第二届中国高校大数据挑战赛A题解题思路
Posted 不上心的马小跳
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第二届中国高校大数据挑战赛A题解题思路相关的知识,希望对你有一定的参考价值。
虽然第二届中国高校大数据挑战赛已经结束,但他留给我们的思考却并没有宗旨。这里主要探讨下关于A题的解题思路。
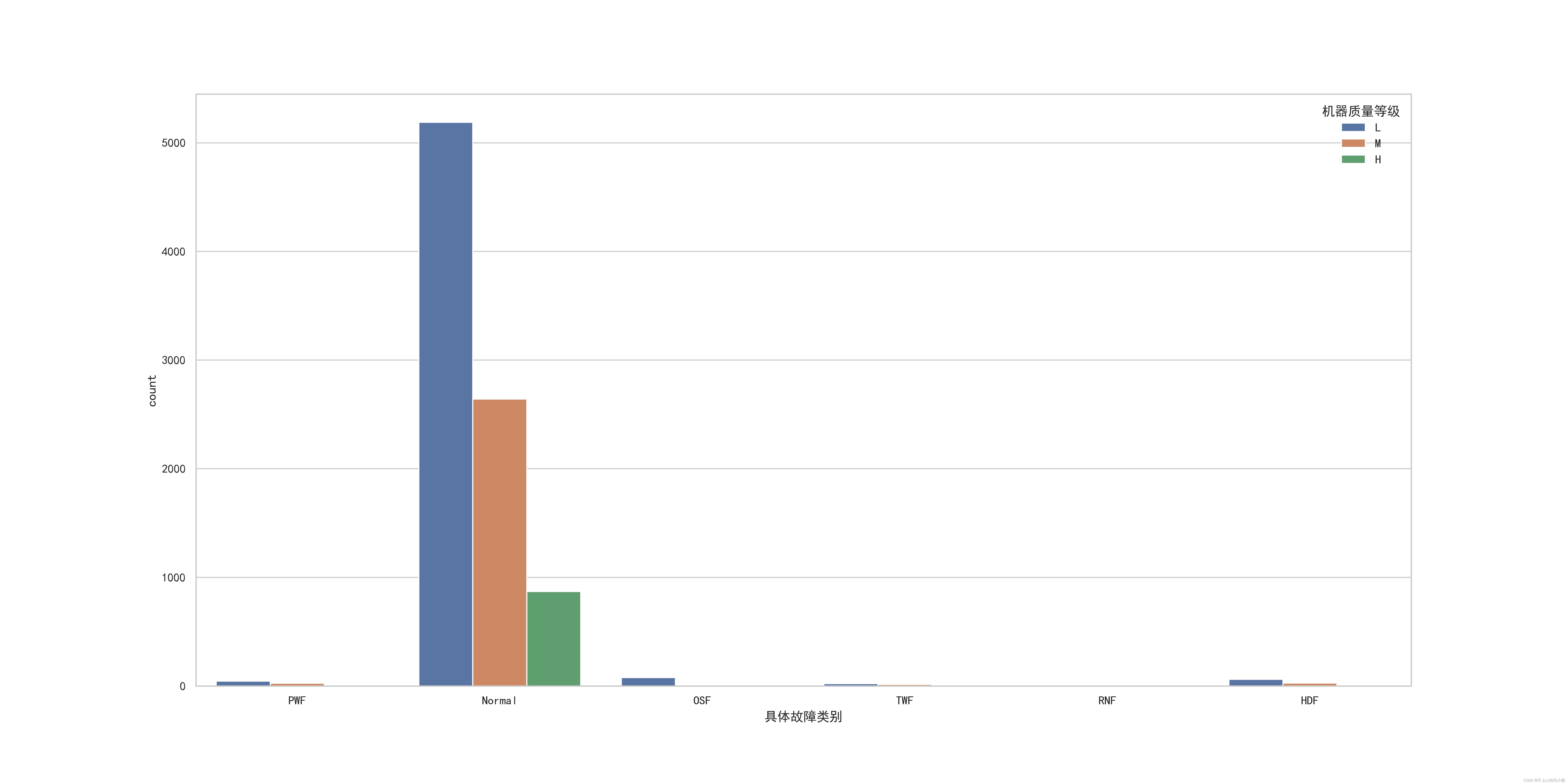
首先,通过对属性具体故障类别的统计可视化发现,这是一个类别样本不均衡的问题。主要体现在正常样本比例占比极大;而其他类别样本相比之下,占比不值一提。这需要特别关注,因为样本不均匀会导致后期直接训练模型时,一方面只要能过多预测noraml样本模型准确率就会很高,真实故障样本是否预测正确则显得无关紧要;另一方面,划分训练集与测试集后,由于某些样本类别本来就少,所以模型训练后往往出现此类样本的过拟合,模型的泛化能力不足。所以这里选择能够处理样本不均匀的模型或者进行重采样。
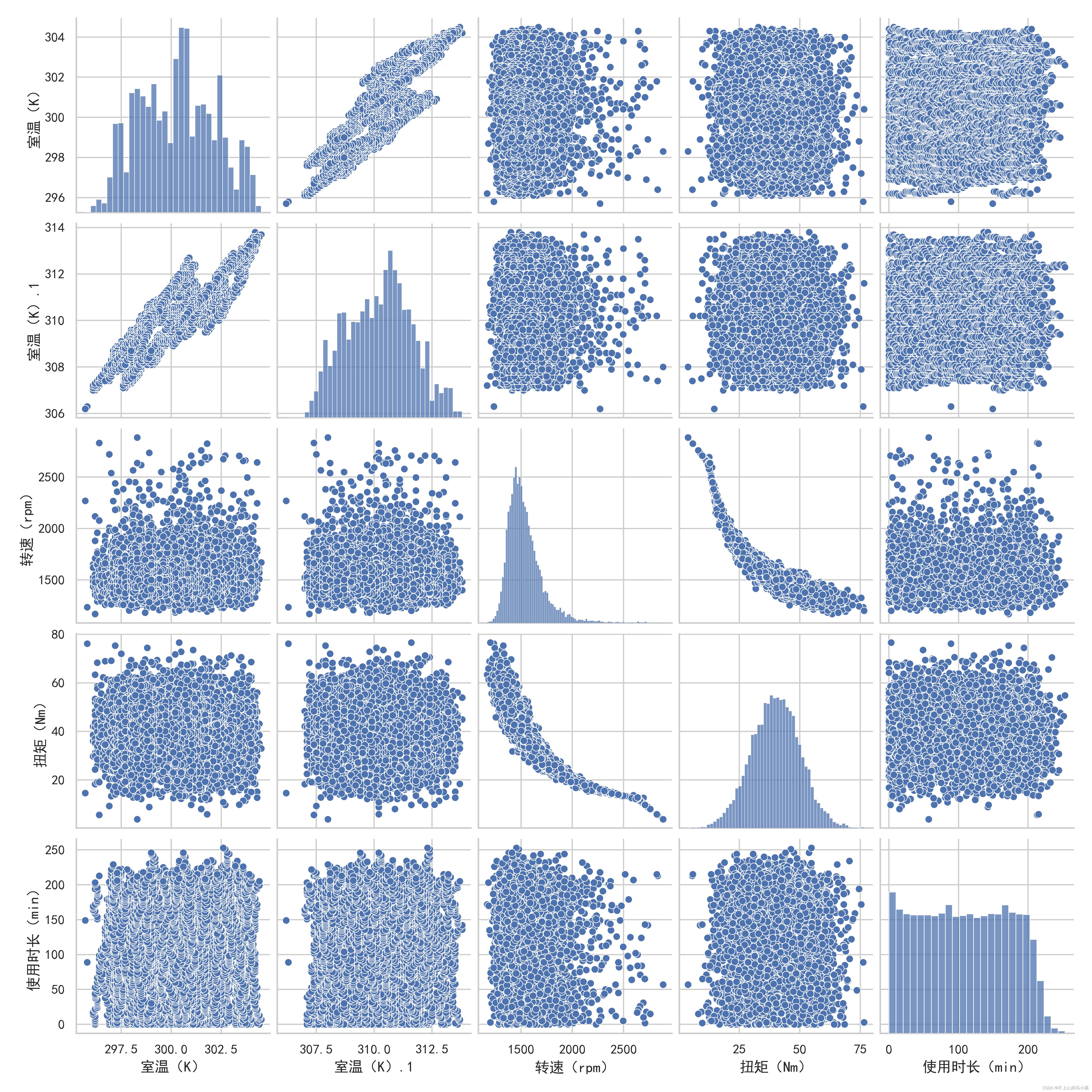
针对具体问题,其实预测设备是否故障与故障类别大同小异,这里以预测具体故障类别为例。首先进行缺失值,重复值,异常值的识别,然后对相关数据进行可视化分析。这里数据处理尤为重要,选择通过oneclasssvm, 孤立森林等多种异常值识别算法,对noraml样本中的异常数据识别删除。这样一方面有助于类别样本均衡,另一方面有助于模型建立的有效性,减少noraml样本对模型的偏差影响。对处理后数据标准化,数据预处理工作就结束了。
然后选择合适方法解决样本类别不均衡问题。其中包括基于权重的支持向量机分类,基于组合集成方法的随机森林,以及结合过采样与欠采样结合的重采样方法(SMOTEENN)并根据相应的判断结果对方法进行选择。最终确定使用重采样方法,作为建立模型的准备数据。
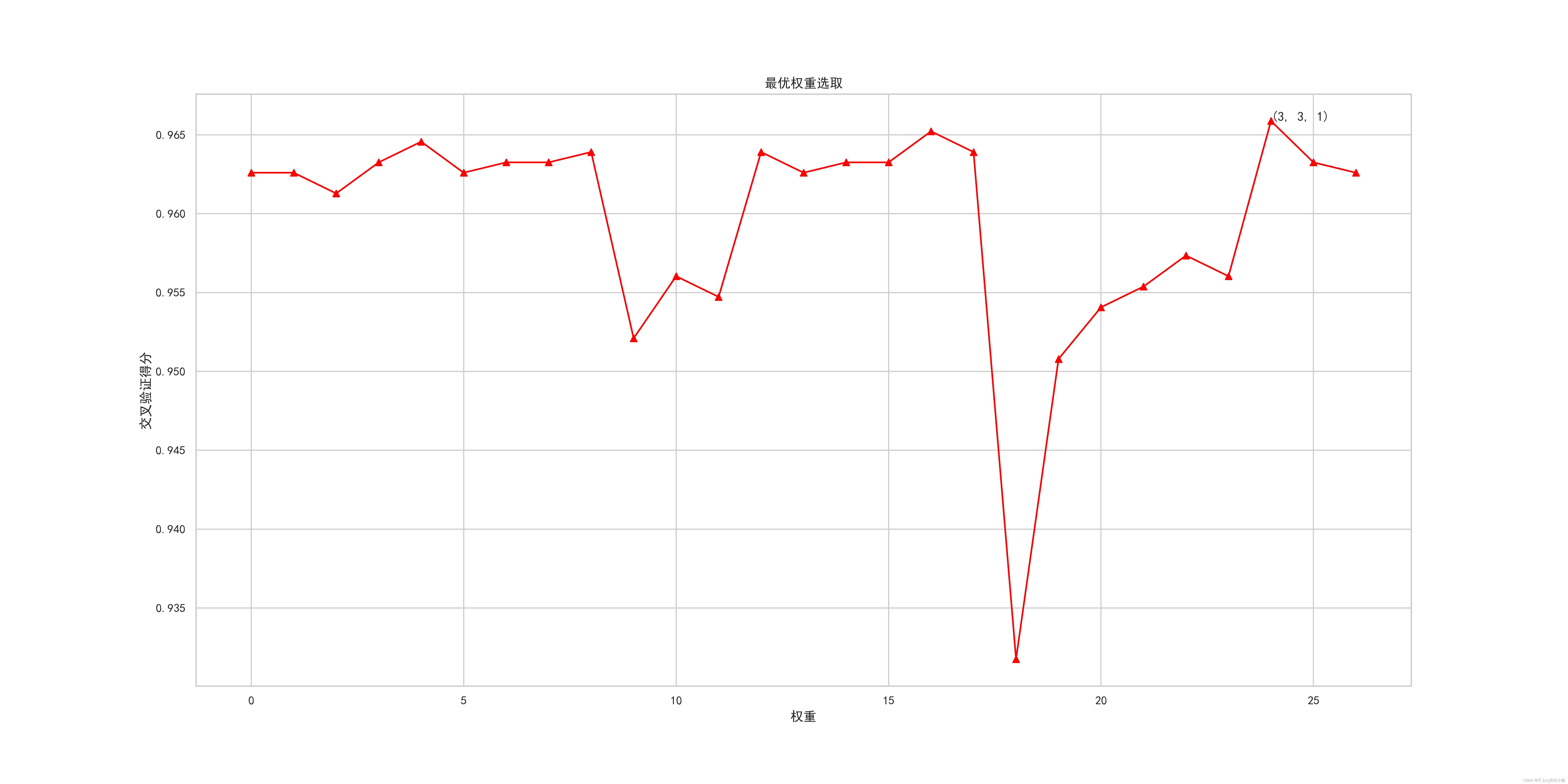
针对问题一,采用SelectFromModel方法,利用ExtraTreesClassifier,RandomForestClassifier,xgboost这3种树模型以及LinearSVC模型嵌入进行特征选择,选择出有效指标。
针对问题二与问题三,主要区别在于目标变量不同,但其他思想一致。这里以判别故障具体类别为例,运用基于决策树,二次判别,随机森林的投票法模型分类判断。在测试集上准确率达到97%左右。
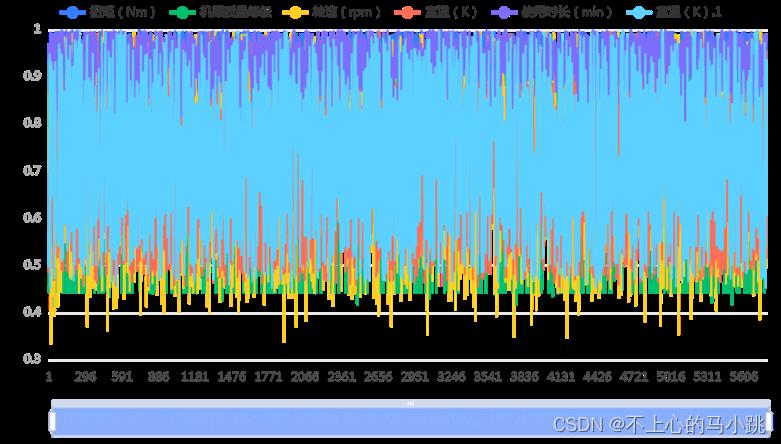
针对问题四,先对数据进行分组,采用灰色关联分析法,帮助选择对不同故障类别影响关联度最大特征属性,结合可视化分析,挖掘规则。
部分运行过程结果如下
数据可视化:
关联系数图
以上是关于第二届中国高校大数据挑战赛A题解题思路的主要内容,如果未能解决你的问题,请参考以下文章