TF-IDF算法:用 Python 提炼财经新闻
Posted Python中文社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TF-IDF算法:用 Python 提炼财经新闻相关的知识,希望对你有一定的参考价值。

在信息爆炸的今天,我们不可能阅读所有的新闻,那么如果我们使用机器学习,特别是tf-idf算法,如何从所有网络上的文本中获得最重要的信息呢?
这篇文章是使用已知的tf-idf算法从网上获取关键信息的一个案例。目的是鼓励你利用它,并将其纳入一些市场投资策略或任何其他用途。
TF-IDF
TF-IDF这个词来自于“术语频率--逆向文档频率”。这项技术的目标是计算一个词在一个文件中出现的次数。
第一部分,也就是TF,计算你看到每个词的次数。然而,当你计算像"a "这样的常用词的值时,这可能会犯一些错误。这类词被称为停止词,它们指的是冠词、代词、助词等等。这些词可以让你建立一个可以理解的句子,但这些并不真正具有意义。因此,由于它们被广泛使用,它们会有一个高的TF。
考虑到这一点,该技术试图用IDF这个词来纠正这个错误。这一部分修改了TF,考虑到一个词在大量文本中的使用次数。从这个意义上说,如果很多文本多次使用一个词,它的Tf将被惩罚,它将被降低。
作为tf-idf结果的一个例子,我们来看看这些句子。"I’m traveling to Paris this week","There will be so many journeys to Paris next week","Paris is supposed to receive a lot of tourists"。假设我们去掉了停顿词,那么Paris这个词在每个句子中的频率1;但是Paris相对于句子中的其他词的重要性是巨大的,因为Paris出现在所有的句子中。
总而言之,这种技术给了我们一个衡量一个词在文本中的重要性的标准。
实际案例
让我们看一个非常简单的案例,使用TF-IDF来识别历史上的主要话题。
数据集
我们从2009年到2020年的几个英文文本中抽取了一组新闻和观点。我们的数据集包含了日期、标题、新闻正文和被提及的股票。在这篇文章中,我们将只使用日期和标题,因为我们的目标是要抓住主要话题。
预处理
当你处理文本时,必须对文本进行处理,以避免模型中的噪点。也就是说,这些文本应该是清晰的,而且格式相同。因此,我们用以下方式处理了我们的原始文本,通过使用python中的nltk库得到了处理后的文本。
所有的字都用小写。
删除数字和首字母。
删除停顿词。
删除标点符号。
词义化。这意味着将该词还原为一个词的词根同义词。由于de输入 "pos",可以确定词根是来自形容词、动词还是名词。
删除常见的词,如“wall street”, “market”, “stock”, “share”, …
import nltk
from nltk.stem importWordNetLemmatizer
import re
stopwords = nltk.corpus.words('english')
lemmatizer = WordNetLemmatizer()
processed_text = re.sub('[^a-zA-Z]', ' ',original_text)
processed_text = processed_text.lower()
processed_text = processed_text.split()
processed_text = [lemmatizer.lemmatize(word, pos='a') for word in processed_text if word notin set(stopwords)]
processed_text = [lemmatizer.lemmatize(word, pos='v') for word in processed_text if word notin set(stopwords)]
processed_text = [lemmatizer.lemmatize(word, pos='n') for word in processed_text if word notin set(stopwords)]
processed_text = ' '.join(processed_text)
processed_text = re.sub('stock', '', processed_text)模型
下一步是创建符合我们目的的模型。因此,我们使用python中的sklearn库。由于我们想知道每个日期的关键信息,我们使用 TfidfVectorizer模型。这允许我们设置关键特征的数量,我们将其设置为8个最大特征。
from sklearn.feature_extraction.text importTfidfVectorizer
tf_idf_model = TfidfVectorizer(max_features=8)
processed_text_tf = tf_idf_model.fit_transform(preprocessed_texts)
tf_idf_values = tf_idf_model.idf_
tf_idf_names = tf_idf_model.get_feature_names()接下来,我们每天用当天数据集中的所有新闻片段来应用这个模型。注意,这个模型不需要训练,因为它是一个确定的算法。通过这种方式,我们得到一组8个代表当天关键信息的词。同样,每个词都有一个tf-idf值,表示它在当天的重要性。
结果
最后,我们将结果总结为以下图表。在这些图表中,出现了模型中的所有相关词汇,在方框中则是相关的新闻。为了澄清结果,第一个图表包含了2019年上半年的信息,第二个图表反映了2019年下半年的情况。
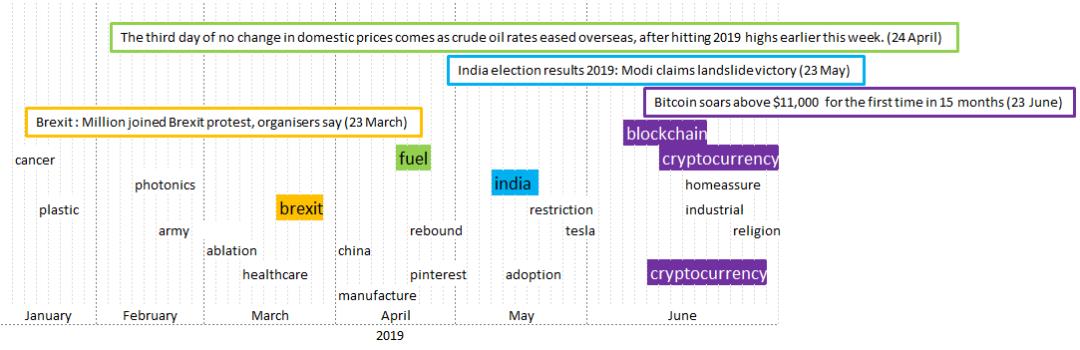
2019年1月至2019年6月的相关议题和相关新闻
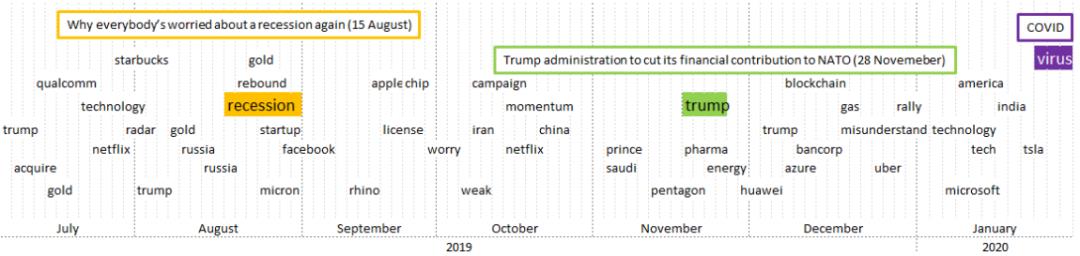
2019年7月至2020年1月的相关议题和相关新闻
总结
该模型似乎可以从大量的新闻作品中提取出最重要的词语。最大的挑战是如何利用这个模型提炼信息后,制定一个有利于我们投资的策略。

- 点击下方阅读原文加入社区会员 -
以上是关于TF-IDF算法:用 Python 提炼财经新闻的主要内容,如果未能解决你的问题,请参考以下文章
关键字提取算法TF-IDF和TextRank(python3)————实现TF-IDF并jieba中的TF-IDF对比,使用jieba中的实现TextRank
如何使用 NLTK 正则表达式模式用 UP/DOWN 指标注释财经新闻?
翻译: 词频逆文档频率TF-IDF算法介绍及实现 手把手用python从零开始实现