东方财富股吧标题爬取分析
Posted 一加六
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了东方财富股吧标题爬取分析相关的知识,希望对你有一定的参考价值。
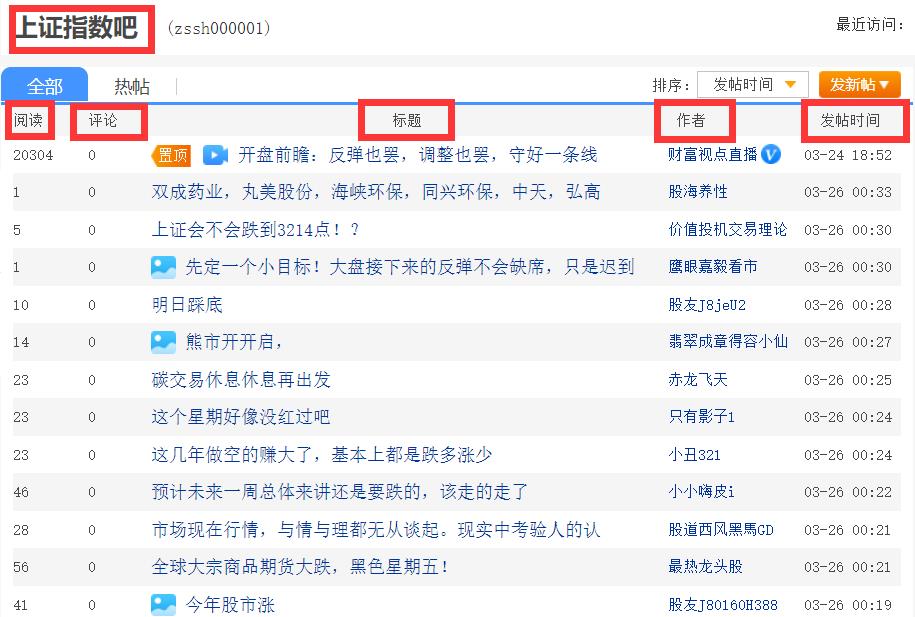
45个股吧,140万条数据库记录
日期从2018-03-01至2021-03-01共36个月的股吧帖子,
爬取股吧名称、阅读、评论、标题、作者和发帖时间,
并分析总体情绪
亮点回顾
时间问题
获取的时间未加年份,解决方法,观察发现发帖日期月份逐级递减,按获取顺序下一个时间月份在同一年内小于等于上一个月份,设一个变量m储存月份,始值设为12,与获取的最新月份new_m比较,若new_m>m,使当前年份减一;再令m=new_m。
数据去重问题
有时候爬取会因各种问题中断,当你再次续爬时数据会重复,于是我加了一个用于去重的myid
myid = item[‘username’] + str(item[‘mdate’])[3:-4] + title[:100]
思想是,时间地点人物组合,即谁在什么时间干了什么地点没加,但也使每条记录内容保证唯一,大概率去重。
考虑过用每个news的url做主键去重,但是一下url是有重复的
创建的数据表语句如下
create table info_guba
(
id int auto_increment
primary key,
myid varchar(255) collate utf8mb4_croatian_ci not null,
scans int(8) null,
comments int(6) null,
titles text collate utf8mb4_croatian_ci null,
usernames varchar(50) collate utf8mb4_croatian_ci null,
mdates int(15) null,
f_scores float(12, 10) default 0.0000000000 null,
polarity int(1) null,
company_name varchar(80) collate utf8mb4_croatian_ci null,
industry varchar(80) collate utf8mb4_croatian_ci null
);
跨年份取月份对应时间戳问题
2018-03至2021-03期间每个月份的情绪指数,要取每个月的一号和下个月的一号时间戳,使能完成区间取值,
我的方法
将38个月份数值储存在一个列表,遍历列表月份,如果月份没到倒数第二位,判断月份是否为12月,是则变量年份减一,拿日期转换时间戳得到时间段较大值,再判断,该月份的下一个月份是不是12月,是则年份减一,日期转换时间戳得到较小值
months = [3, 2, 1, 12, 11, 10, 9, 8, 7, 6, 5,
4, 3, 2, 1, 12, 11, 10, 9, 8, 7, 6,
5, 4, 3, 2, 1, 12, 11, 10, 9, 8, 7,
6, 5, 4, 3, 2]
for num, m in enumerate(months):
if num != 36:
if m == 12:
year -= 1
max_timestamp = self.date_to_timestamp(year, m)
if months[num + 1] == 12:
year02 = year - 1
else:
year02 = year
month = str(year02) + '-' + str(months[num + 1])
min_timestamp = self.date_to_timestamp(year02, months[num + 1])
break
爬虫部分代码
# /usr/bin/python
# --*-- coding:UTF-8 --*--
# Date 2021/3/18 16:35
import re
import time
import jieba
import pymysql
import requests
import pandas as pd
from lxml import etree
from snownlp import SnowNLP
class guba():
def __init__(self, host, db, user, passwd):
self.headers = 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, '
'like Gecko) Chrome/89.0.4389.90 Safari/537.36 Edg/89.0.774.54'
self.host = host
self.db = db
self.user = user
self.passwd = passwd
self.dataoutput = DataOutput()
self.ip_num = 1
# 获取代理
def get_new_ip(self):
if self.ip_num <= 1000:
ip_port = requests.get(
'获取代理的api',
timeout=6)
ip = ip_port.text.replace('\\r\\n', '')
proxyip = "http": "http://" + ip,
"https": "https://" + ip
self.ip_num += 1
else:
return None
return proxyip
# 移除换行符
def rm_special_letters(self, old_list):
new_list = []
for i in old_list:
i = i.replace('\\r\\n', '')
i = i.replace(' ', '')
new_list.append(i)
return new_list
# 将日期格式转换为时间戳
def date_to_timestamp(self, year, timestr):
mdate = str(year) + '-' + timestr
time_array = time.strptime(mdate, "%Y-%m-%d")
news_timestamp = time.mktime(time_array)
return news_timestamp
# 获取每日热帖 阅读量 评论量 标题 用户 发帖时间
def dangu_pinglun(self, url, company_name, industry):
"""
:param 所属板块:
:param 公司名称:
:type url: 股吧首页链接
"""
global mtimestamp
mtimestamp = time.time()
page = 1
year = 2021
latest_mounth = 12
proxyip = self.get_new_ip()
while True:
datalist = []
try:
if page % 50 == 0:
#每50页换一次代理ip 防止反扒
print(company_name, page, "----" + str(time.time()))
proxyip = self.get_new_ip()
#拼接url
murl = url + str(page) + '.html'
resp = requests.get(murl, headers=self.headers, proxies=proxyip, timeout=10)
# print(resp.text)
htmltree = etree.HTML(resp.text)
yuedu_count = htmltree.xpath('//span[@class="l1 a1"]/text()')
yuedu_count = self.rm_special_letters(yuedu_count)[1:]
pinglun_count = htmltree.xpath('//span[@class="l2 a2"]/text()')
pinglun_count = self.rm_special_letters(pinglun_count)[1:]
title_list = htmltree.xpath('//span[@class="l3 a3"]/a/@title')
username_list = htmltree.xpath('//span[@class="l4 a4"]/a//text()')
last_time_list = htmltree.xpath('//span[@class="l5 a5"]/text()')[1:]
# 此处将评论列表保存到字典 交给dataoutput储存
for num, p in enumerate(pinglun_count):
# 当阅读数量含有汉字时
if re.search('[\\u4e00-\\u9fa5]', yuedu_count[num]):
yuedu_count[num] = 20000
if re.search('[\\u4e00-\\u9fa5]', pinglun_count[num]):
pinglun_count[num] = 20000
# 截取时间具体提到天 去掉时分时间
lastdate = last_time_list[num].split(' ')[0]
#发帖时间递减 ,当下层月份大于上边时年份减一
if int(lastdate.split('-')[0]) > latest_mounth:
year -= 1
mtimestamp = self.date_to_timestamp(year, lastdate)
info_dict = 'scan': yuedu_count[num],
'comment_num': pinglun_count[num],
'title': title_list[num],
'username': username_list[num],
'mdate': mtimestamp,
'company': company_name,
'industry': industry
datalist.append(info_dict)
latest_mounth = int(lastdate.split('-')[0])
page += 1
# 将存库语句写到这里是为了个别字节数据储存终端而导致总程序终段
self.dataoutput.write_to_mysql(host=self.host, db=self.db, user=self.user, passwd=self.passwd,
datalist=datalist)
time.sleep(1)
except Exception as e:
print(industry, company_name, page, "---" + str(time.time()))
print(str(e))
if 'HTTPConnectionPool' in str(e):
proxyip = self.get_new_ip()
if 'index out of range' in str(e):
page += 1
elif 'day is out of range for month' in str(e):
page += 1
# 此处判断总时间是否到达最大时间 即到2018年3月终止 爬取下一个
if mtimestamp <= 1521475200:
print('时间到')
break
class DataOutput():
def __init__(self):
self.__tablename = 'info_guba'
self.__tablekeys = '(myid,scans,comments,titles,usernames,mdates,f_scores,company_name,industry)'
#删除特殊字符 以防引起mysql异常
def rm_special_letter(self, line):
for i in ["\\'", "\\"", "#", "\\\\"]:
line = line.replace(i, "")
return line
"""借助snownlp
分析news的情绪分为3级 0:积极 1:中立 2:消极"""
def feeling(self, line):
try:
res = SnowNLP(line)
f_score = res.sentiments
except:
f_score = 0
return f_score
def __rm_stopwords(self, wordlist):
new_wordlist = []
with open('tool_files/stopwords.txt', 'r', encoding='utf-8') as r:
stopwords = r.read()
for i in wordlist:
if i in stopwords:
continue
else:
new_wordlist.append(i)
return new_wordlist
"""使用玻森情感词典 计算情绪指数"""
def feeling2(self, line):
path = "tool_files/sentiment_score.txt"
df = pd.read_table(path, sep=" ", names=['key', 'score_snownlp'])
key = df['key'].values.tolist()
score = df['score_snownlp'].values.tolist()
def getscore(line):
segs = jieba.lcut(line) # 分词
jieba.load_userdict('tool_files/userdict.txt')
segs = self.__rm_stopwords(segs)
score_list = [score[key.index(x)] for x in segs if (x in key)]
# 修改后的sentiment_score.txt 得分有的为字符串格式不能直接使用sum求和
# print(score_list)
if len(score_list) != 0:
sums = 0
for i in score_list:
sums = sums + float(i)
return sums / len(score_list) # 计算得分
else:
return 0
last_score = getscore(line)
if last_score == 0:
return 0
else:
return round(last_score, 5)
#数据去重
def __mysql_data_rechecking(self, item, ids_inmysql):
id_inmysqls = [myid[0] for myid in ids_inmysql]
title = self.rm_special_letter(item['title'])
myid = item['username'] + str(item['mdate'])[3:-4] + title[:100]
if myid not in id_inmysqls:
return 'newrecord', title, myid
else:
return '数据已存在'
def write_to_mysql(self, datalist, host, db, user, passwd):
# mysql连接初始化连接
db = pymysql.connect(host=host, user=user, password=passwd, database=db)
# 使用 cursor() 方法创建一个游标对象cursor
cursor = db.cursor()
# 查询表中 plantform title username 数据拼接字符串用于去重
quchong_sql = 'SELECT myid FROM '.format(self.__tablename)
cursor.execute(quchong_sql)
myids = cursor.fetchall()
for item in datalist:
data = self.__mysql_data_rechecking(item, myids)
if data[0] == 'newrecord':
title, myid = data[1], data[2]
# feeling = self.feeling(title)
feeling = 0
# SQL插入语句
sql = "INSERT INTO TABLENAMEkeys" \\
"VALUES ('v0','v1','v2','v3','v4','v5','v6','v7','v8')".format \\
(TABLENAME=self.__tablename,
keys=self.__tablekeys,
v0=myid,
v1=item['scan'],
v2=item['comment_num'],
v3=title,
v4=item['username'],
v5=item['mdate'],
v6=feeling,
v7=item['company'],
v8=item['industry'])
try:
# 执行sql语句
cursor.execute(sql)
# 执行sql语句
db.commit()
except Exception as e:
if 'PRIMARY' in str(e):
print('查重失败')
else:
print(item)
print(str(e) + "---" + str(time.time()))
# 发生错误时回滚
db.rollback()
# raise e
# 关闭数据库连接
db.close()
data01 =
'批发和零售业': ['大参林 603233', '广百股份 002187', '来伊份 603777'],
'制造业': ['中国中车 601766', '永兴材料 002756', '海思科 002653'],
'房地产业': ['格力地产 600185', '绿景控股 000502', '万科A 000002'],
'租赁和商务服务业': ['深圳华强 000062', '渤海租赁 000415', '轻纺城 600790'],
'采矿业': ['兴业矿业 000426', '冀中能源 000937', '中国石化 600028'],
'交通运输、仓储和邮政业': ['中远海控 601919', '宜昌交运 002627', '大众交通 600611'],
'信息传输、软件和信息技术服务业': ['恒生电子 600570', '中国联通 600050', '恒华科技 300365'],
'教育': ['好未来 ustal', '中公教育 002607', '紫光学大 000526'],
'卫生和社会工作业': ['通策医疗 600763', '迪安诊断 300244', '爱尔眼科 300015'],
'文化、体育和娱乐业': ['凤凰传媒 601928', '新华传媒 600825', '长江传媒 600757'],
'金融业': ['民生银行 600016', '中国平安 601318', '国信证券 002736'],
'建筑业': ['棕榈股份 002431', '上海建工 600170', '隧道股份 600820'],
'电力、热力、燃气及水的生产和供应业': ['滨海能源 000695', '太阳能 000591', '上海电力 600021'],
'水利、环境和公共设施管理业': ['远达环保 600292', '碧水源 300070', '启迪环境 000826']
if __name__ == '__main__':
gb = guba(host='localhost', db='guba', user='root', passwd='root')
for item in data:
for num