测试沉思录14. 性能测试中的系统资源分析之一:CPU
Posted 毕小烦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了测试沉思录14. 性能测试中的系统资源分析之一:CPU相关的知识,希望对你有一定的参考价值。
作者:马海琴 编辑:毕小烦
在日常的性能测试中,我们除了关注应用本身的性能,比如服务的响应时间、TPS 等,也需要关注服务器本身的资源使用情况,比如 CPU、内存、磁盘、网络等。当然,不光要分析服务器资源,评估应用运行所需要的资源情况,也需要分析服务器资源的异常,找到应用可能存在的问题或者优化方向。
具体应该怎么做呢?本系列文章介绍了 CPU、内存、磁盘、网络的基础知识以及问题的分析方式。本文是第一篇,讲 CPU。
一. CPU
CPU 是Central Processing Unit的缩写,中文也叫中央处理器。它是一块超大规模的集成电路,是硬件系统的核心,是一台计算机的运算核心和控制核心。它的功能主要是解释计算机指令以及处理计算机软件中的数据,能完成算数运算、逻辑运算及控制功能。CPU 就像人体的大脑一样,关键且重要。
CPU 作为系统的关键指标,在任何场合都不能忽视它的重要性。应用上线要评估 CPU 的使用核数,进行合理的资源配置;服务上线之后,也需要时刻监控 CPU 的使用情况,以防资源耗尽影响系统的稳定性;性能测试时,我们更是需要密切关注 CPU 的变化,寻找导致 CPU 异常的场景。
在线上观测或者性能测试当中,当系统出现 CPU 异常或者与预期不一致时,我们可以通过分析 CPU 的具体使用情况,进而找到问题的所在。一般情况下,死锁、频繁的 GC、频繁的上下文切换、线程执行报错、计算密集这些原因都会使 CPU 的使用率飙升。
1.1 怎样通过 CPU 指标定位问题?
什么样 CPU 行为是异常的?
一般情况下,对于新系统,我们一般期望系统的平均可用 CPU 不少于 20%,建议 CPU 使用率在 70% 以下;老系统在用户活跃度没有明显增加的情况下,CPU 较日常同比增幅过大,或者直接飙升超过 80% 。
如何找到 CPU 异常的原因?
分 3 步。
STEP 1. 找到导致 CPU 异常的进程
通过top命令检测到某进程 CPU 占用较高,其中PID即为进程号,我们可以通过这个进程号进一步获取需要的信息。

当然如果已知具体服务,可以直接使用ps -ef | grep pname[进程名称]查看进程号。

STEP 2. 通过进程号获取线程号
通过命令top -Hp pid[进程ID]查看进程中各线程的使用情况,找到 CPU 占用最高的线程号,其中PID即为线程号。
如:

再通过命令printf '0x%x\\n' nid[线程ID]将线程号转化为十六进制。
如:

STEP 3. 通过进程号查看进程的堆栈信息,并使用线程号定位指定的线程
定位异常可使用命令:
$ jstack pid[进程ID] | grep nid[十六进制的线程ID] -C10 --color
在堆栈中可以定位到影响 CPU 的线程在源码中的文件名称和代码行数,接下来只需要在项目工程中找到该文件的代码行数,分析问题的具体原因,修正即可。
下图例子中,我们可以定位到问题代码在 java 类 MyTest.java 的 78 行。

实际上,我们常用的是将堆栈 dump 下来,然后在本地进行分析。
dump 可使用命令:
$ jstack pid[进程ID] > jstack.txt[文件名称]
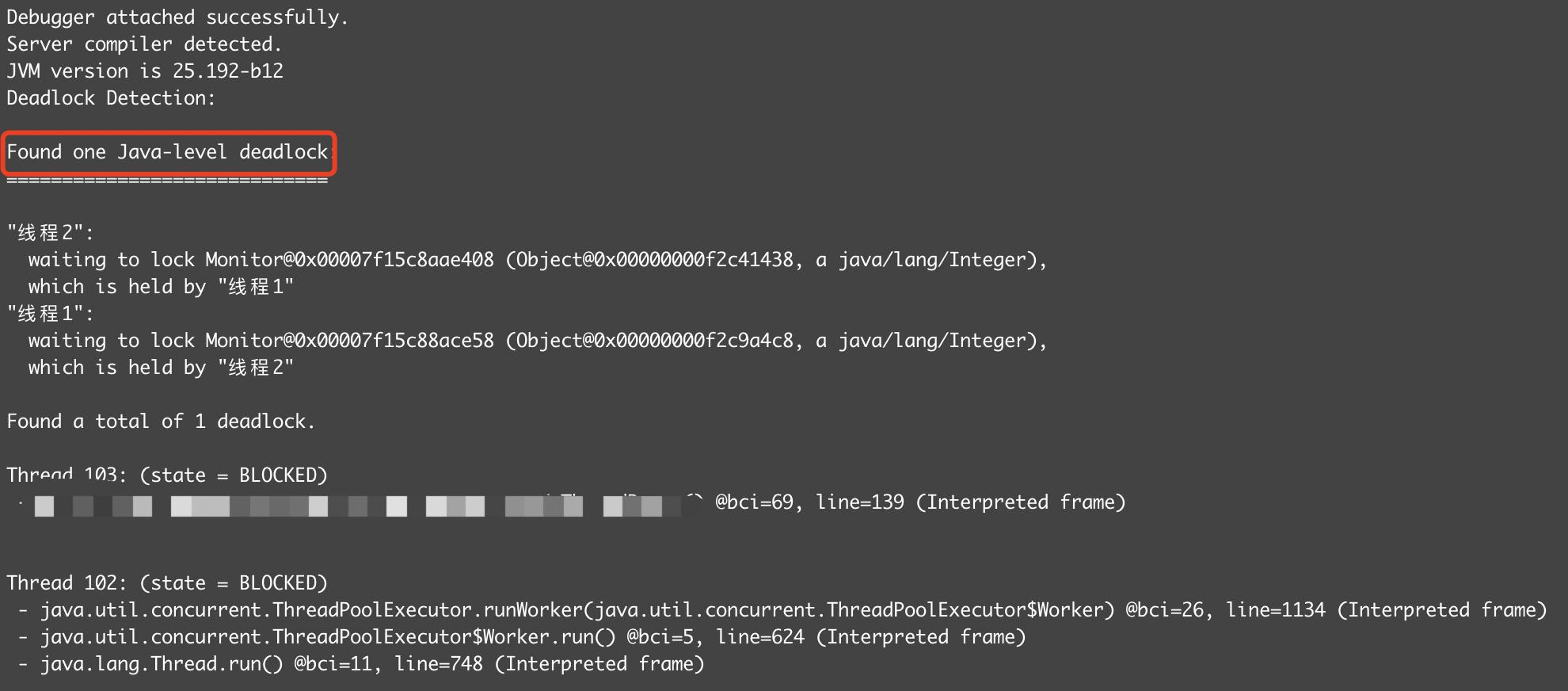
下图是一个死锁的例子,线程 2 正在等待一个被线程1持有的锁,线程1也在等待一个被线程 2 持有的锁,两者都在等待对方释放锁,造成死锁。
1.2 命令详解
top 命令是一个综合的命令,不仅可以查看 CPU ,还可以查看内存等。接下来,我们详细介绍一下 top 命令的使用和结果。
命令格式
$ top [-][d number][qcSsinb][p pid]
参数解释:
- d : 改变显示的更新速度,默认为 5 秒;
- q : 没有任何延迟的显示速度,如果使用者是有 superuser 的权限,则 top 将会以最高的优先序执行;
- c : 切换显示模式,共有两种模式,一是只显示执行档的名称,另一种是显示完整的路径与名称;
- S : 累积模式,会将己完成或消失的子进程 ( dead child process ) 的 CPU time 累积起来;
- s : 安全模式,将交谈式指令取消,避免潜在的危机;
- i : 不显示任何闲置 (idle) 或无用 (zombie) 的进程;
- n : 更新的次数,完成后将会退出 top;
- b : 批次档模式,搭配 “n” 参数一起使用,可以用来将 top 的结果输出到档案内;
- p:显示指定的进程信息。
结果说明
结果如下:

第一行:概况
与 uptime 执行效果一致
-
HH:mm:ss:系统当前时间 -
up x days, HH:mm:从开机到此刻的系统运行时间(单位:分钟) -
x user:此刻的登录用户数 -
- 可使用
who命令查看具体是哪些用户
- 可使用
-
load average: x.xx, x.xx, x.xx:系统在1分钟、5分钟、15分钟内的系统平均负载值。
扩展阅读:
- 什么是系统平均负载?
一段时间内 CPU 正在处理以及等待 CPU 处理的进程数之和的统计信息。
- 平均负载多大才算好?
- 系统平均负载/CPU核数 < 1 表示 CPU 工作量未达到饱和,还可以处理新的进程,一般不超过 70% 为佳;
- 查看 CPU 核数
cat /proc/cpuinfo | grep 'model name' /proc/cpuinfo | wc -l
- 1分钟、5分钟、15分钟的平均负载有何差异和意义?
- 如果1分钟的平均负载较高,但是15分钟的平均负载较低,说明系统只是短时间繁忙;
- 如果观察到系统长时间处于高负载运行,就需要进行干预和处理了。
第二行:进程信息
-
x total:所有进程数 -
x running:正在运行的进程数 -
x sleeping:休眠进程数 -
x zombie:僵尸进程数 -
- 僵尸进程是指子进程结束,而父进程未响应,导致父进程没有回收子进程,释放子进程占用的资源,那么此时子进程就会成为一个僵尸进程。
第三行:CPU 状态
%Cpu(s):表示当前 CPU 的平均值,默认 top 命令配置显示的是平均的 CPU 使用情况,如果按下键盘1可以显示各个逻辑 CPU 的使用情况。
x.x us:user space,用户空间消耗 CPU 时间百分比,通常用户 CPU 高表示有应用程序比较繁忙;x.x sy:sysctl,内核空间消耗 CPU 时间百分比;x.x ni:niced user processes,改变过优先级的用户进程占用的 CPU 百分比;x.x id:System Idle Process,空闲 CPU 时间百分比;x.x **wa**:wait space,CPU 在等待 I/O 操作完成所花费的时间,通常该指标越低越好,否则表示 I/O 存在瓶颈,可以在使用 iostat、sar 等命令做进一步分析;x.x hi:hardware interrupt,处理硬中断的 CPU 时间百分比。硬中断是由外设硬件(如键盘控制器、硬件传感器等)发出的,需要有中断控制器参与,特点是快速执行;x.x si:software interrupt,处理软中断的 CPU 时间百分比。软中断是由软件程序(如网络收发、定时调度等)发出的中断信号,特点是延迟执行;x.x st:steal time,等待 CPU 资源的时间百分比。仅出现在多虚拟机场景。如果该指标过高,可以检查下宿主机或其他虚拟机是否异常。
第四行:内存状态
可用内存=free + buffer + cached
xxx total:物理内存总量xxx free:空闲物理内存量xxx used:已使用物理内存量,还包括过去使用过的现在可以被重复利用的内存,内核并不把这些可被重新使用的内存交还到 free 中去,因此在 linux 上 free 内存会越来越少,但不用为此担心xxx buff/cache:缓存的内存量
第五行:交换区状态
xxx total:交换区总量xxx free:空闲交换区总量xxx used:已使用交换区总量,如果这个数值在不断的变化,说明内核在不断进行内存和 swap 的数据交换,这是真正的内存不够用了;xxx avail Mem:缓冲的交换区总量,可用于进程下一次分配的物理内存数量。
从第六行开始:进程详细信息
默认各进程是按照 CPU 的占用量从高到低进行排序
-
PID:进程 PID -
USER:进程所有者的用户名 -
PR:进程调度优先级,值越低优先级越高 -
NI:从用户空间视角的进程优先级(niced值),值越低优先级越高; -
VIRT:进程使用的虚拟内存(KB),VIRT=SWAP+RES -
RES:进程使用的(未被换出的)物理内存(KB),RES=CODE+DATA -
SHR:共享内存大小(KB) -
S:进程状态 -
- D:不可中断的睡眠状态(通常出现在IO阻塞)
- R:运行态
- S:睡眠态
- T:跟踪/停止
- Z:僵尸态
-
%CPU:进程占用 CPU 时间比例 -
%MEM:进程占用的物理内存比例 -
TIME+:进程占用 CPU 的时间总量(1/100秒),而非进程的存活时间。所以可能存在 TIME+大于程序运行时间,也可能小于程序运行时间,这两没有必然的关系。 -
COMMAND:运行进程使用的命令
快捷操作
- 1 :可以监控每个逻辑 CPU 的状况
- b :打开关闭加亮效果,在打开加亮的效果之后,我们可以按x键实现列的加亮效果
- P:以CPU的使用资源排序显示
- M:以内存的使用资源排序显示
- N:以pid排序显示
- T:由进程使用的时间累计排序显示
- S:切换到累计模式
- k:给某一个 pid 一个信号。可以用来杀死进程
- r:给某个 pid 重新定制一个 nice 值(即优先级)
- d:可以更改刷新时间(默认3秒)
- s:改变两次刷新之间的延迟时间(单位为s)
- i:可以只显示状态为R的进程
- c:可以显示进程的完整的命令(COMMAND列)
- shift + >:可以依次按照 PID、USER、PR····· 来进行排序。
- shift + <:可以依次按照 COMMAND、TIME+、%MEM····· 来进行排序
- o/O:可以自定义显示哪些列
- f/F:从当前显示中添加或者删除项目
- l:切换显示平均负载和启动时间信息
- m:切换显示内存信息
- t:切换显示进程和CPU状态信息
- W:将当前设置写入
~/.toprc文件中 - q:退出 top(用
ctrl+c也可以退出 top)
top -s以安全模式启动top界面,可以防止在 top 界面对进程进行修改操作。
(完)
如果文章对你有帮助,记得留言、点赞、加关注哦!
以上是关于测试沉思录14. 性能测试中的系统资源分析之一:CPU的主要内容,如果未能解决你的问题,请参考以下文章