论文阅读笔记:Multi-Labeled Relation Extraction with Attentive Capsule Network(AAAI-2019)
Posted 梆子井欢喜坨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读笔记:Multi-Labeled Relation Extraction with Attentive Capsule Network(AAAI-2019)相关的知识,希望对你有一定的参考价值。

论文信息
作者:
- Xinsong Zhang Shanghai Jiao Tong University
- Pengshuai Li Shanghai Jiao Tong University
- Weijia Jia University of Macau & Shanghai Jiao Tong University
- Hai Zhao Shanghai Jiao Tong University
论文来源:
AAAI-2019
论文引用:
Zhang X, Li P, Jia W, et al. Multi-labeled relation extraction with attentive capsule network[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33(01): 7484-7491.
论文链接:
https://ojs.aaai.org/index.php/AAAI/article/view/4739
摘要:
从一个句子中揭示重叠的多重关系仍然具有挑战性。目前大多数神经网络模型的工作都不方便地假设每个句子都显式地映射到一个关系标签上,不能正确地处理多个关系,因为这些关系的重叠特征要么被忽略,要么很难识别。针对这一问题,本文提出了一种新的基于胶囊网络的多标记关系提取方法,该方法在识别单个句子中高度重叠的关系方面,比现有的卷积或递归网络具有更好的性能。为了更好地进行特征聚类和关系提取,我们进一步设计了基于注意力机制的路由算法和一种sliding-margin损失函数,并将其嵌入到胶囊网络中。实验结果表明,该方法确实能够提取出高度重叠的特征,与现有的方法相比,关系提取的性能有了显著的提高。
1. 动机
之前的基于神经网络的RE模型,在句子有多个关系标签的情况下效果不佳。
由于以下两个缺点,在提取高度重叠和离散的关系特征时面临挑战。
- 首先,一个实体对可以在一个句子中表达多个关系,这将严重混淆关系抽取器。之前的工作大多都是用CNN、RNN之类的神经网络来提取low-level的特征,然后用max-pooling、word attention之类的方法来将low-level的特征映射到high-level的特征。但是对于多分类问题来说,一个sentence里面会有很多overlap的relation特征,难以明确识别。一个高层次的关系向量还不足以准确表达多个关系。
- 其次,现有的方法忽略了关系特征的离散化。例如,如图1所示,所有的句子都用离散分布在句子中的几个有意义的单词(图中标记为斜体)来表达它们之间的关系。而常用的神经网络方法处理结构固定的句子,很难收集到不同位置的关系特征。作者认为现存的方法,不足以聚集这些离散token的信息。

在本文中,为了提取重叠和离散的关系特征,我们提出了一种利用关注胶囊网络进行多标签关系提取的方法。如上图所示,所提出方法的关系提取器由三个主要层构成,即特征提取、特征聚类和关系预测。第一种提取低层次语义。第二层将低层次特征聚类成高层次关系表示,最后一层预测每个关系表示的关系类型。
胶囊网络(Capsule)是用来表达特征的一小组神经元。它的总长度表示特征的重要性,胶囊(向量)的方向表示特征的特定属性。
- 首先通过聚类关系特征将胶囊网络应用于多标签关系抽取。
- 我们提出了一种基于注意力的路由算法来精确提取关系特征,并提出了一种滑动边界损失函数来很好地学习多种关系。
- 我们在两个基准上的实验表明,我们提出方法的性能达到了新的sota。
we propose a sliding-margin loss function to address the problem of “no relation” in multiple labels scenario. A sentence is classified as “no relation” only when the probabilities for all the other specific classes are below a boundary. The boundary is dynamically adjusted in the training process.
2. 模型与算法
2.1 模型总体结构

- Feature Extracting Layer:用Bi-LSTM来抽取low-level的语义特征。
- Feature Clustering Layer:这个模块的目的是为了在low-level的特征中选择出对关系有用的特征,聚合到high-level特征。其实就是为了解决overlapped and discrete relation feature。
- Relation Predicting Layer:在这里对关系进行预测分类。
2.2 特征提取层(Feature Extracting Layer)
给定一个句子 b ∗ b^* b∗和两个目标实体,使用双LSTM网络提取句子的低层特征。
模型的输入表示包括词嵌入(Word Embeddings )和位置嵌入(Position Embeddings)
词嵌入:
word2vec中的skip-gram,将每个词嵌入p维的实值向量。
位置嵌入:
位置嵌入被定义为从当前单词到实体的相对距离的组合。
例如“Arthur Lee was born in Memphis.”这个句子
“ born”与实体[Arthur Lee] 的距离为2,与实体[Memphis]的距离为-2
将这些相对距离嵌入到q维向量空间
词嵌入和位置嵌入作为网络输入向量连接在一起。
我们将一个句子中的所有单词表示为一个初始向量序列 b ∗ = x 1 , . . . x i , . . . , x n b^* = \\x_1,...x_i,...,x_n\\ b∗=x1,...xi,...,xn, x i x_i xi为p+q维向量,n是单词的数量。然后输入一个双向LSTM。
2.3 Feature Clustering Layer
这一层在基于注意力的路由算法的帮助下聚集特征。
低级胶囊包含局部的和琐碎的特征。当多个预测一致时,更高水平的胶囊被激活。
胶囊网络特征聚类
low-level capsules u ∈ R d u u\\in R^d_u u∈Rdu
high-level capsules r ∈ R d r r\\in R^d_r r∈Rdr
每个word token由k个low-level capsules表示
g是squash函数
个人理解 h t h_t ht是Bi-LSTM输出的隐藏状态,被分为k份,得到k个low-level capsulesi用来表示每个词的token。

where [x;y] denotes the vertical concatenation of x and y.


w i j w_ij wij是由迭代动态路由过程确定的耦合系数, W j ∈ R d r × d u W_j\\in R^d_r \\times d_u Wj∈Rdr×du
基于注意力的路由算法
和原论文中的算法基本一致
改动在于第7行,为低级别的胶囊计算了注意力权重 α \\alpha α,以最大化来自重要单词标记的胶囊的权重,并最小化无关胶囊的权重。然后在第8行,计算高层胶囊 v j v_j vj的输入的时候,乘上了这个注意力权重。

2.4 Relation Predicting Layer
原论文中的分类损失函数,原本 m + = 0.9 , m − = 0.1 m^+=0.9, m^-=0.1 m+=0.9,m−=0.1

这里把原来的margin loss也改动了一下。
γ \\gamma γ是定义边距宽度的超参数,B是一个可学习变量,表示NA(not relation)的阈值,初始化为0.5。

当一个句子的这些关系的概率大于阈值B时,就会给这个句子分配关系标签,否则会被预测为NA。
3. 实验分析
实验用于回答下面三个问题:
1)我们的方法在关系抽取方面是否优于以前的工作?
2)注意力胶囊网络(attentive capsule network)对区分高度重叠关系有用吗?
3)提出的两个改进对关系抽取都有效吗?
数据集

基线

在NYT-10上的实验结果
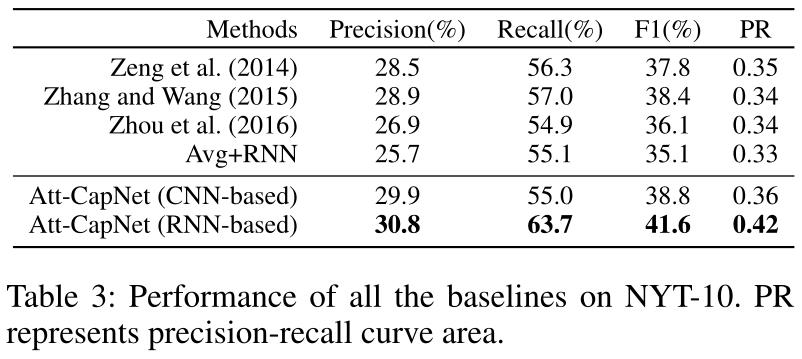
在SemEval-2010 Task 8上的结果

在multi-labeld的句子(出自NYT-10)上的实验结果
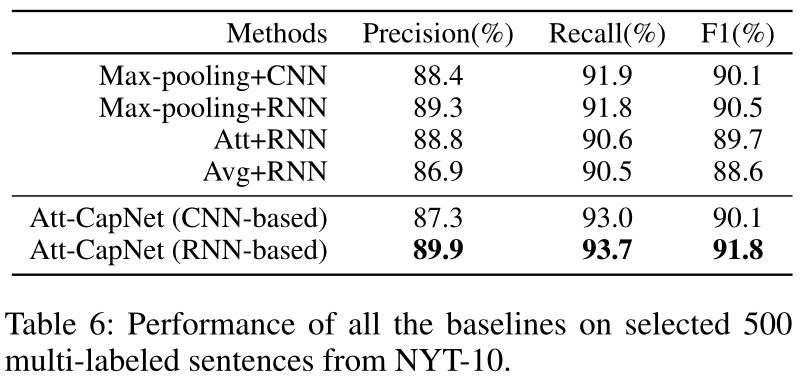
做了两个变体模型,分别去掉attention-based routing algorithm和sliding-margin loss 。
可以发现,提出的这两个东西确实提升了胶囊网路提取关系的性能。

做了一个Case Study,对比可以发现本文提出的Att-CapNet识别重叠关系的能力较强。
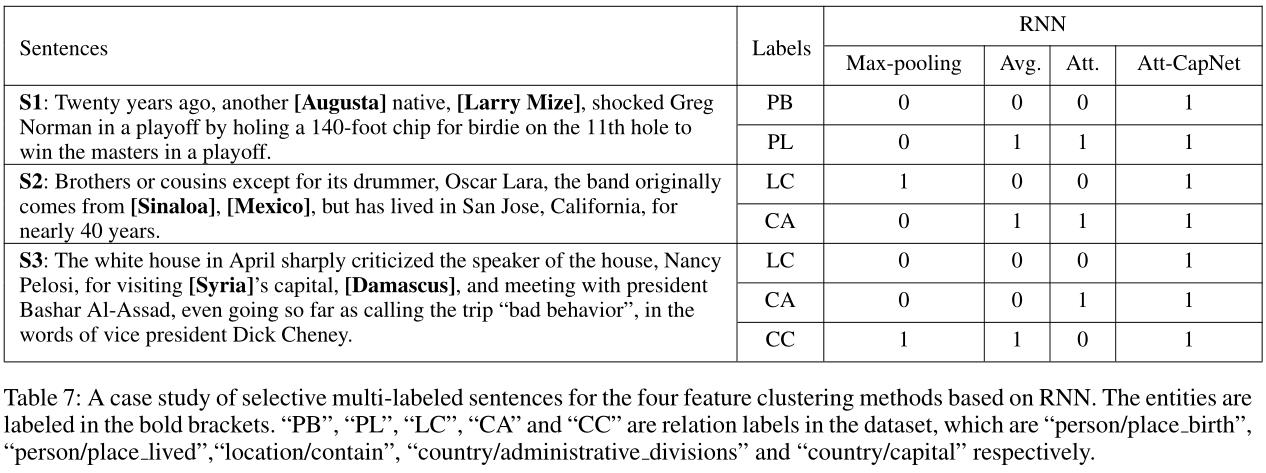
4. 补充
18年这篇论文也是用胶囊网络做关系抽取任务
Attention-Based Capsule Networks with Dynamic Routing for Relation Extraction(EMNLP-2018)
https://www.aclweb.org/anthology/D18-1120/
作者:
- Ningyu Zhang
- Shumin Deng
- Zhanling Sun
- Xi Chen
- Wei Zhang
- Huajun Chen
没有细读
这里的多实体关系抽取,指的是在一个sentence里面有多个实体对,但是每个实体对只有一个relation。
模型基本和论文2一致。
没有对动态路由算法和损失函数进行改进。

以上是关于论文阅读笔记:Multi-Labeled Relation Extraction with Attentive Capsule Network(AAAI-2019)的主要内容,如果未能解决你的问题,请参考以下文章