Azkaban使用
Posted 悠然予夏
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Azkaban使用相关的知识,希望对你有一定的参考价值。
1、shell command调度
创建job描述文件
vi command.job
type=command
command=echo 'hello'将job资源文件打包成zip文件
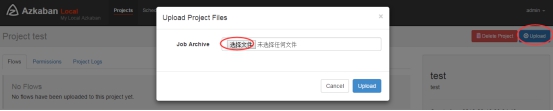
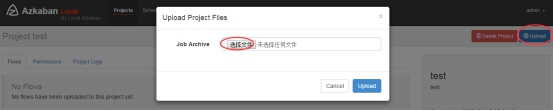
zip command.job通过azkaban的web管理平台创建project并上传job压缩包
首先创建Project
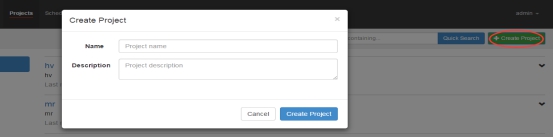
上传zip包
启动执行该job
2、job依赖调度
第一个job:foo.job
type=command
command=echo 'foo'第二个job:bar.job依赖foo.job
type=command
dependencies=foo
command=echo 'bar'将所有job资源文件打到一个zip包中

在azkaban的web管理理界面创建工程并上传zip包
启动工作流flow
3、HDFS任务调度
创建job描述文件 fs.job
type=command
command=/opt/lagou/servers/hadoop-2.9.2/bin/hadoop fs -mkdir /azkaban将job资源文件打包成zip文件
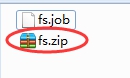
通过azkaban的web管理平台创建project并上传job压缩包
启动执行该job
4、MAPREDUCE任务调度
mr任务依然可以使用command的job类型来执行
创建job描述文件,及mr程序jar包(示例中直接使用hadoop自带的example jar)
mrwc.job
type=command
command=/opt/lagou/servers/hadoop-2.9.2/bin/hadoop jar hadoop-mapreduceexamples-2.9.2.jar wordcount /wordcount/input /wordcount/azout将所有job资源文件打到一个zip包中
在azkaban的web管理界面创建工程并上传zip包
启动job
遇到虚拟机内存不足情况:
- 增大机器器内存
- 使用清除系统缓存命令,暂时释放一些内存
[root@linux123 mapreduce]# echo 1 >/proc/sys/vm/drop_caches
[root@linux123 mapreduce]# echo 2 >/proc/sys/vm/drop_caches
[root@linux123 mapreduce]# echo 3 >/proc/sys/vm/drop_caches5、HIVE脚本任务调度
创建job描述文件和hive脚本
Hive脚本: test.sql
use default;
drop table aztest;
create table aztest(id int,name string) row format delimited fields terminated by ',';Job描述文件:hivef.job
hivef.job
type=command
command=/opt/lagou/servers/hive-2.3.7/bin/hive -f 'test.sql'将所有job资源文件打到一个zip包中创建工程并上传zip包,启动job
6、定时任务调度
除了手动立即执行工作流任务外,azkaban也支持配置定时任务调度。开启方式如下:
- 首页选择待处理的project
- 选择左边schedule表示配置定时调度信息,选择右边execute表示立即执行工作流任务。
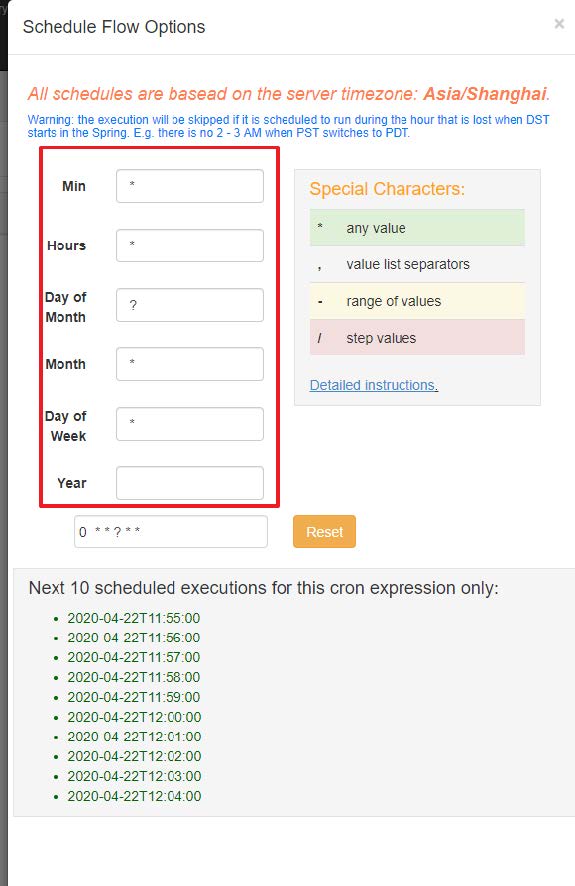
注意:这里面填写的是Cron表达式,如果不会可以参考下面这个网站进行生成。
quartz/Cron/Crontab表达式在线生成工具-BeJSON.com
以上是关于Azkaban使用的主要内容,如果未能解决你的问题,请参考以下文章