
having与where的区别?
(1)where是从表中筛选的条件,而having是分组(统计)结果中再次筛选
(2)where后面不能加“分组/聚合函数”,而having后面可以跟分组函数
#统计部门平均工资高于8000的部门和平均工资
SELECT department_id, AVG(salary)
FROM employees
WHERE AVG(salary) > 8000 #错误
GROUP BY department_id;
#统计每一个部门,薪资高于10000元的女员工的数量,显示人数超过1人
SELECT did,COUNT(*)
FROM t_employee
WHERE gender ='女' AND salary>10000
GROUP BY did
HAVING COUNT(*) > 1;
8.4 order by
-
order by:后面跟上字段或者分组函数,表示按照相关内容进行排序
-
降序:desc
-
升序:要么默认,要么加asc
# 获取男生人数大于2的职位,并按照人数降序排列
select e_pid as "职位id",count(*) as "人数"
from employ3
where sex="男"
group by e_pid
having count(*)>=2
order by count(*) desc
+----------+--------+
| 职位id | 人数 |
+----------+--------+
| 1 | 4 |
| 2 | 2 |
| 3 | 2 |
| 4 | 2 |
| 5 | 2 |
+----------+--------+
8.5 limit
limit:分页显示
limit m,n
m = 跳过的记录数。一般为(需要显示第几页 - 1)*每页的数量
n = 每页的数量
代码示例:
/*
每页显示2条 展示第三页
*/
select * from emp limit 4,2;
求员工的姓名,薪水,部门编号,部门名称,工作编号,工作名称,按照薪水排序,每页显示3条显示第4页
SELECT
emp.`ename`,
emp.`salary`,
emp.`department_id`,
dept.`dname`,
dept.`did`,
job.`job_name`
FROM
t_employee emp
JOIN t_department dept ON emp.`department_id` = dept.`did`
JOIN t_job job ON emp.`job_id` = job.`job_id`
ORDER BY
emp.`salary`
LIMIT 9,
3;
第九章 子查询
嵌套在另一个查询中的查询,根据位置不同,分为:where型,from型,exists型。注意:不管子查询在哪里,子查询必须使用()括起来。
1、where型
①子查询是单值结果,那么可以对其使用(=,>等比较运算符)
②子查询是多值结果,那么可对其使用(【not】in(子查询结果),或 >all(子查询结果),或>=all(子查询结果),<all(子查询结果),<=all(子查询结果),或 >any(子查询结果),或>=any(子查询结果),<any(子查询结果),<=any(子查询结果))
查询全公司最高工资的员工信息
select * from 员工表 where 薪资 = (select max(薪资) from 员工表);
select * from 员工表 where 薪资 > all(select salary from 员工表 where 员工编号 in(.以上是关于Java全栈数据库技术:2.数据库之Mysql下的主要内容,如果未能解决你的问题,请参考以下文章