04-flink-1.10.1-流处理WordCount代码里控制并行度
Posted 逃跑的沙丁鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了04-flink-1.10.1-流处理WordCount代码里控制并行度相关的知识,希望对你有一定的参考价值。
接续03-flink-1.10.1-流处理WordCount
1 为什么同一个单词总是在同一个线程里打印
输入单词
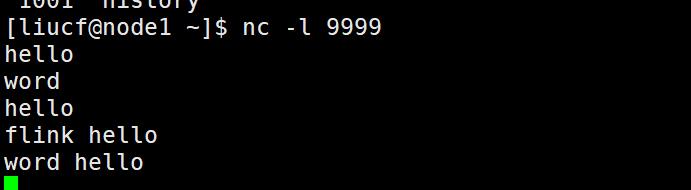
输出
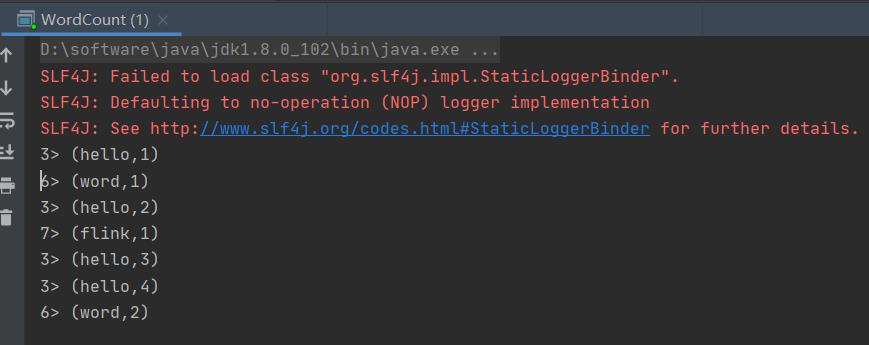
可见hello这个单词多次输入总是在线程好3里输出这是为什么呢?
这是因为flink实际后台是对单词分别做了hash处理,通过观察应该是先取单词的hash值然后用对处理数据的线程数(并行度)取模/取余的到的索引hello总是会进入线程3打印
2 设置全局并行度参数
/**创建flink流式处理环境*/
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(2)3 flink支持对每一个算子设置并行度
.map((_,1))//DataStream[(String, Int)]
.setParallelism(4)
.keyBy(0)//KeyedStream[(String, Int), Tuple]
.sum(1)//DataStream[(String, Int)]
.setParallelism(2)
/**输出结果,打印到控制台*/
res.print().setParallelism(1)
可见map算子设置的并行度是4,sum算子设置的并行度是2,最后打印设置的并行度是1
不过一般不会这么去设置,但是对于输出部分可能会做特殊设置,比如输出到文件,如果并行写入就出现乱序了。
4 flink从外部命令获取参数
① 引入依赖
import org.apache.flink.api.java.utils.ParameterTool
② 传入args
val paramTool = ParameterTool.fromArgs(args)
③ 提取变量
val ip = paramTool.get(ip) val port = paramTool.getInt(port)
④ 使用变量
val sockerInput: DataStream[String] = env.socketTextStream(ip, port)
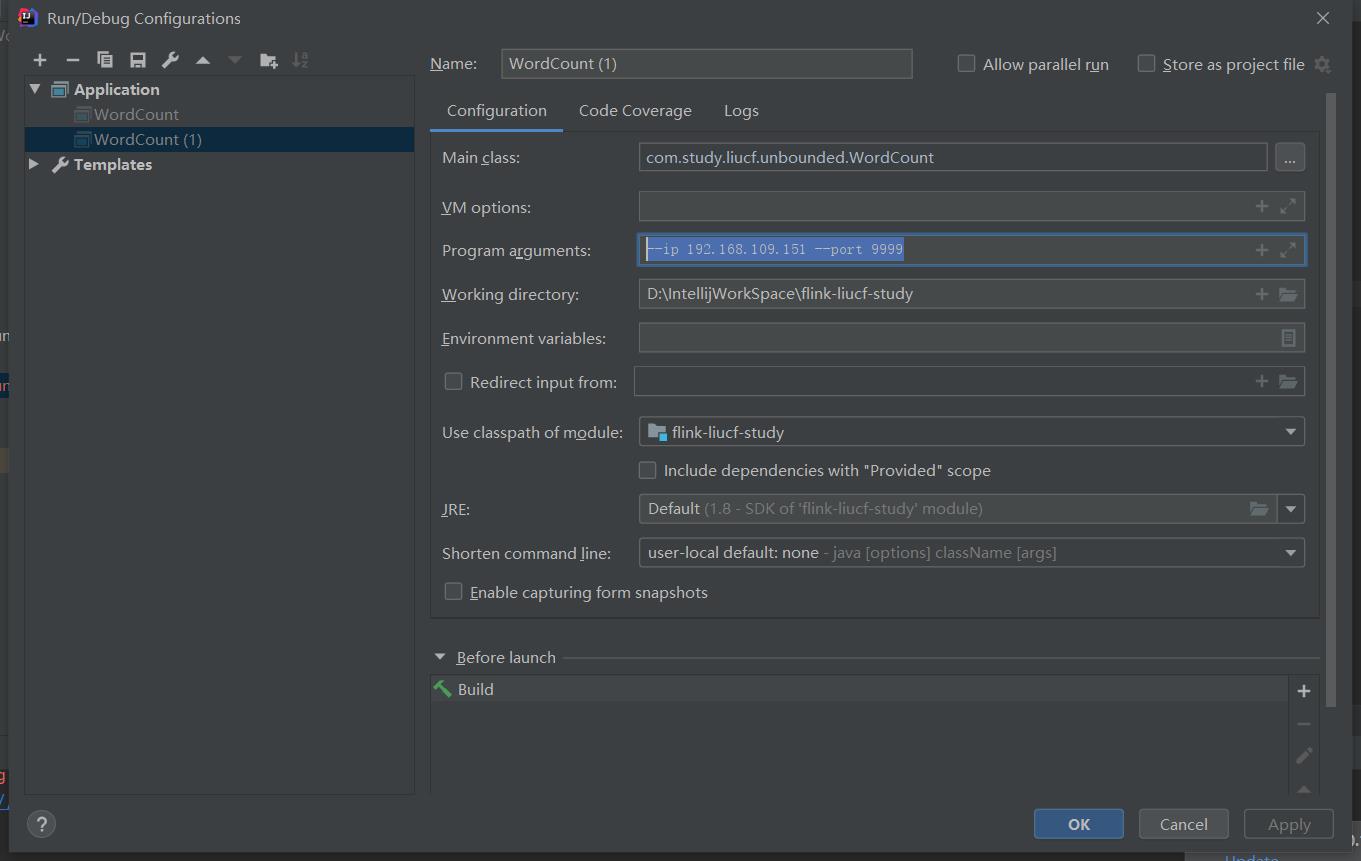
⑤ 传入外部参数
--ip 192.168.109.151 --port 9999
5 完整代码
package com.study.liucf.unbounded
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
/**
* @Author liucf
* @Date 2021/8/16
*/
object WordCount
def main(args: Array[String]): Unit =
/**创建flink流式处理环境*/
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// env.setParallelism(2)
/**flink 从外部命令获取参数*/
val paramTool = ParameterTool.fromArgs(args)
val ip = paramTool.get("ip")
val port = paramTool.getInt("port")
/**监听一个流式输入端口*/
// val sockerInput: DataStream[String] = env.socketTextStream("192.168.109.151", 9999)
val sockerInput: DataStream[String] = env.socketTextStream(ip, port)
/**数据流转换*/
val res : DataStream[(String, Int)] = sockerInput.flatMap(_.split(" ")) //: DataStream[String]
.filter(_.nonEmpty)//: DataStream[String]
//.map(x=>(x,1))
.map((_,1))//DataStream[(String, Int)]
// .setParallelism(4)
.keyBy(0)//KeyedStream[(String, Int), Tuple]
.sum(1)//DataStream[(String, Int)]
// .setParallelism(2)
/**输出结果,打印到控制台*/
res.print()
// .setParallelism(1)
/**启动流式处理*/
env.execute(" liucf wordcoun")
补充:flink是分布流式处理引擎,那么势必会遇到计算乱序的问题,比如单词hello word 第一个单词先输入但是确是最后一个输出的,那么如何解决分布式计算乱序的问题呢?情到时间语义部分关注这个问题。
以上是关于04-flink-1.10.1-流处理WordCount代码里控制并行度的主要内容,如果未能解决你的问题,请参考以下文章