SparkStreaming on Kafka之Kafka解析和安装实战
Posted snail_gesture
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SparkStreaming on Kafka之Kafka解析和安装实战相关的知识,希望对你有一定的参考价值。
本篇博文将从以下方面组织内容:
1. Kafka解析
2. 消息组件Kafka
3. Kafka安装
实验搭建所需要的软件:
kafka_2.10-0.9.0.1
Zookeeper集群已经安装好。在上一篇博文有安装步骤,不清楚的朋友可以参考下。
一:Kafka解析
1. Kafka是生产者和消费者模式中广播概念,Kafka也可以实现队列的方式。
2. Kafka不仅是一个消息中间键,还是一个存储系统,可以将流进来的数据存储一段时间。这就与传统的流式处理不一样,传统的流式处理处理完数据之后就消失了(指的是消息和流的角度),但是如果通过Kafka方式可以数据持久化到磁盘上,这就为我们很多功能的实现打下了很好的基础,这也就形成了比较完善的流式处理系统。
3. 完善的流式处理系统:在线低延迟处理数据,稳定可靠的,可以对流进来的数据进行非常复杂的逻辑分析,不仅可以处理当前在线的数据,也能处理过去一天或者一周的数据。
二:消息组件Kafka
1. 什么消息组件?A与B通信,中间需要组件,需要的这个组件就是中间键。
Kafka架构图如下:
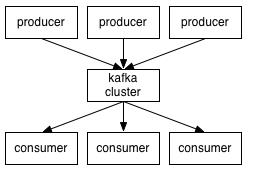
Kafka的生产者和消费者比较特殊。
Producer: 也就是数据的来源,数据可能来自于数据库,来自于Server服务器,或者说比如安卓端收集用户行为的数据。Producer中的数据是推到Kafka Cluster,例如别人给你发邮件,这个邮件是别人推过来的,当别人send的时候就是一个push的过程,转过来我要消费的时候就是一个poll的过程。
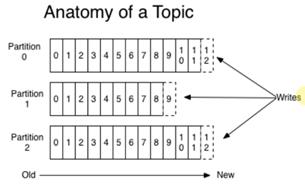
Topic:主题,代表了数据的类别或者是类型,生产者在放数据的时候就需要说明将自己放到是什么Topic中,Topic为了方便对数据的管理提出的一种抽象,本质就是一个对象。
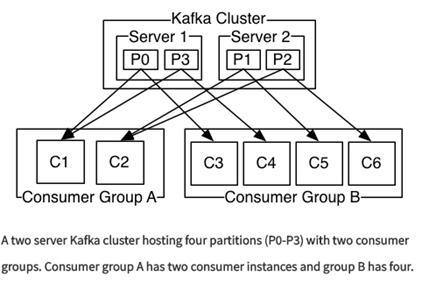
Group: 对于一个消息而言,在一个group中只能有一个消费实体,Group内部的实体,是互斥的(C1,C2是互斥的),这样做的好处就是,假设有一个Consumer(消费者)搞了很多线程,一个线程去抓取数据就可以了,不需要多条线程重复去抓取,上图是广播模式。
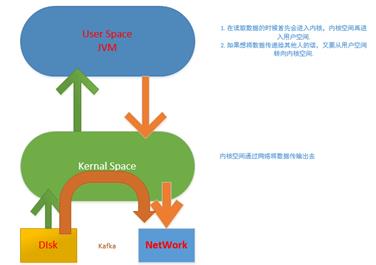
3. Kafka的数据传输是基于内核级(zero-copy)别的,Kafka是使用Scala写的,基于JVM虚拟机的,是基于JVM虚拟机的。
普通传输数据的方式:如果要传输一个数据,首先将数据从磁盘读到内核,再从内核读到用户空间(JVM),然后将数据传给其他机器的话,此时应用程序再从用户空间拷贝到内核,然后在从内核拷贝到网络上,这样的话数据前后就拷贝了四次。
Kafka:Kafka是基于Kernal级别的,没有用户空间的参与,当然用户空间会发起调用,但是数据并不传说到用户空间,所以这个时候如果消费数据的话例如上面图P0这个数据直接在内核中然后通过网络传给C1和C3,只需要内核态的参与,由于没有用户态的参与,这样性能得到了极大的提升。
- Kafka作为一个消息中间键,无限量的存储数据,只要磁盘足够大,Kafka中的数据是存储在磁盘中。
Kafka中的数据放入到磁盘中的好处: - 多份备份。
- 速度非常快。
- 采用Zookeeper去管理元数据。
- 作为一个消息中间键,顺序写,相当于文件在背后一直在追加的方式,然后消息具体在那会有一个元数据,这个元数据会被保存在Zookeeper中,Zookeeper目前又是事实上一致性的最佳选择。
三:Kafka安装
1. 到http://kafka.apache.org/downloads.html下载最新的Kafka版本,不过这里要注意的是有对应Scala版本。这里我选择第一个Scala2.10这个。
3. 安装Zookeeper,这里已经安装过了,如果不清楚请您查看上一篇博文。
dataDir=/usr/local/spark/zookeeper-3.4.6/data
dataLogDir=/usr/local/spark/zookeeper-3.4.6/logs
server.0=Master:2888:3888
server.1=Master:2888:3888
server.2=Master:2888:3888
4. 将slf4j-nop-1.7.6.jar拷贝到Kafka的libs目录下。
[root@Master slf4j-1.7.6]# cp slf4j-nop-1.7.6.jar /root/Desktop/kafka_2.10-0.9.0.1/libs/5. 将Kafka安装到local目录下。
[root@Master local]# ls
bin games hive kafka_2.10-0.9.0.1 libexec share
eclipse hadoop include lib sbin spark
etc hbase jdk lib64 scala src
6. 配置Bashrc。
export KAKFKA_HOME=/usr/local/kafka_2.10-0.9.0.1
export PATH=/usr/local/eclipse/eclipse:/usr/local/idea/idea-IC-141.1532.4/bin:$MAVEN_HOME/bin:$FLUME_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin/sbin::$SCALA_HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$ZOOKEEPER_HOME/bin:$KAKFKA_HOME/bin:$PATH
7. 将bashrc文件传送到Worker1和Worker2.
[root@Master local]# scp ~/.bashrc root@Worker1:~/.bashrc
.bashrc 100% 1236 1.2KB/s 00:00
[root@Master local]# scp ~/.bashrc root@Worker2:~/.bashrc
.bashrc 100% 1236 1.2KB/s 00:00
8. 配置Kafka中的service.properties
############################# Server Basics #############################
//这个参数就是作为Kafka集群实体的id.
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=0
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
//zookeeper的默认端口是2181
zookeeper.connect=Master:2181,Worker1:2181,Worker2:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=6000
9. 将Kafka中的配置拷贝到Worker1和Worker2节点上。
[root@Master local]# scp -r ./kafka_2.10-0.9.0.1/ root@Worker1:/usr/local/
[root@Master local]# scp -r ./kafka_2.10-0.9.0.1/ root@Worker2:/usr/local/
10. 修改Worker1的server.properties
Worker1:
############################# Server Basics #############################
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=1
Worker2:
############################# Server Basics #############################
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=2
- 启动Kafka。
//Master节点上Kafka启动成功。
[root@Master bin]# ./kafka-server-start.sh ../config/server.properties &
[root@Master sbin]# jps
4789 Master
4134 NameNode
5064 Jps
4745 QuorumPeerMain
5005 Kafka
//Worker1节点上Kafka启动成功。
[root@Worker1 bin]# ./kafka-server-start.sh ../config/server.properties &
[root@Master sbin]# jps
4789 Master
4134 NameNode
5064 Jps
4745 QuorumPeerMain
5005 Kafka
//Worker2节点上Kafka启动成功。
[root@Worker1 bin]# ./kafka-server-start.sh ../config/server.properties &
[root@Master sbin]# jps
4789 Master
4134 NameNode
5064 Jps
4745 QuorumPeerMain
5005 Kafka
12. 动手实战,创建HelloKafka文件成功。
[root@Master bin]# ./kafka-topics.sh --create --zookeeper Master:2181,Worker1:2181,Worker2:2181 --replication-factor 3 --partitions 1 --topic HelloKafka
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/kafka_2.10-0.9.0.1/libs/slf4j-log4j12-1.7.6.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/kafka_2.10-0.9.0.1/libs/slf4j-nop-1.7.6.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Created topic "HelloKafka".
13. 创建topic
[root@Master bin]# ./kafka-topics.sh --describe --zookeeper Master:2181,Worker1:2181,Worker2:2181 --topic HelloKafka
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/kafka_2.10-0.9.0.1/libs/slf4j-log4j12-1.7.6.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/kafka_2.10-0.9.0.1/libs/slf4j-nop-1.7.6.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Topic:HelloKafka PartitionCount:1 ReplicationFactor:3 Configs:
Topic: HelloKafka Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
14. Producer传入数据,输入数据之后,按Ctrl + C,其中broker和Spark中的Woker节点,差不多,Spark计算的时候以Worker为单位,而Kafka在传输数据的时候以broker为单位。
[root@Master bin]# ./kafka-console-producer.sh --broker-list Master:9092,Worker1:9092,Worker2:9092 --topic HelloKafka
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/kafka_2.10-0.9.0.1/libs/slf4j-log4j12-1.7.6.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/kafka_2.10-0.9.0.1/libs/slf4j-nop-1.7.6.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Life is short! you need Spark
Life is short! you need Spark
^C[root@Master bin]#
15. Consumer端接收到数据。
[root@Master bin]# ./kafka-console-consumer.sh --zookeeper Master:2181,Worker1:2181,Worker2:2181 --from-beginning --topic HelloKafka
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/kafka_2.10-0.9.0.1/libs/slf4j-log4j12-1.7.6.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/kafka_2.10-0.9.0.1/libs/slf4j-nop-1.7.6.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Life is short! you need Spark
Life is short! you need Spark
以上是关于SparkStreaming on Kafka之Kafka解析和安装实战的主要内容,如果未能解决你的问题,请参考以下文章