生成对抗网络GAN
Posted Young_Gy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了生成对抗网络GAN相关的知识,希望对你有一定的参考价值。
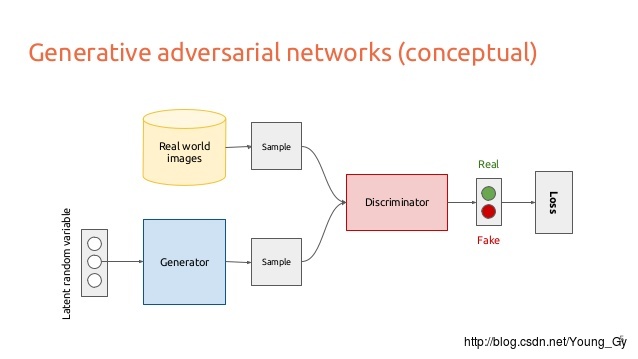
GAN属于生成模型,使用生成数据分布 PG 去无限逼近数据的真实分布 Pdata 。衡量两个数据分布的差异有多种度量,例如KL散度等,但是前提是得知道 PG 。GAN利用discriminator巧妙地衡量了 PG,Pdata 的差异性,利用discriminator和generator的不断竞争(minmax)得到了好的generator去生成数据分布 PG 。
背景
很多时候,我们想输入一类数据,然后让机器学习这一类数据的模式,进而产生该类型新的数据。例如:
- 输入唐诗三百首,输出机器写的唐诗
- 输入一堆动漫人物的照片,输出机器生成的动漫人物照片
该问题的核心是原数据有其分布 Pdata ,机器想要学习新的分布 PG 去无限逼近 Pdata 。
一个简单的解决办法是采用异常检测的模型,通过输入大量的正常数据,让机器学习正常数据的内在规律。例如:自编码器模型如下。通过训练数据学习到数据的内在模式code。学习到code后,随机输入新的code便可以产生数据。
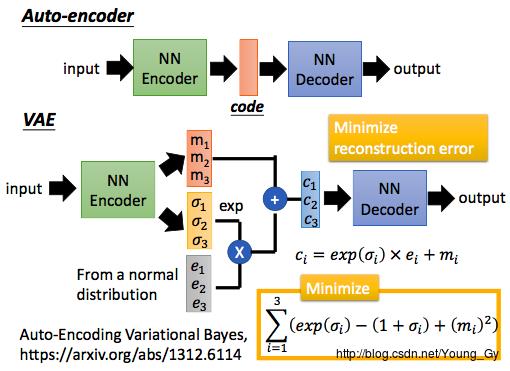
对于mnist数据,设code为2维,训练之后输入code得到的图片如下:

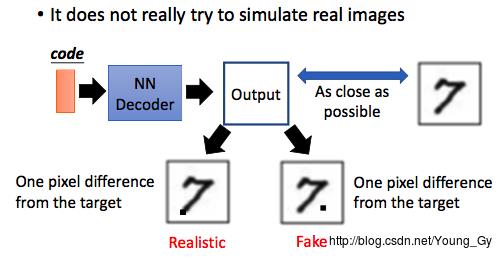
但是这种情况下,机器学习到的只是这个数据大概长什么样,而不是数据的真实分布。例如下图的两个7,在人看来都是真的图片7,但是机器却不这么认为。
结构
GAN由generator和discriminator两部分组成:
z -> G -> x' -> D -> 01
x ->- generator:输入随机的
z
,输出生成的
x′ - discriminator:二分类器,输入生成的 x′ 和真实的 x ,输出01(是否是真的数据)
GAN的训练,也包括generator和discriminator两部分:
discriminator的训练,设generator不变,通过调整discriminator的参数让discriminator尽可能区分开
x,x′ 。
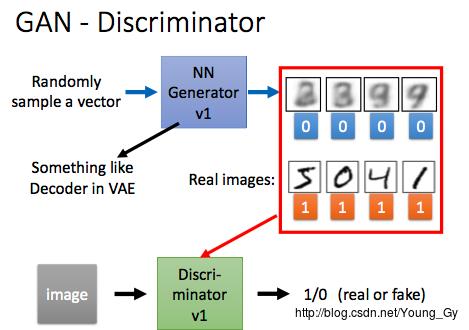
generator的训练,设discriminator不变,通过调整generator的参数让discriminator尽可能区分不开 x,x′ 。

整体来看,generator和discriminator构成了一个网络结构,通过设置loss,保持某一个generator和discriminator参数不变,通过梯度下降更新另外一个的参数即可。
训练
最大似然估计
已知两个分布
Pdata(x)
和
PG(x;θ)
,目标是找到
G
的
采用最大似然估计,有:
θ∗=argmaxθ∏i=1mPG(xi;θ)=argmaxθ∑i=1mlogPG(xi;θ)≈argmaxθEx∼Pdata(x)[logPG(x;θ)]=argmaxθ∫Pdata(x)logPG(x;θ)dx−∫Pdata(x)logPdata(x)dx=argminθ