JVM 性能优化
Posted chun_soft
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JVM 性能优化相关的知识,希望对你有一定的参考价值。
1、重新认识 JVM
JVM的大体物理结构图:
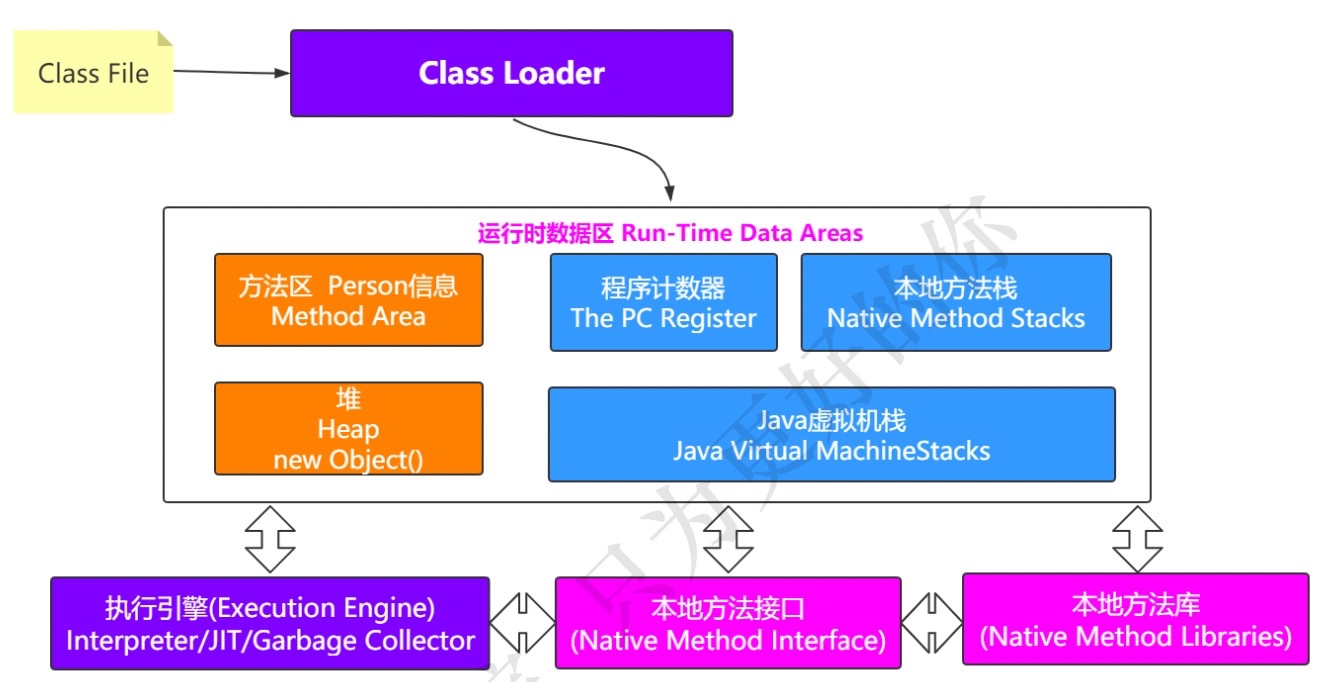
如上面架构图所示,JVM分为三个主要子系统:
(1)类加载器子系统(Class Loader Subsystem);
(2)运行时数据区(Runtime Data Area);
(3)执行引擎(Execution Engine)。
1.1 类加载器子系统(Class Loader Subsystem)
Java的动态类加载功能由类加载器子系统处理,处理过程包括加载和链接,并在类文件运行时,首次引用类时就开始实例化类文件,而不是在编译时进行。
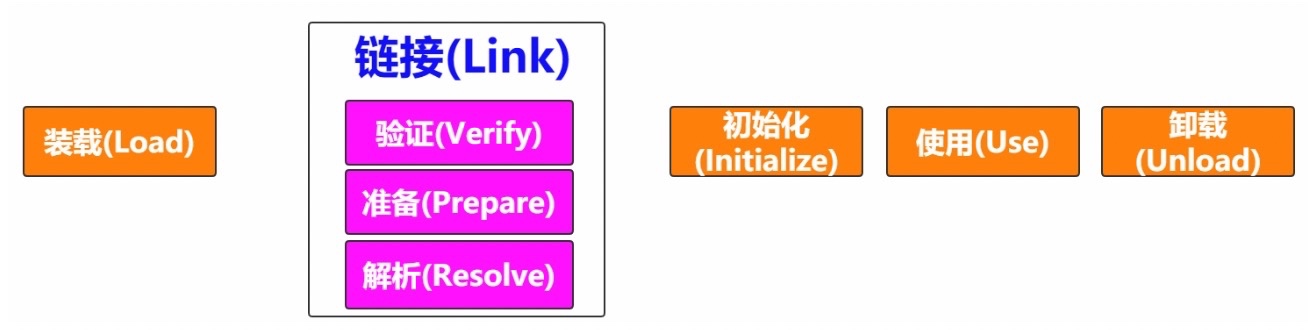
1.1.1 加载
Boot Strap类加载器,Extension类加载器和Application(类加载器是实现类加载过程的三个类加载器。
(1) Boot Strap类加载器:负责从引导类路径加载类,除了rt.jar,它具有最高优先级;
(2) Extension 类加载器:负责加载ext文件夹(jre lib)中的类;
(3) Application类加载器:负责加载应用程序级类路径,环境变量中指定的路径等信息。
上面的类装载器在加载类文件时遵循委托层次算法(Delegation Hierarchy Algorithm)。
1.1.2 链接
(1) 验证(Verify):字节码验证器将验证生成的字节码是否正确,如果验证失败,将提示验证错误;
(2) 准备(Prepare):对于所有静态变量,内存将会以默认值进行分配;
(3) 解释(Resolve):有符号存储器引用都将替换为来自方法区(Method Area)的原始引用。
1.1.3 初始化
这是类加载的最后阶段,所有的静态变量都将被赋予原始值,并且静态区块将被执行。
1.2 运行时数据区(Runtime Data Area)

运行时数据区可分为5个主要组件:
(1) 方法区(Method Area):所有的类级数据将存储在这里,包括静态变量。每个JVM只有一个方法区,它是一个共享资源;
(2) 堆区域(Heap Area):所有对象及其对应的实例变量和数组将存储在这里。每个JVM也只有一个堆区域。由于方法和堆区域共享多个线程的内存,所存储的数据不是线程安全的;
(3) 堆栈区(Stack Area):对于每个线程,将创建单独的运行时堆栈。对于每个方法调用,将在堆栈存储器中产生一个条目,称为堆栈帧。所有局部变量将在堆栈内存中创建。堆栈区域是线程安全的,因为它不共享资源。堆栈框架分为三个子元素:
局部变量数组(Local Variable Array):与方法相关,涉及局部变量,并在此存储相应的值
操作数堆栈(Operand stack):如果需要执行任何中间操作,操作数堆栈将充当运行时工作空间来执行操作
帧数据(Frame Data):对应于方法的所有符号存储在此处。在任何异常的情况下,捕获的区块信息将被保持在帧数据中;
(4) PC寄存器(PC Registers):每个线程都有单独的PC寄存器,用于保存当前执行指令的地址。一旦执行指令,PC寄存器将被下一条指令更新;
(5) 本地方法堆栈(Native Method stacks):本地方法堆栈保存本地方法信息。对于每个线程,将创建一个单独的本地方法堆栈。
1.3 执行引擎(Execution Engine)

分配给运行时数据区的字节码将由执行引擎执行,执行引擎读取字节码并逐个执行。
(1) 解释器:解释器更快地解释字节码,但执行缓慢。解释器的缺点是当一个方法被调用多次时,每次都需要一个新的解释;
(2) JIT编译器:JIT编译器消除了解释器的缺点。执行引擎将在转换字节码时使用解释器的帮助,但是当它发现重复的代码时,将使用JIT编译器,它编译整个字节码并将其更改为本地代码。这个本地代码将直接用于重复的方法调用,这提高了系统的性能。JIT的构成组件为:
中间代码生成器(Intermediate Code Generator):生成中间代码
代码优化器(Code Optimizer):负责优化上面生成的中间代码
目标代码生成器(Target Code Generator):负责生成机器代码或本地代码
分析器(Profiler):一个特殊组件,负责查找热点,即该方法是否被多次调用;
(3) 垃圾收集器(Garbage Collector):收集和删除未引用的对象。可以通过调用“System.gc()”触发垃圾收集,但不能保证执行。JVM的垃圾回收对象是已创建的对象。
Java本机接口(JNI):JNI将与本机方法库进行交互,并提供执行引擎所需的本机库。
本地方法库(Native Method Libraries):它是执行引擎所需的本机库的集合。
2、GC优化
内存被使用了之后,难免会有不够用或者达到设定值的时候,就需要对内存空间进行垃圾回收。
2.1 垃圾收集发生的时机
GC是由JVM自动完成的,根据JVM系统环境而定,所以时机是不确定的。当然,我们可以手动进行垃圾回收,比如调用System.gc()方法通知JVM进行一次垃圾回收,但是具体什么时刻运行也无法控制。也就是说 System.gc()只是通知要回收,什么时候回收由JVM决定。但是不建议手动调用该方法,因为消耗的资源比较大。
一般以下几种情况会发生垃圾回收:
(1)当Eden区或者S区不够用了;
(2)老年代空间不够用了;
(3)方法区空间不够用了;
(4)System.gc()。
2.2 GC 日志文件
要想分析日志的信息,得先拿到GC日志文件才行,所以得先配置一下这些参数。
-XX:+PrintGCDetails 打印GC详细信息
-XX:+PrintGCTimeStamps
-XX:+PrintGCDateStamps
-Xloggc:gc.log 输出到指定文件里
2.2.1 Parallel GC 日志
【吞吐量优先】
[GC (Allocation Failure) [PSYoungGen: 65536K[Young区回收前]->10748K[Young区回收后] (76288K[Young区总大小])] 65536K[整个堆回收前]->15039K[整个堆回收后](251392K[整个堆总大小]), 0.0113277 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
2.2.2
【停顿时间优先】
参数设置:
-XX:+UseConcMarkSweepGC -Xloggc:cms-gc.log
2.2.3 G1日志
【停顿时间优先】
参数设置:
-XX:+UseG1GC -Xloggc:g1-gc.log
-XX:+UseG1GC # 使用了G1垃圾收集器
# 什么时候发生的GC,相对的时间刻,GC发生的区域young,总共花费的时间,0.00478s,
# It is a stop-the-world activity and all
# the application threads are stopped at a safepoint during this time. 2019-12-18T16:06:46.508+0800: 0.458: [GC pause (G1 Evacuation Pause) (young), 0.0047804 secs]
# 多少个垃圾回收线程,并行的时间
[Parallel Time: 3.0 ms, GC Workers: 4]
# GC线程开始相对于上面的0.458的时间刻
[GC Worker Start (ms): Min: 458.5, Avg: 458.5, Max: 458.5, Diff: 0.0]
# This gives us the time spent by each worker thread scanning the roots
# (globals, registers, thread stacks and VM data structures).
[Ext Root Scanning (ms): Min: 0.2, Avg: 0.4, Max: 0.7, Diff: 0.5, Sum: 1.7]
# Update RS gives us the time each thread spent in updating the Remembered Sets.
[Update RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0] ...
2.3 GC日志文件分析工具
(1) gceasy
官网 :https://gceasy.io 可以比较不同的垃圾收集器的吞吐量和停顿时间
比如打开cms-gc.log和g1-gc.log
(2) GCViewer
官网:https://github.com/chewiebug/GCViewer/releases
日志可视化分析工具
2.4 G1调优与最佳指南
2.4.1 调优
是否选用G1垃圾收集器的判断依据:
(1)50%以上的堆被存活对象占用
(2)对象分配和晋升的速度变化非常大
(3)垃圾回收时间比较长
(1)使用G1GC垃圾收集器: -XX:+UseG1GC
修改配置参数,获取到gc日志,使用GCViewer分析吞吐量和响应时间:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uAg5oL9V-1613640913583)(media/15962594637299/15962663182234.jpg)]
(2)调整内存大小再获取gc日志分析
-XX:MetaspaceSize=100M
-Xms300M
-Xmx300M
比如设置堆内存的大小,获取到gc日志,使用GCViewer分析吞吐量和响应时间:

(3)调整最大停顿时间
-XX:MaxGCPauseMillis=20 设置最大GC停顿时间指标
比如设置最大停顿时间,获取到gc日志,使用GCViewer分析吞吐量和响应时间

(4)启动并发GC时堆内存占用百分比
-XX:InitiatingHeapOccupancyPercent=45 G1用它来触发并发GC周期,基于整个堆的使用率,而不只是某一代内存的使用比例。值为 0 则表示“一直执行GC循环)'. 默认值为 45 (例如, 全部的 45% 或者使用了45%).
比如设置该百分比参数,获取到gc日志,使用GCViewer分析吞吐量和响应时间

2.4.2 最佳指南
(1)不要手动设置新生代和老年代的大小,只要设置整个堆的大小
G1收集器在运行过程中,会自己调整新生代和老年代的大小 其实是通过adapt代的大小来调整对象晋升的速度和年龄,从而达到为收集器设置的暂停时间目标 如果手动设置了大小就意味着放弃了G1的自动调优
(2)不断调优暂停时间目标
一般情况下这个值设置到100ms或者200ms都是可以的(不同情况下会不一样),但如果设置成50ms就不太合理。暂停时间设置的太短,就会导致出现G1跟不上垃圾产生的速度。最终退化成Full GC。所以对这个参数的调优是一个持续的过程,逐步调整到最佳状态。暂停时间只是一个目标,并不能总是得到满足。
(3)使用-XX:ConcGCThreads=n来增加标记线程的数量
IHOP如果阀值设置过高,可能会遇到转移失败的风险,比如对象进行转移时空间不足。如果阀值设置过低,就会使标记周期运行过于频繁,并且有可能混合收集期回收不到空间。 IHOP值如果设置合理,但是在并发周期时间过长时,可以尝试增加并发线程数,调高ConcGCThreads。
(4)MixedGC调优
-XX:InitiatingHeapOccupancyPercent -XX:G1MixedGCLiveThresholdPercent -XX:G1MixedGCCountTarger -XX:G1OldCSetRegionThresholdPercent
(5)适当增加堆内存大小
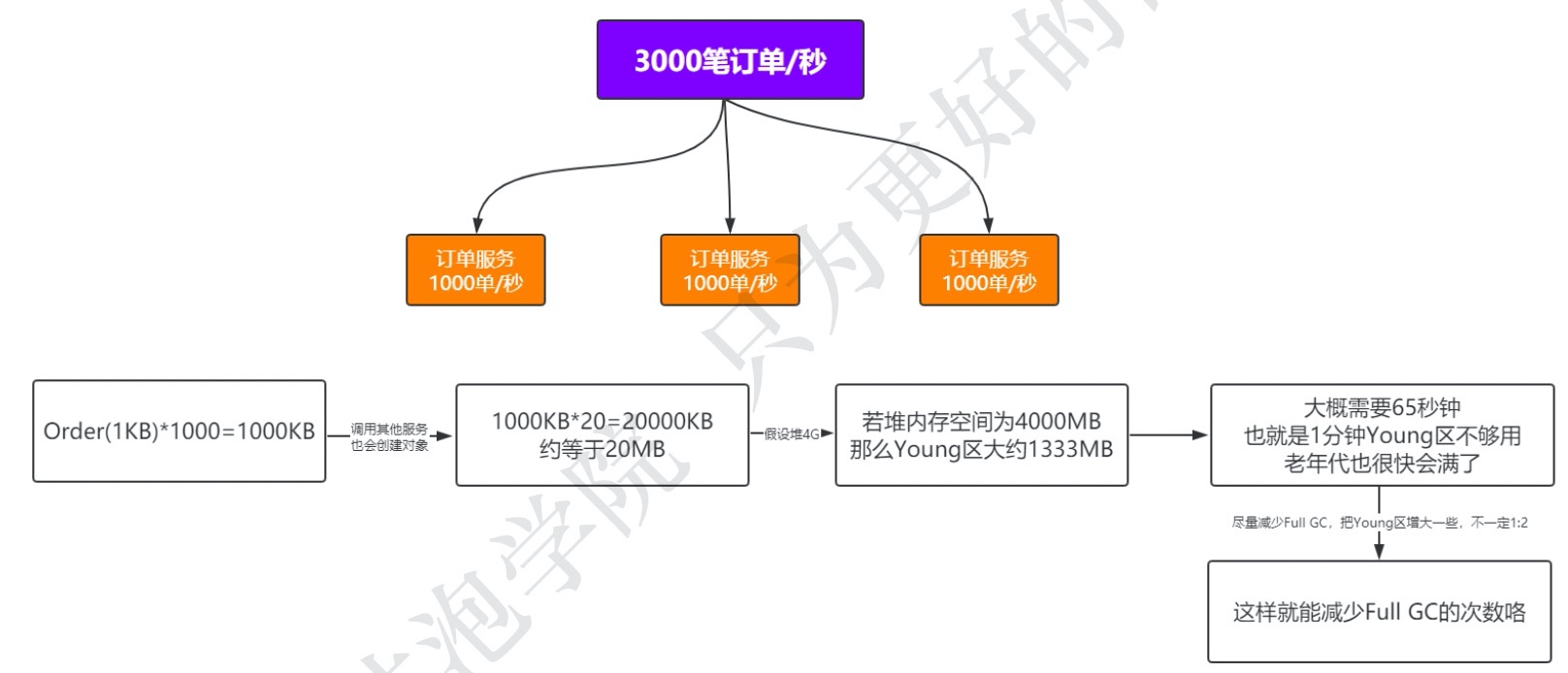
3、高并发场景分析
以每秒3000笔订单为例:
4、JVM性能优化指南
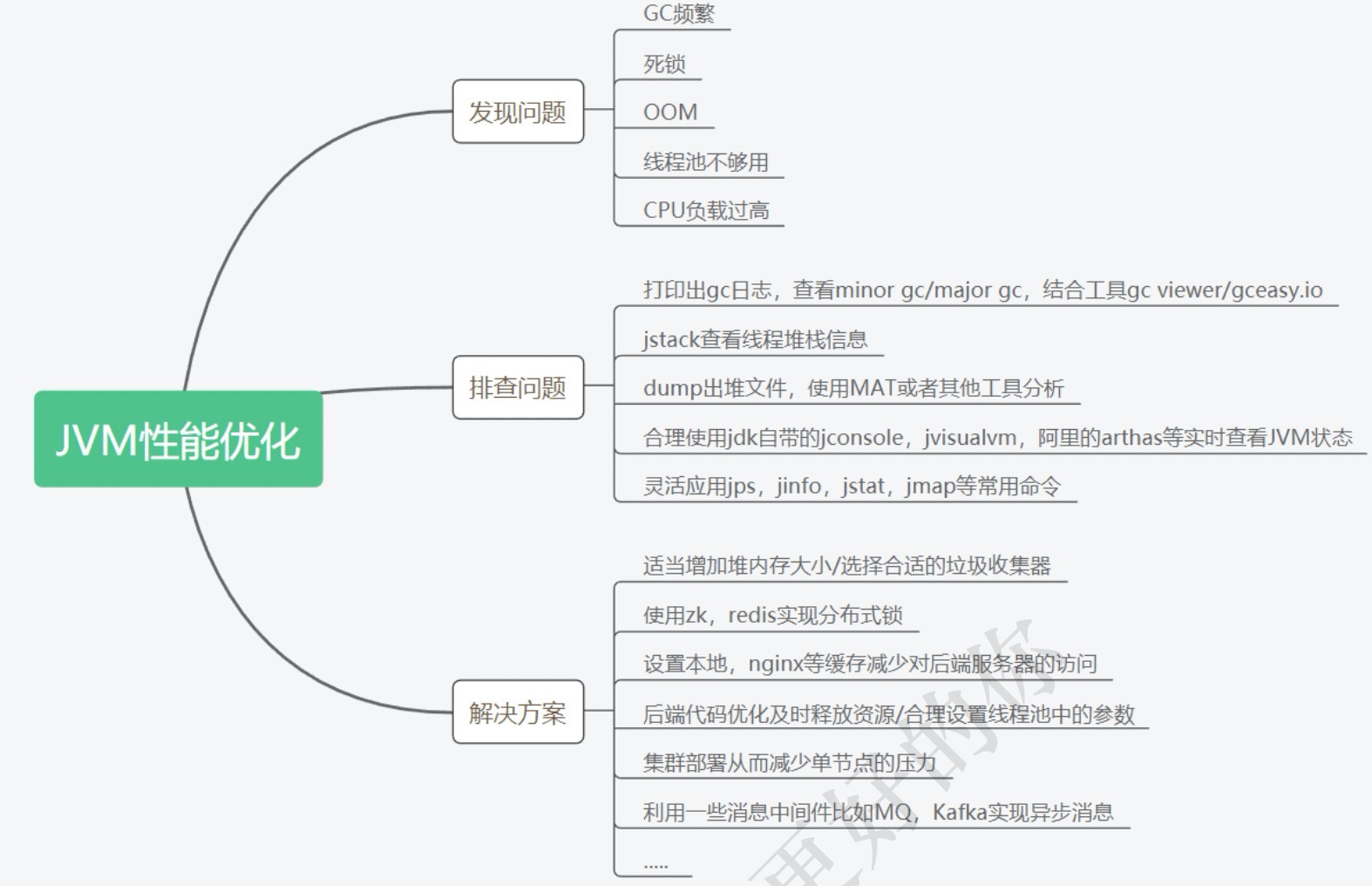
5、常见问题思考
(1)内存泄漏与内存溢出的区别
内存泄漏:对象无法得到及时的回收,持续占用内存空间,从而造成内存空间的浪费。
内存溢出:内存泄漏到一定的程度就会导致内存溢出,但是内存溢出也有可能是大对象导致的。
(2)young gc会有stw吗?
不管什么 GC,都会有 stop-the-world,只是发生时间的长短。
(3)major gc和full gc的区别
major gc指的是老年代的gc,而full gc等于young+old+metaspace的gc。
(4)G1与CMS的区别是什么
CMS 用于老年代的回收,而 G1 用于新生代和老年代的回收。
G1 使用了 Region 方式对堆内存进行了划分,且基于标记整理算法实现,整体减少了垃圾碎片的产生。
(5)什么是直接内存
直接内存是在java堆外的、直接向系统申请的内存空间。通常访问直接内存的速度会优于Java堆。因此出于性能的考虑,读写频繁的场合可能会考虑使用直接内存。
(6)不可达的对象一定要被回收吗?
即使在可达性分析法中不可达的对象,也并非是“非死不可”的,这时候它们暂时处于“缓刑阶段”,要真正宣告一个对象死亡,至少要经历两次标记过程;可达性分析法中不可达的对象被第一次标记并且进行一次筛选,筛选的条件是此对象是否有必要执行 finalize 方法。当对象没有覆盖 finalize 方法,或 finalize 方法已经被虚拟机调用过时,虚拟机将这两种情况视为没有必要执行。
被判定为需要执行的对象将会被放在一个队列中进行第二次标记,除非这个对象与引用链上的任何一个对象建立关联,否则就会被真的回收。
(7)方法区中的无用类回收,方法区主要回收的是无用的类,那么如何判断一个类是无用的类的呢?
判定一个常量是否是“废弃常量”比较简单,而要判定一个类是否是“无用的类”的条件则相对苛刻许多。类需要同时满 足下面 3 个条件才能算是 “无用的类” :
该类所有的实例都已经被回收,也就是 Java 堆中不存在该类的任何实例。
加载该类的 ClassLoader 已经被回收。
该类对应的 java.lang.Class 对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
虚拟机可以对满足上述 3 个条件的无用类进行回收,这里说的仅仅是“可以”,而并不是和对象一样不使用了就会必然被回收。
(8)不同的引用
JDK1.2以后,Java对引用进行了扩充:强引用、软引用、弱引用和虚引用
以上是关于JVM 性能优化的主要内容,如果未能解决你的问题,请参考以下文章