Caffe SSD编译训练及测试
Posted 楚兴
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Caffe SSD编译训练及测试相关的知识,希望对你有一定的参考价值。
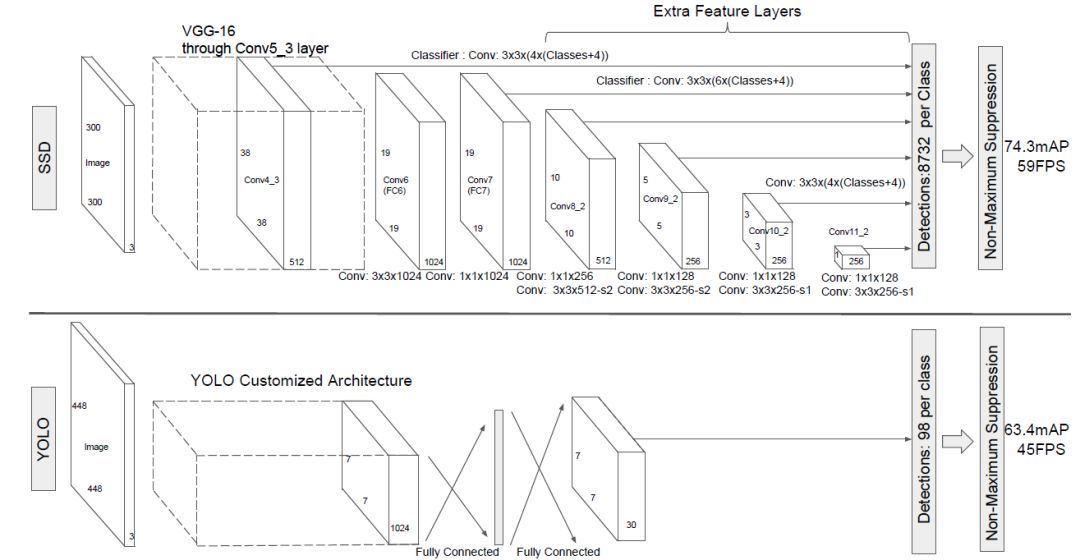
SSD采用VGG16作为基础模型,然后在VGG16的基础上新增了卷积层来获得更多的特征以用于检测。SSD的网络结构如上图所示(上面是SSD模型,下面是Yolo模型),可以明显看到SSD利用了多尺度的特征图做检测。
安装
- clone代码(假设代码clone到
$CAFFE_ROOT目录)。
git clone https://github.com/weiliu89/caffe.git
cd caffe
git checkout ssd
- 编译。这一步骤假设已经安装好caffe环境,caffe的安装可参考:http://caffe.berkeleyvision.org/installation.html
# Modify Makefile.config according to your Caffe installation.
cp Makefile.config.example Makefile.config
make -j8
# Make sure to include $CAFFE_ROOT/python to your PYTHONPATH.
make py
make test -j8
# (Optional)
make runtest -j8
Makefile.config需要根据环境进行修改,我的改动如下:
# cuDNN acceleration switch (uncomment to build with cuDNN).
USE_CUDNN := 1
# CUDA architecture setting: going with all of them.
# For CUDA < 6.0, comment the lines after *_35 for compatibility.
# 我是cuda9.0环境,注释掉:-gencode arch=compute_20,code=sm_20和-gencode arch=compute_20,code=sm_21
CUDA_ARCH := -gencode arch=compute_30,code=sm_30 \\
-gencode arch=compute_35,code=sm_35 \\
-gencode arch=compute_50,code=sm_50 \\
-gencode arch=compute_52,code=sm_52 \\
-gencode arch=compute_61,code=sm_61
准备工作
- 下载VGG模型。假设模型存储在
$CAFFE_ROOT/models/VGGNet目录。 - 下载VOC2007和VOC2012数据集。假设数据存储在
$HOME/data/目录。
# Download the data.
cd $HOME/data
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
# Extract the data.
tar -xvf VOCtrainval_11-May-2012.tar
tar -xvf VOCtrainval_06-Nov-2007.tar
tar -xvf VOCtest_06-Nov-2007.tar
- 创建lmdb文件
cd $CAFFE_ROOT
# Create the trainval.txt, test.txt, and test_name_size.txt in data/VOC0712/
./data/VOC0712/create_list.sh
# You can modify the parameters in create_data.sh if needed.
# It will create lmdb files for trainval and test with encoded original image:
# - $HOME/data/VOCdevkit/VOC0712/lmdb/VOC0712_trainval_lmdb
# - $HOME/data/VOCdevkit/VOC0712/lmdb/VOC0712_test_lmdb
# and make soft links at examples/VOC0712/
./data/VOC0712/create_data.sh
-
问题一:执行
create_list.sh报错报错信息:
terminate called after throwing an instance of 'std::runtime_error'
what(): locale::facet::_S_create_c_locale name not valid
./create_list.sh: line 7: 46203 Aborted $bash_dir/../../build/tools/get_image_size $root_dir $dst_file $bash_dir/$dataset"_name_size.txt"
可以通过export LC_ALL="C"解决。
-
问题二:执行
./create_data.sh报错报错信息:
Traceback (most recent call last):
File "/data/home/chuxing/AI/caffe-ssd/data/VOC0712/../../scripts/create_annoset.py", line 103, in <module>
label_map = caffe_pb2.LabelMap()
AttributeError: 'module' object has no attribute 'LabelMap'
Traceback (most recent call last):
File "/data/home/chuxing/AI/caffe-ssd/data/VOC0712/../../scripts/create_annoset.py", line 103, in <module>
label_map = caffe_pb2.LabelMap()
AttributeError: 'module' object has no attribute 'LabelMap'
可以通过export PYTHONPATH=/data/home/chuxing/AI/caffe-dssd/python解决。
正常情况下的输出:
[root@kenjyli /data/home/chuxing/AI/caffe-ssd/data/VOC0712]# ./create_list.sh
Create list for VOC2007 trainval...
Create list for VOC2012 trainval...
Create list for VOC2007 test...
I1125 18:00:32.029615 47232 get_image_size.cpp:61] A total of 4952 images.
I1125 18:00:34.016815 47232 get_image_size.cpp:100] Processed 1000 files.
I1125 18:00:36.004880 47232 get_image_size.cpp:100] Processed 2000 files.
I1125 18:00:38.001279 47232 get_image_size.cpp:100] Processed 3000 files.
I1125 18:00:39.987417 47232 get_image_size.cpp:100] Processed 4000 files.
I1125 18:00:41.879824 47232 get_image_size.cpp:105] Processed 4952 files.
[root@kenjyli /data/home/chuxing/AI/caffe-ssd/data/VOC0712]# ./create_data.sh
/data/home/chuxing/AI/caffe-ssd/build/tools/convert_annoset --anno_type=detection --label_type=xml --label_map_file=/data/home/chuxing/AI/caffe-ssd/data/VOC0712/../../data/VOC0712/labelmap_voc.prototxt --check_label=True --min_dim=0 --max_dim=0 --resize_height=0 --resize_width=0 --backend=lmdb --shuffle=False --check_size=False --encode_type=jpg --encoded=True --gray=False /data/home/chuxing/AI/caffe-ssd/data/VOCdevkit/ /data/home/chuxing/AI/caffe-ssd/data/VOC0712/../../data/VOC0712/test.txt /data/home/chuxing/AI/caffe-ssd/data/VOCdevkit/VOC0712/lmdb/VOC0712_test_lmdb
I1125 18:03:31.340348 50194 convert_annoset.cpp:122] A total of 4952 images.
I1125 18:03:31.340778 50194 db_lmdb.cpp:35] Opened lmdb /data/home/chuxing/AI/caffe-ssd/data/VOCdevkit/VOC0712/lmdb/VOC0712_test_lmdb
I1125 18:03:35.693153 50194 convert_annoset.cpp:195] Processed 1000 files.
I1125 18:03:39.981063 50194 convert_annoset.cpp:195] Processed 2000 files.
I1125 18:03:44.308907 50194 convert_annoset.cpp:195] Processed 3000 files.
I1125 18:03:48.640877 50194 convert_annoset.cpp:195] Processed 4000 files.
I1125 18:03:52.684872 50194 convert_annoset.cpp:201] Processed 4952 files.
/data/home/chuxing/AI/caffe-ssd/build/tools/convert_annoset --anno_type=detection --label_type=xml --label_map_file=/data/home/chuxing/AI/caffe-ssd/data/VOC0712/../../data/VOC0712/labelmap_voc.prototxt --check_label=True --min_dim=0 --max_dim=0 --resize_height=0 --resize_width=0 --backend=lmdb --shuffle=False --check_size=False --encode_type=jpg --encoded=True --gray=False /data/home/chuxing/AI/caffe-ssd/data/VOCdevkit/ /data/home/chuxing/AI/caffe-ssd/data/VOC0712/../../data/VOC0712/trainval.txt /data/home/chuxing/AI/caffe-ssd/data/VOCdevkit/VOC0712/lmdb/VOC0712_trainval_lmdb
I1125 18:03:53.822151 50373 convert_annoset.cpp:122] A total of 16551 images.
I1125 18:03:53.822559 50373 db_lmdb.cpp:35] Opened lmdb /data/home/chuxing/AI/caffe-ssd/data/VOCdevkit/VOC0712/lmdb/VOC0712_trainval_lmdb
I1125 18:03:59.236438 50373 convert_annoset.cpp:195] Processed 1000 files.
I1125 18:04:04.636438 50373 convert_annoset.cpp:195] Processed 2000 files.
I1125 18:04:09.896461 50373 convert_annoset.cpp:195] Processed 3000 files.
I1125 18:04:15.108736 50373 convert_annoset.cpp:195] Processed 4000 files.
I1125 18:04:20.400451 50373 convert_annoset.cpp:195] Processed 5000 files.
I1125 18:04:25.572449 50373 convert_annoset.cpp:195] Processed 6000 files.
I1125 18:04:30.748452 50373 convert_annoset.cpp:195] Processed 7000 files.
I1125 18:04:35.940444 50373 convert_annoset.cpp:195] Processed 8000 files.
I1125 18:04:41.180445 50373 convert_annoset.cpp:195] Processed 9000 files.
I1125 18:04:46.364439 50373 convert_annoset.cpp:195] Processed 10000 files.
I1125 18:04:51.645030 50373 convert_annoset.cpp:195] Processed 11000 files.
I1125 18:04:56.840816 50373 convert_annoset.cpp:195] Processed 12000 files.
I1125 18:05:02.104444 50373 convert_annoset.cpp:195] Processed 13000 files.
I1125 18:05:07.312445 50373 convert_annoset.cpp:195] Processed 14000 files.
I1125 18:05:12.572444 50373 convert_annoset.cpp:195] Processed 15000 files.
I1125 18:05:17.740444 50373 convert_annoset.cpp:195] Processed 16000 files.
I1125 18:05:20.680899 50373 convert_annoset.cpp:201] Processed 16551 files.
生成的lmdb文件结构树状图:
`-- lmdb
|-- VOC0712_test_lmdb
| |-- data.mdb
| `-- lock.mdb
`-- VOC0712_trainval_lmdb
|-- data.mdb
`-- lock.mdb
训练
命令:
# It will create model definition files and save snapshot models in:
# - $CAFFE_ROOT/models/VGGNet/VOC0712/SSD_300x300/
# and job file, log file, and the python script in:
# - $CAFFE_ROOT/jobs/VGGNet/VOC0712/SSD_300x300/
# and save temporary evaluation results in:
# - $HOME/data/VOCdevkit/results/VOC2007/SSD_300x300/
# It should reach 77.* mAP at 120k iterations.
python examples/ssd/ssd_pascal.py
训练时实际执行的命令保存在文件jobs/VGGNet/VOC0712/SSD_300x300/VGG_VOC0712_SSD_300x300.sh中。
-
问题一:
invalid device ordinal报错信息如下:
F1125 21:27:39.701442 14813 parallel.cpp:130] Check failed: error == cudaSuccess (10 vs. 0) invalid device ordinal
*** Check failure stack trace: ***
@ 0x7fcefc5dd84d google::LogMessage::Fail()
@ 0x7fcefc5df61c google::LogMessage::SendToLog()
@ 0x7fcefc5dd43c google::LogMessage::Flush()
@ 0x7fcefc5dff2e google::LogMessageFatal::~LogMessageFatal()
@ 0x7fcf04067858 caffe::DevicePair::compute()
@ 0x7fcf0406c6dc caffe::P2PSync<>::Prepare()
@ 0x7fcf0406cc5c caffe::P2PSync<>::Run()
@ 0x408c7c train()
@ 0x4064cc main
@ 0x7fcee5b06b35 __libc_start_main
@ 0x406e8d (unknown)
解决方式:
把examples/ssd/ssd_pascal.py中的第332行改为gpus = "0",下面是修改前的配置:
330 # Solver parameters.
331 # Defining which GPUs to use.
332 gpus = "0,1,2,3"
-
问题二:
out of memory报错信息如下:
F1125 22:03:52.982959 45117 syncedmem.cpp:56] Check failed: error == cudaSuccess (2 vs. 0) out of memory
*** Check failure stack trace: ***
@ 0x7fb3c087a84d google::LogMessage::Fail()
@ 0x7fb3c087c61c google::LogMessage::SendToLog()
@ 0x7fb3c087a43c google::LogMessage::Flush()
@ 0x7fb3c087cf2e google::LogMessageFatal::~LogMessageFatal()
@ 0x7fb3c82ea291 caffe::SyncedMemory::to_gpu()
@ 0x7fb3c82e9579 caffe::SyncedMemory::mutable_gpu_data()
@ 0x7fb3c82dad33 caffe::Blob<>::mutable_gpu_diff()
@ 0x7fb3c8522914 caffe::CuDNNConvolutionLayer<>::Backward_gpu()
@ 0x7fb3c8319467 caffe::Net<>::BackwardFromTo()
@ 0x7fb3c83195d1 caffe::Net<>::Backward()
@ 0x7fb3c82f3c43 caffe::Solver<>::Step()
@ 0x7fb3c82f433e caffe::Solver<>::Solve()
@ 0x40916a train()
@ 0x4064cc main
@ 0x7fb3a9da3b35 __libc_start_main
@ 0x406e8d (unknown)
解决方式:
把examples/ssd/ssd_pascal.py中的第337行和第338行,把batch_size和accum_batch_size分别减小一倍,下面是修改前的。
336 # Divide the mini-batch to different GPUs.
337 batch_size = 32 #改为16
338 accum_batch_size = 32 #改为16
参考来源:
[1] https://github.com/weiliu89/caffe/tree/ssd
以上是关于Caffe SSD编译训练及测试的主要内容,如果未能解决你的问题,请参考以下文章