hive分桶
Posted 海绵不老
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hive分桶相关的知识,希望对你有一定的参考价值。
hive分桶
创建分桶表
建表时指定了CLUSTERED BY,这个表称为分桶表!
分桶: 和MR中分区是一个概念! 把数据分散到多个文件中!
create table stu_buck(id int, name string)
clustered by(id)
SORTED BY (id desc)
into 4 buckets
row format delimited fields terminated by '\\t';
导入数据
创建临时表:
create table stu_buck_tmp(id int, name string)
row format delimited fields terminated by '\\t';
向临时表导入数据
load data local inpath '/home/atguigu/hivedatas/student' into table stu_buck_tmp;
导入数据之前:
需要打开强制分桶开关: set hive.enforce.bucketing=true;
需要打开强制排序开关: set hive.enforce.sorting=true;
导数据:
insert into table stu_buck select * from stu_buck_tmp;

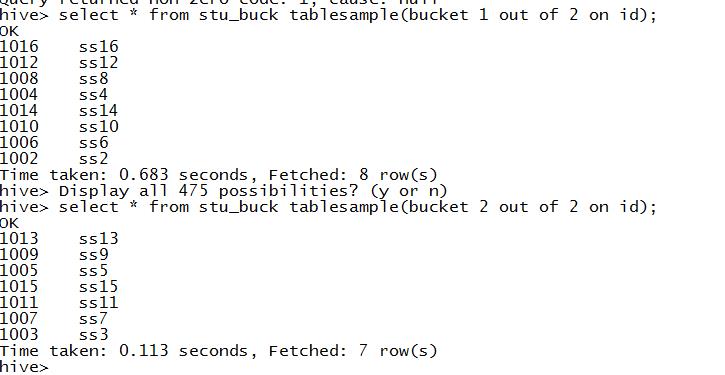
抽样查询
格式:select * from 分桶表 tablesample(bucket x out of y on 分桶表分桶字段);
要求:
①抽样查询的表必须是分桶表!
②bucket x out of y on 分桶表分桶字段
假设当前表一共分了z个桶
x: 从当前表的第几桶开始抽样
0<x<=y
y: z/y 代表一共抽多少桶!
要求y必须是z的因子或倍数!
怎么抽: 从第x桶开始抽样,每间隔y桶抽一桶,知道抽满 z/y桶
bucket 1 out of 2 on id: 从第1桶(0号桶)开始抽,抽第x+y*(n-1),一共抽2桶 : 0号桶,2号桶
select * from stu_buck tablesample(bucket 1 out of 2 on id)
bucket 1 out of 1 on id: 从第1桶(0号桶)开始抽,抽第x+y*(n-1),一共抽4桶 : 0号桶,2号桶,1号桶,3号桶
bucket 2 out of 4 on id: 从第2桶(1号桶)开始抽,一共抽1桶 : 1号桶
bucket 2 out of 8 on id: 从第2桶(1号桶)开始抽,一共抽0.5桶 : 1号桶的一半
以上是关于hive分桶的主要内容,如果未能解决你的问题,请参考以下文章