Resilience4j 源码解析:浅析框架设计原理
Posted mickjoust
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Resilience4j 源码解析:浅析框架设计原理相关的知识,希望对你有一定的参考价值。
- 前言
- 弹性模式(Resiliency patterns)
- Sentinel Vs Hystrix Vs Resilience4j
- 事件驱动
- 小结
相关文章:
- Resilience4j 源码解析(1):简介及调试环境搭建
- Resilience4j 源码解析(2):浅析框架设计原理
- Resilience4j 源码解析(3):限流模块 RateLimiter 与 常见限流算法
前言
有同学会疑惑,为什么源码解析,写了快两篇,却一点也看不到源码的影子?
如果只是为了源码解析而解析,大可不必想清楚为什么(why),只要钻研(how)就行,那直接去读官方文档其实更好。
可现实却是:看了无数篇源码解析,却依然在实践中抓不住重点。
为什么?
原因很简单:不知道工具从何而来以及为了解决什么场景下的问题。
更多时候,只是听大家都说它很好,于是就选它,然后走在填坑的大道上。
其实在源码分析前,最应该问的一个问题是:
这个工具到底准备解决什么样的问题?
弹性模式(Resilience patterns)
什么是弹性模式?
弹性是指系统能够在发生故障后进行恰当处理,然后恢复正常。
我们一定在生产环境遇见过如下问题:
- 大促时瞬间洪峰流量导致系统超出最大负载、load 飙高、系统崩溃,导致用户无法下单
- “活动”热点商品击穿缓存,导致DB被打垮,正常流量被严重挤占
- 调用端被不稳定服务拖垮,线程池被占满,导致整个调用链路卡死
而我们最常想到的解决手段就是:重启,然后加服务器。
这样的确没问题,但是,你也一定听说过这样一种设计:
- 自我修复型设计(Design for self healing)
分布式系统中时常会发生故障。软件会发生故障。硬件也会故障。 网络也有可能发生暂时性故障。 在极少数情况下,整个服务或区域都可能会遇到中断(实际上电商大促时概率被放大了很多倍)。
自我修复型设计的原则是:将可能发生的故障放到设计中来,并采取相应手段解决它们。
然后,就出现了这些细分的设计模式:
- 隔离(Bulkhead):将应用程序的元素隔离到池中,如果其中一个失败,其他应用程序将继续运行。
- 断路器(Circuit Breaker):处理连接到远程服务或资源时,需要花费一定时间才能解决的故障。
- 补偿交易(Compensating Transaction):撤消通过一系列步骤执行的业务,这些步骤共同定义了最终一致性的操作。
- 节点存活监控(Health Endpoint Monitoring):在应用程序中实施功能检查,以使外部工具可以定期通过暴露的节点访问它们。
- 领导选举(Leader Election):通过选举一个实例作为负责管理其他实例的负责人,来协调分布式应用程序中一组协作任务实例所执行的操作。
- 基于队列的负载均衡(Queue-Based Load Leveling):使用队列作为任务和它所调用的服务之间的缓冲区,以平滑间歇性的提供负载。
- 重试(Retry):通过透明地重试先前失败的操作,使应用程序在尝试连接到服务或网络资源时能够处理预期的临时故障。
- 分布式调度(Scheduler Agent Supervisor):跨一组分布式服务和其他远程资源协调一组操作
我猜想,Resilience4j 这个名字的灵感应该就是来自于单词Resilience(弹性、复原的意思)加上4j(专供Java使用的缩写)。
Sentinel Vs Hystrix Vs Resilience4j
明白了设计原理后,我们用阿里的Sentinel、奈飞的Hystrix对比数据来看模块设计,其实就能很清晰的看出 Resilience4j 的模块有哪些,即便还没有看源码,也大概能想到和上面的设计模式有很大的相关性。
其实同类组件的对比,能很好的反应我们要研究的框架的特性,特别是开源框架,并不是功能越多越好,功能越多意味着定制性更强,使用的时候未必更好,特别是对于中小团队,可能一年的年都够不上淘宝双十一半天的量。相反,可能还需要花大力气去维护不必要的功能。
回到正题。来看下面的对比数据:
| - | Sentinel | Hystrix | Resilience4j |
|---|---|---|---|
| 隔离策略 | 信号量隔离(并发线程数限流) | 线程池隔离/信号量隔离 | 信号量隔离 |
| 熔断降级策略 | 基于响应时间、异常比率、异常数等 | 异常比率模式、超时熔断 | 基于异常比率、响应时间 |
| 实时统计实现 | 滑动窗口(LeapArray) | 滑动窗口(基于 RxJava) | Ring Bit Buffer |
| 动态规则配置 | 支持多种配置源 | 支持多种数据源 | 有限支持 |
| 扩展性 | 丰富的 SPI 扩展接口 | 插件的形式 | 接口的形式 |
| 基于注解的支持 | 支持 | 支持 | 支持 |
| 限流 | 基于 QPS,支持基于调用关系的限流 | 有限的支持 | Rate Limiter |
| 集群流量控制 | 支持 | 不支持 | 不支持 |
| 流量整形 | 支持预热模式、匀速排队模式等多种复杂场景 | 不支持 | 简单的 Rate Limiter 模式 |
| 系统自适应保护 | 支持 | 不支持 | 不支持 |
| 控制台 | 提供开箱即用的控制台,可配置规则、查看秒级监控、机器发现等 | 简单的监控查看 | 不提供控制台,可对接其它监控系统 |
| 多语言支持 | Java / C++ | Java | Java |
| 开源社区状态 | 活跃 | 停止维护 | 较活跃 |
这组数据怎么看都是阿里的组件更好,但是我们也能看到 Resilience4j 有很大的二次开发的价值,很适合喜欢创新的团队去自研,支持更多功能。关于Sentinel的详细分析以后也会涉及到。
事件驱动架构
Resilience4j 框架很好的实现了事件驱动架构的设计。在后面的源码分析里,除了它优雅的函数式编程风格和严格的模块组织外,最让人印象深刻的就是他的设计者规范的实现了基于事件驱动的架构设计,这是非常值得学习的地方之一。
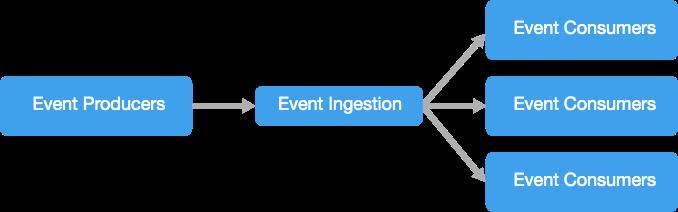
这里简单介绍下什么是事件驱动架构?
事件驱动的架构由两个元素组成:
- 生成事件流的事件「生成者」
- 侦听事件的事件「消费者」
事件驱动的架构可以使用两种模式:
- 发布/订阅: 消息框架保持了对订阅的跟踪。 事件发布后,它会将事件发送给每位订阅者。 订阅者在接收事件后,便无法重新发送,新订阅者也看不见此事件。
- 事件流式处理: 事件会写入日志。 事件是(在分区中)经过严格排序的,而且具有持久性。 客户端不会订阅流,但是客户端可以读取该流的任何部分。 客户端负责提升它在流中的位置。 这意味着客户端可以随时加入,并可以重播事件。
在使用时,有一些常见的变化:
- 简单事件处理。 事件会立即触发使用者中的某项操作。 例如,可以将应用与事件服务总线(Event Bus)配合使用,每当消息发布到服务总线主题后,函数便开始执行。
- 复杂事件处理。 使用者使用 Spark 之类的技术处理一系列事件,寻找事件数据中的模式。 例如,如果流量超过特定阈值,便可聚合在某个时间范围内从服务读取信息,并生成新通知。
- 事件流处理。 使用 Kafka 等数据流平台作为管道引入事件并将其转送到流处理器。 此流处理器可处理或转换流。 不同应用程序子系统可能有多种流处理器。
其实到这里,我们可以简短回答开头的问题:
Resilience4j 就是一个为了解决大规模分布式服务在接收到大量请求服务发生节点故障时,能够快速恢复服务的策略方法。
小结
本文对 Resilience4j 的架构做了一个简要分析,介绍了弹性模式设计理念,以及事件驱动架构时怎么回事,下面的文章我们就要开始进去主题,从流控限流开始讲起。
参考文章
- Circuit Breaker Pattern: Migrating From Hystrix to Resilience4J
- Microservices Circuit-Breaker Pattern Implementation: Istio vs Hystrix
- Pattern: Circuit Breaker
- 自我修复型设计
- 常用限流降级组件对比
以上是关于Resilience4j 源码解析:浅析框架设计原理的主要内容,如果未能解决你的问题,请参考以下文章