python深度学习入门-神经网络
Posted 诗雨时
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python深度学习入门-神经网络相关的知识,希望对你有一定的参考价值。
深度学习入门-神经网络
博主微信公众号(左)、Python+智能大数据+AI学习交流群(右):欢迎关注和加群,大家一起学习交流,共同进步!


目录
2.1 sigmoid 函数(sigmoid function)
摘要
- 神经网络中的激活函数使用平滑变化的 sigmoid 函数或 ReLU 函数。
- 通过巧妙地使用 NumPy 多维数组,可以高效地实现神经网络。
- 机器学习的问题大体上可以分为回归问题和分类问题。
- 关于输出层的激活函数,回归问题中一般用恒等函数,分类问题中一般用 softmax 函数。
- 分类问题中,输出层的神经元的数量设置为要分类的类别数。
- 输入数据的集合称为批。通过以批为单位进行推理处理,能够实现高速的运算。
1、从感知机到神经网络
1.1 神经网络的例子
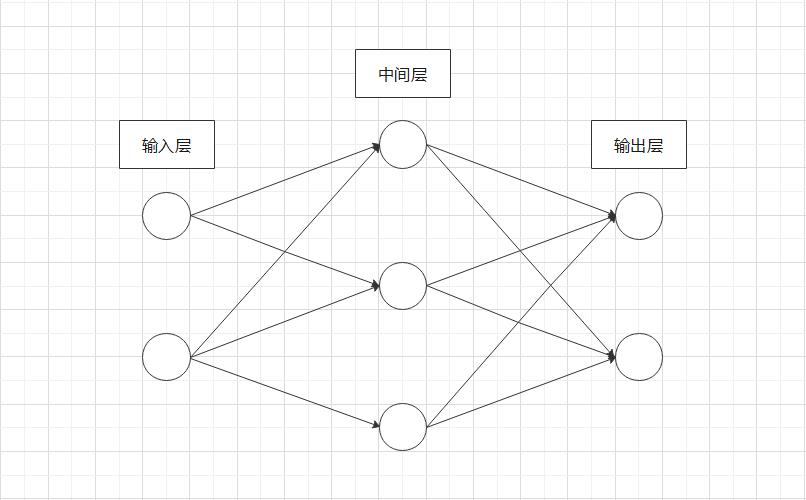
用图来表示神经网络的话,如图 2-1 所示。
我们把最左边的一列称为输入层,最右边的一列称为输出层,中间的一列称为中间层。
中间层有时也称为隐藏层。“隐藏” 一词的意思是,隐藏层的神经元(和输入层、输出层不同)肉眼不可见。
1.2 复习感知机
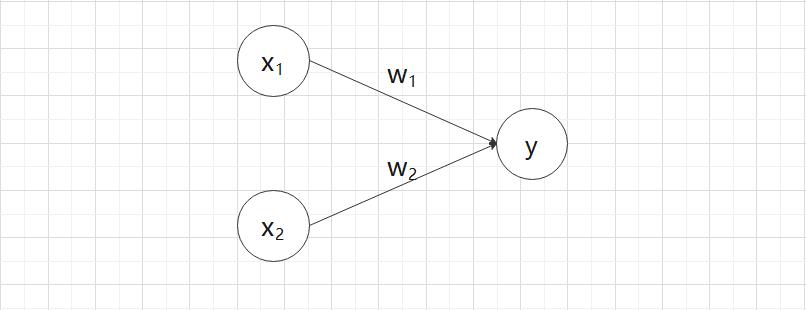
图 2-2 中的感知机接收 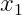 和
和 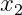 两个输入信号,输出
两个输入信号,输出 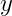 。如果用数学公式来表示图 2-2 的感知机,则如式 (2.1) 所示。
。如果用数学公式来表示图 2-2 的感知机,则如式 (2.1) 所示。

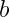 :偏置的参数,用于控制神经元被激活的容易程度;
:偏置的参数,用于控制神经元被激活的容易程度;
 、
、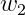 :各个信号的权重的参数,用于控制各个信号的重要性。
:各个信号的权重的参数,用于控制各个信号的重要性。
明确表示出偏置 b 的感知机,如图 2.3 所示。
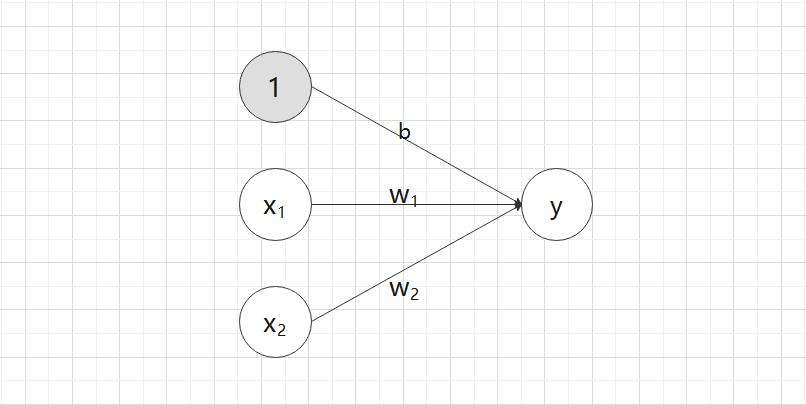
图 2-3 中添加了权重 b 的输入信号 1。
这个感知机将 、、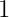 三个信号作为神经元的输入,将其和各自的权重相乘后,传送至下一个神经元。
三个信号作为神经元的输入,将其和各自的权重相乘后,传送至下一个神经元。
在下一个神经元中,计算这些加权信号的总和。如果这个总和超过 0,则输出 1,否则输出 0。
引入新函数 h(x),将式 (2.1) 改写成更加简洁的形式:式 (2.2) 和 式 (2.3)

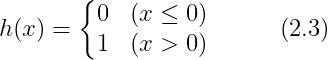
式 (2.2) 中,输入信号的总和会被函数 h(x) 转换,转换后的值就是输出 y。然后,式 (3.3) 所示的函数 h(x),在输入超过 0 时返回 1,否则返回 0。因此,式 (2.1) 和式 (2.2)、式 (2.3) 做的是相同的事。
1.3 激活函数登场
上面提到的 h(x) 函数会将输入信号的总和转换为输出信号,这种函数一般称为激活函数(activation function)。如 “激活” 一词所示,激活函数的作用在于决定如何来激活输入信号的总和。
将式 (2.2) 分两个阶段进行处理:先计算输入信号的加权总和,然后用激活函数转换这一总和。
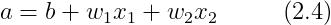

(1)式 (2.4) 计算输入信号和偏置的加权总和,记为 a;
(2)式 (2.5) 用 h() 函数将 a 转换为输出 y。
明确显示激活函数的计算过程:
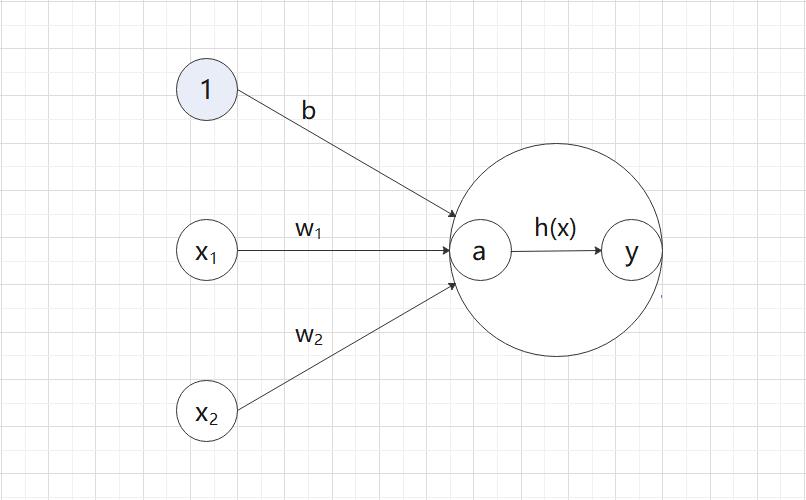
(1)信号的加权总和为节点 a;
(2)节点 a 被激活函数 h() 转换成输出节点 y。
2、激活函数
2.1 sigmoid 函数(sigmoid function)
sigmoid 函数(sigmoid function)数学公式: exp(-x) :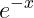 的意思,
的意思,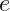 是纳皮尔常数 2.7182...。
是纳皮尔常数 2.7182...。
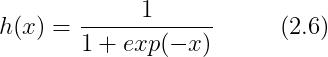
函数:给定某个输入后,会返回某个输出的转换器。比如,向 sigmoid 函数输入 1.0 或 2.0 后,就会有某个值被输出,类似 h(1.0)=0.731...、h(2.0)=0.880...这样。
神经网络中用 sigmoid 函数作为激活函数,进行信号的转换,转换后的信号被传送给下一个神经元。
2.2 阶跃函数的实现
阶跃函数:当输入超过 0 时,输出 1,否则输出 0。
python 实现:
(1)浮点数入参:
import numpy as np
def step_function(x):
"""
阶跃函数
:param x: 入参,只能接受实数(浮点数)
:return:
"""
if x > 0:
return 1
else:
return 0
if __name__ == "__main__":
# 正确传参调用
step_function(3.0)
# 错误传参调用
step_function(np.array([1.0, 2.0]))
(2)Numpy 数组入参:
import numpy as np
def step_function(x):
"""
阶跃函数
:param x: 入参,array([-1.0, 1.0, 2.0])
:return:
"""
y = x > 0 # array([False, True, True])
return y.astype(np.int) # array([0, 1, 1])
if __name__ == "__main__":
x = np.array([-1.0, 1.0, 2.0])
step_function(x)
2.3 阶跃函数的图形
阶跃函数以 0 为界,输出从 0 切换为 1(或者从 1 切换为 0)。它的值呈阶梯式变化,所以称为阶跃函数。
import numpy as np
from matplotlib import pyplot as plt
def step_function(x):
"""
阶跃函数
:param x: 入参
:return:
"""
return np.array(x > 0, dtype=np.int)
if __name__ == "__main__":
# 在-5.0到5.0的范围内,以0.1位单位,生成Numpy数组array([-5.0, -4.9, ... , 4.8, 4.9])
x = np.arange(-5.0, 5.0, 0.1)
y = step_function(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1) # 指定y轴的范围
plt.show()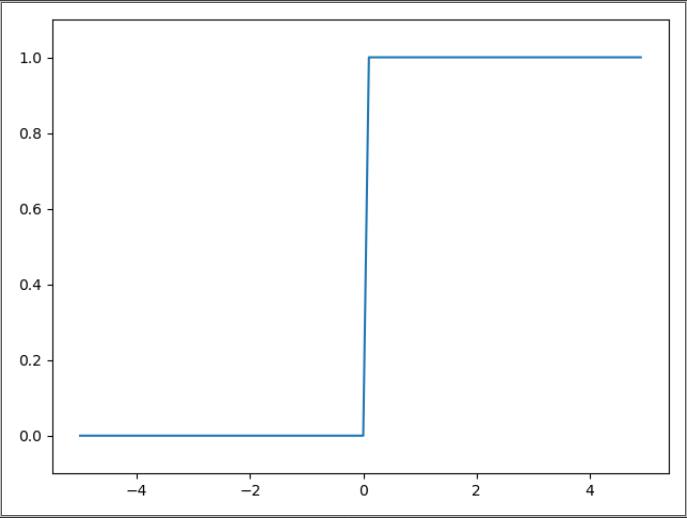
2.4 sigmoid 函数的实现
"""
sigmoid 函数:1 / (1 - exp(-x))
"""
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
if __name__ == "__main__":
x = np.array([-1.0, 1.0, 2.0])
y = sigmoid(x)
print(y)[0.26894142 0.73105858 0.88079708]2.5 sigmoid 函数的图形
"""
sigmoid 函数:1 / (1 - exp(-x))
"""
import numpy as np
from matplotlib import pyplot as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
if __name__ == "__main__":
# 在-5.0到5.0的范围内,以0.1位单位,生成Numpy数组array([-5.0, -4.9, ... , 4.8, 4.9])
x = np.arange(-5.0, 5.0, 0.1)
y = sigmoid(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1) # 指定y轴的范围
plt.show()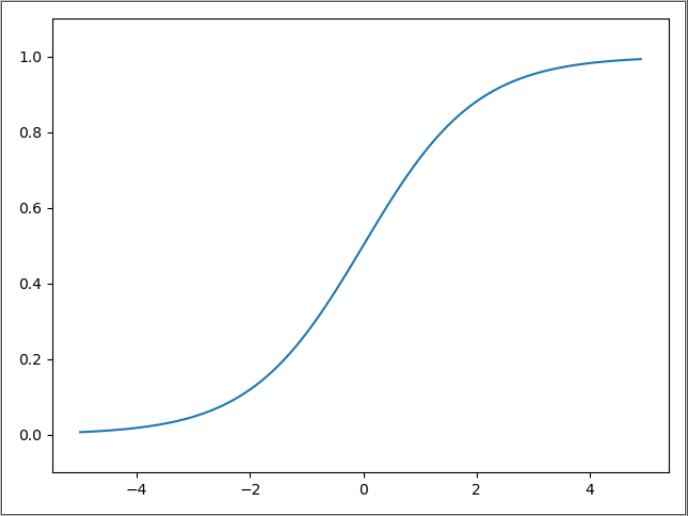
2.6 sigmoid 函数和阶跃函数的比较
"""
sigmoid 函数与阶跃函数图形
"""
import numpy as np
from matplotlib import pyplot as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def step_function(x):
"""
阶跃函数
:param x: 入参
:return:
"""
return np.array(x > 0, dtype=np.int)
if __name__ == "__main__":
# 在-5.0到5.0的范围内,以0.1位单位,生成Numpy数组array([-5.0, -4.9, ... , 4.8, 4.9])
x = np.arange(-5.0, 5.0, 0.1)
y1 = sigmoid(x)
y2 = step_function(x)
plt.plot(x, y1, label='sigmoid function')
plt.plot(x, y2, label='step function')
plt.ylim(-0.1, 1.1) # 指定y轴的范围
plt.legend(loc='best')
plt.show()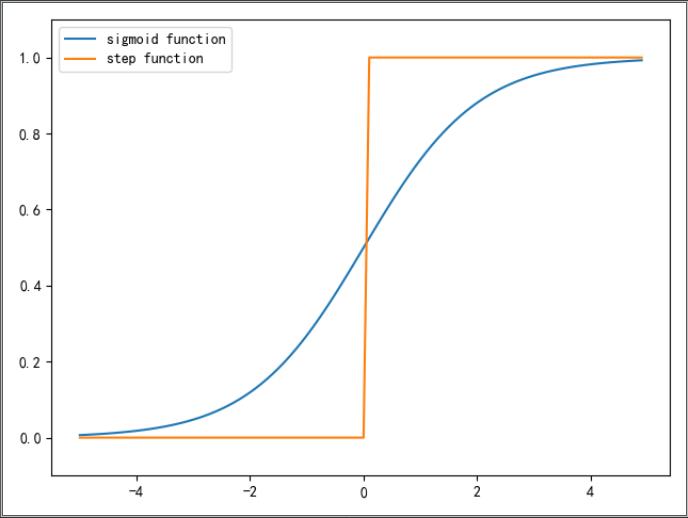
不同点:
(1)“平滑性” 的不同。sigmoid 函数是一条平滑的曲线,输出随着输入发生连续性的变化;阶跃函数以 0 为界,输出发生急剧性的变化。
(2)返回值的不同。sigmoid 函数返回 0.731....、0.880... 等实数;阶跃函数只能返回 0 或 1。
注:感知机中神经元之间流动的是 0 或 1 的二元信号;神经网络中流动的是连续的实数值信号。
相同点:
(1)sigmoid 函数 和阶跃函数具有相似的形状。两者的结构均是 “输入小时,输出接近0(为0);随着输入增大,输出向 1 靠近(变为1)”。
(2)不管输入信号有多小,或者有多大,输出信号的值都在 0 到 1 之间。
(3)sigmoid 函数和阶跃函数都是非线性函数。
注:当输入信号为重要信息时,阶跃函数和sigmoid函数都会输出较大的值;当输入信号为不重要的信息时,两者都输出较小的值。
2.7 非线性函数
函数:输入某个值后会返回一个值的转换器。
线性函数:向函数中输入某个值后,输出值是输入值的常数倍的函数称为线性函数(用数学式表示为 h(x)=cx,c 为常数)。线性函数是一条笔直的直线。
非线性函数:不像线性函数那样呈现出一条直线的函数。
神经网络的激活函数必须使用非线性函数。因为使用线性函数的话,加深神经网络的层数就没有意义了。
神经网络的问题在于,不管如何加深层数,总是存在与之等效的 “无隐藏层的神经网络”。下面举一个简单的例子加以说明:
(1)考虑把线性函数 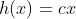 作为激活函数;
作为激活函数;
(2)把 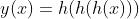 的运算对应 3 层神经网络;
的运算对应 3 层神经网络;
(3)这个运算会进行 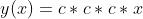 的乘法运算;
的乘法运算;
(4)但是,同样的处理可以由 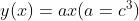 这个一次乘法运算(即没有隐藏层的神经元)来表示。
这个一次乘法运算(即没有隐藏层的神经元)来表示。
2.8 ReLU 函数
ReLU(Rectified Linear Unit)函数:在输入值大于 0 时,直接输出该值;输入值小于 0 时,输出 0 。
ReLU 函数可以表示为下面的式 (2.7)。
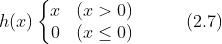
2.9 ReLU 函数图形
"""
ReLU 函数
"""
import numpy as np
from matplotlib import pyplot as plt
def relu(x):
return np.maximum(0, x)
if __name__ == "__main__":
x = np.arange(-5.0, 5.0, 0.1)
y = relu(x)
plt.plot(x, y, label="relu")
plt.ylim(-1, 5.0)
plt.legend(loc='best')
plt.show()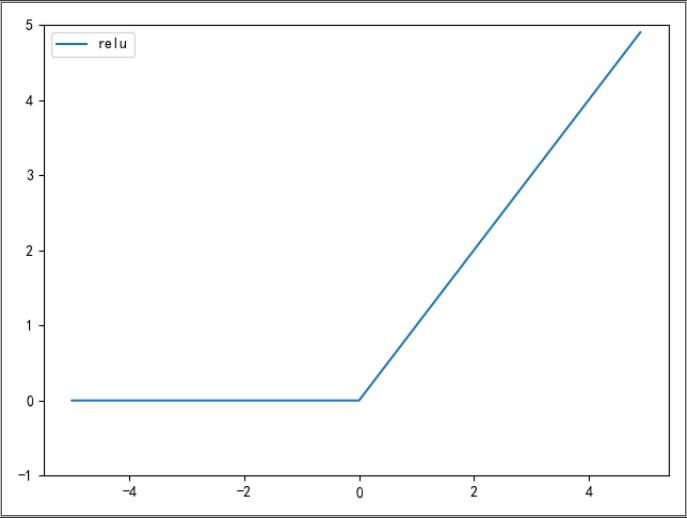
3、多维数组的运算
3.1 多维数组
多维数组:“数字的集合”。数字排成一列的集合、排成长方形的集合、排成三维状或者(更加一般化的)N 维状的集合都成为多维数组。
一维数组:
>>> import numpy as np
>>> A = np.array([1, 2, 3, 4, 5])
>>> print(A)
[1 2 3 4 5]
>>> np.ndim(A)
1
>>> A.shape
(5,)
>>> A.shape[0]
5二维数组:
>>> B = np.array([[1, 2], [3, 4], [5, 6]])
>>> print(B)
[[1 2]
[3 4]
[5 6]]
>>> np.ndim(B)
2
>>> B.shape
(3, 2)
>>> B.shape[1]
2np.ndim():获取数组维度。
np.shape:获取数组形状。
3.2 矩阵乘法
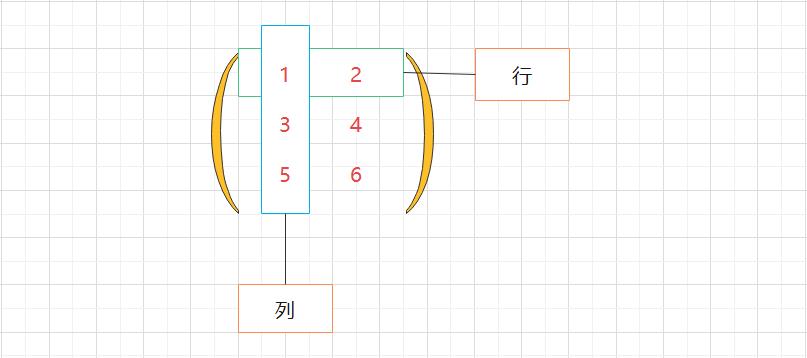
矩阵:二维数组也称为矩阵(matrix)。如图 2-9 所示,数组的横向排列称为行(row),纵向排列称为列(column)。
矩阵乘积(点积)的计算方法:图 2-10 为 2 x 2 的矩阵。
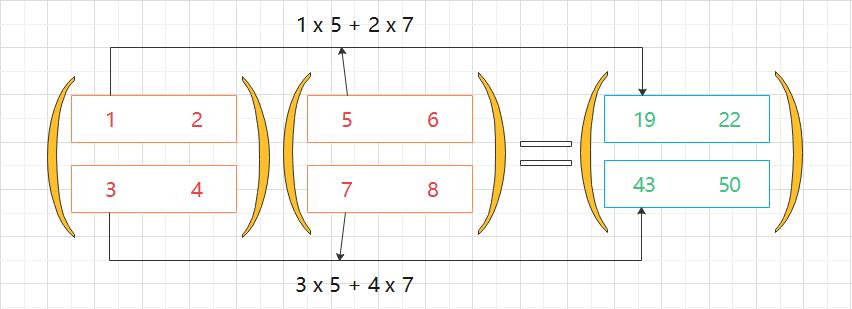
矩阵的乘积是通过左边矩阵的行(横向)和右边矩阵的列(纵向)以对应元素怒的方式相乘后再求和而得到的。并且,运算的结果保存为新的多维数组的元素。
比如:
A 的第 1 行和 B 的第 1 列的乘积结果保存为新数组的第 1 行第 1 列的元素;
A 的第 2 行和 B 的第 1 列的乘积结果保存为新数组的第 2 行第 1 列的元素;
矩阵乘法代码实现:
"""
矩阵乘法
"""
import numpy as np
def matrix_multiplication(x1, x2):
return np.dot(x1, x2)
if __name__ == "__main__":
A = np.array([[1, 2], [3, 4]])
B = np.array([[5, 6], [7, 8]])
product1 = matrix_multiplication(A, B)
product2 = matrix_multiplication(B, A)
print(f"A.shape: A.shape")
print(f"B.shape: B.shape")
print(f"A * B: \\nproduct1")
print(f"B * A: \\nproduct2")A.shape: (2, 2)
B.shape: (2, 2)
A * B:
[[19 22]
[43 50]]
B * A:
[[23 34]
[31 46]]注意:
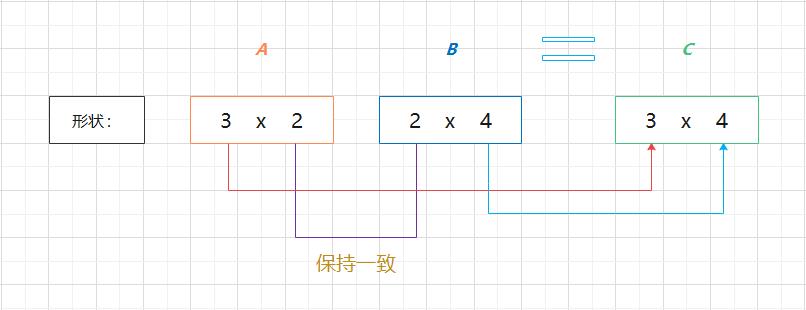
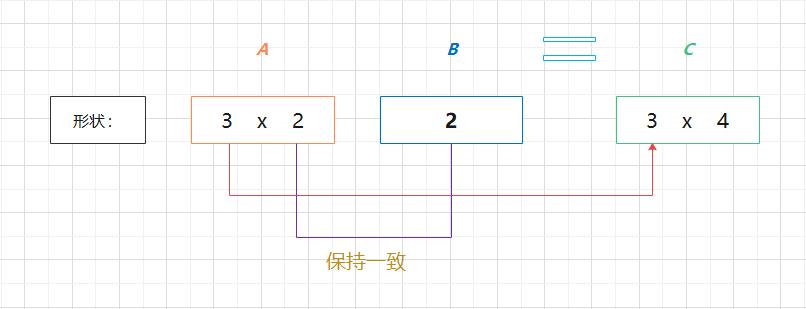
(1)np.dot(A, B) 和 np.dot(B, A) 的值可能不一样。和一般的运算(+ 或 * 等)不同,矩阵的乘积运算中,操作数(A、B)的顺序不同,结果也会不同。
(2)矩阵 A 的第 1 维的元素个数(列数)必须和矩阵 B 的第 0 维的元素个数(行数)相等。
3.3 神经网络的内积
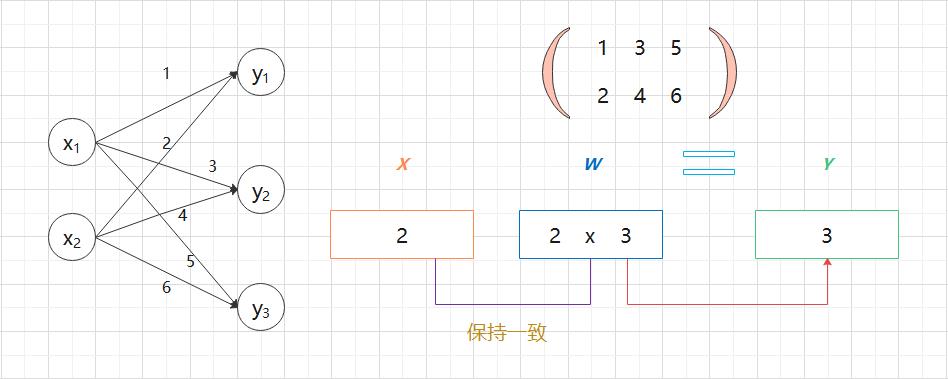
"""
神经网络的点积
"""
import numpy as np
def matrix_multiplication(x1, x2):
return np.dot(x1, x2)
if __name__ == "__main__":
X = np.array([1, 2])
W = np.array([[1, 3, 5], [2, 4, 6]])
product = matrix_multiplication(X, W)
print(f"X.shape: X.shape")
print(f"W.shape: W.shape")
print(f"X * W: \\nproduct")X.shape: (2,)
W.shape: (2, 3)
X * W:
[ 5 11 17]4、3 层神经网络的实现
4.1 符号确认
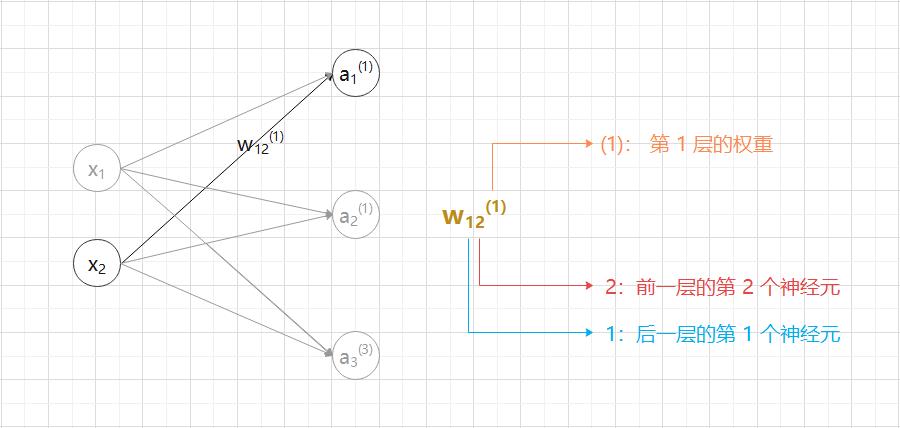
4.2 各层间信号传递的实现
(1)从输入层到第 1 层的信号传递:a — 隐藏层的加权求和;z — 被激活函数转换后的信号;h() — 激活函数。
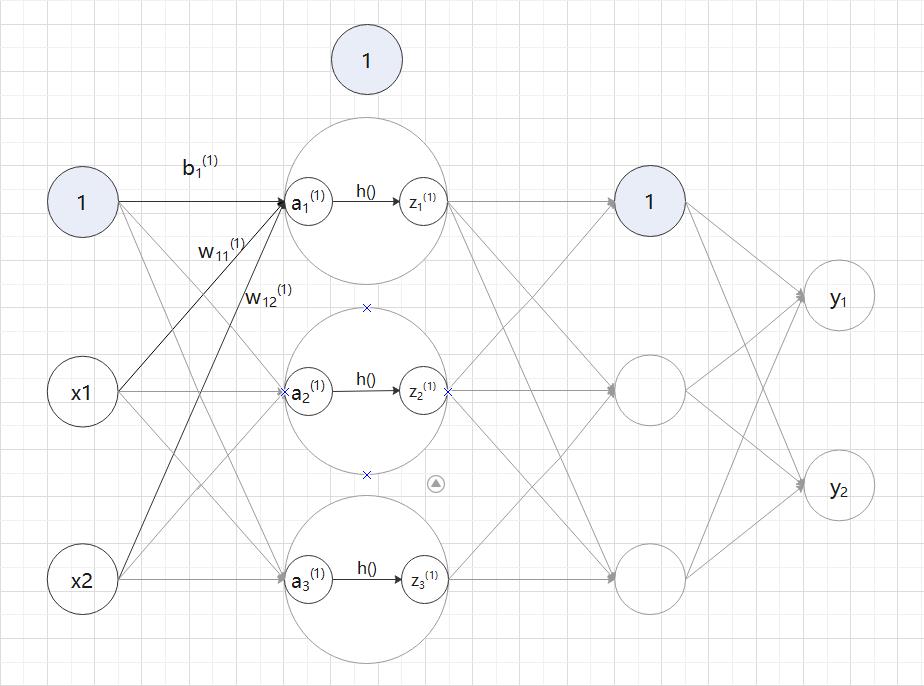
用数学公式表示 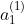 :
:

使用矩阵的乘法运算,可以将第 1 层的加权和表示成下面的式 (2.8)。

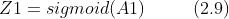
其中 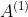 、
、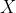 、
、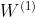 、
、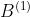 如下所示:
如下所示:




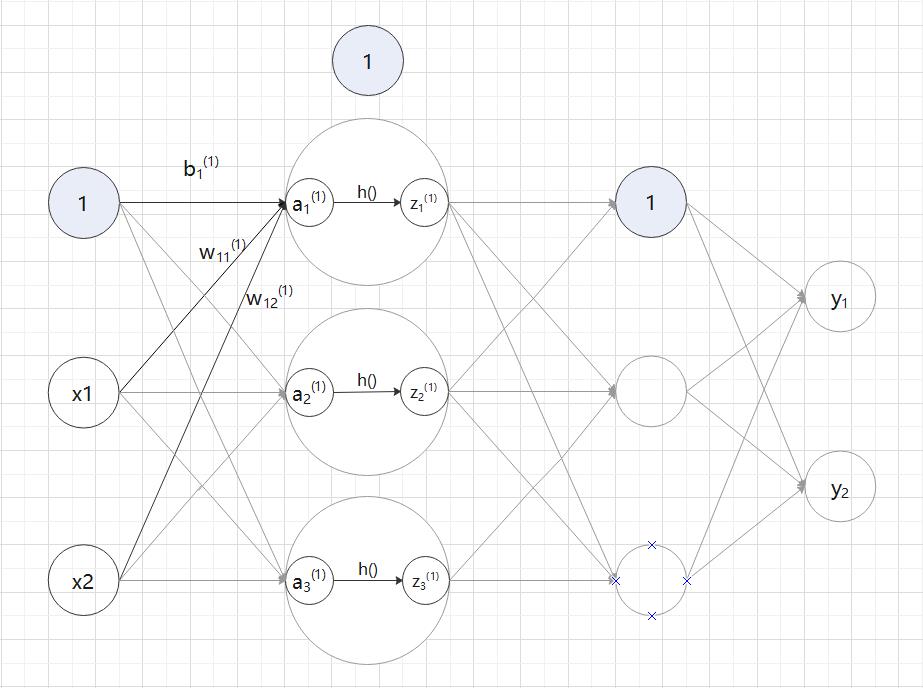
(2)从第 1 层到第 2 层的信号传递:a — 隐藏层的加权求和;z — 被激活函数转换后的信号;h() — 激活函数。
(3)从第 2 层到输出层的信号传递:a — 隐藏层的加权求和;y — 输出层信号; () — 激活函数。
() — 激活函数。
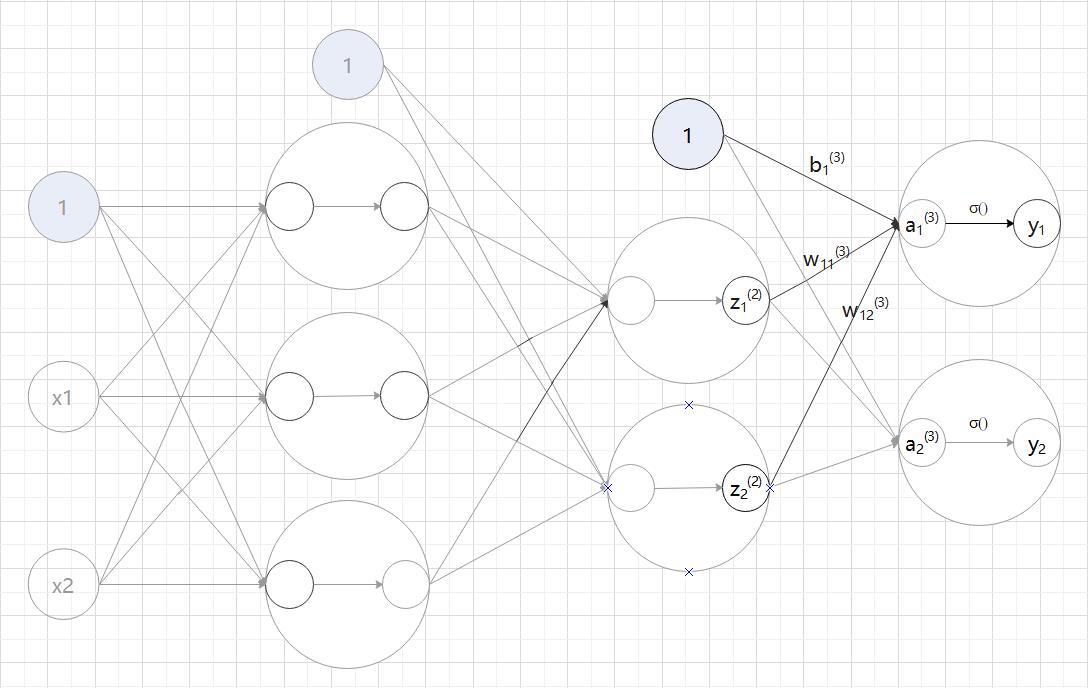
4.3 代码实现
"""
神经网络各层间信号传递的实现
"""
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def identity_function(x):
return x
def init_network():
network =
# 输入层到第1层的权重和偏置
network["w1"] = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])
network["b1"] = np.array([0.1, 0.2, 0.3])
# 第1层到第2层的权重和偏置
network["w2"] = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
network["b2"] = np.array([0.1, 0.2])
# 第2层到输出层的权重和偏置
network["w3"] = np.array([[0.1, 0.3], [0.2, 0.4]])
network["b3"] = np.array([0.1, 0.2])
return network
def forward(network, x):
w1, w2, w3 = network["w1"], network["w2"], network["w3"]
b1, b2, b3 = network["b1"], network["b2"], network["b3"]
# 从输入层到第1层的信号传递
a1 = np.dot(x, w1) + b1
z1 = sigmoid(a1)
# 第1层到第2层的信号传递
a2 = np.dot(z1, w2) + b2
z2 = sigmoid(a2)
# 第2层到输出层的信号传递
a3 = np.dot(z2, w3) + b3
y = identity_function(a3)
return y
network = init_network()
x = np.array([1.0, 0.5])
y = forward(network, x)
print(y) # [0.31682708 0.69627909](1)输出层激活函数的选择
输出层激活函数的选择,要根据求解问题的性质决定,一般地,回归问题可以使用恒等函数,二分类问题可以使用 sigmoid 函数,多元分类问题可以使用softmax 函数。
(2)前向传播
前向:表示的是从输入到输出方向的传递处理。
5、输出层的设计
神经网络可以用在分类问题和回归问题上,不过需要根据情况改变输出层的激活函数。
一般而言,回归问题用恒等函数,分类问题用 softmax 函数。
分类问题:数据属于哪一个类别的问题。比如,区分图像中的人是男性还是女性。
回归问题:根据某个输入预测一个(连续的)数值的问题。比如,根据一个人的图像预测这个人的体重(类似 “57.4kg” 这样的预测)。
5.1 恒等函数和 softmax 函数
(1)恒等函数
恒等函数会将输入按原样输出,对于输入的信息,不加以任何改动地直接输出。因此,在输入层使用恒等函数时,输入信号会原封不动地被输出。
将恒等函数的处理过程用神经网络的图来表示,如图 2-18 所示。
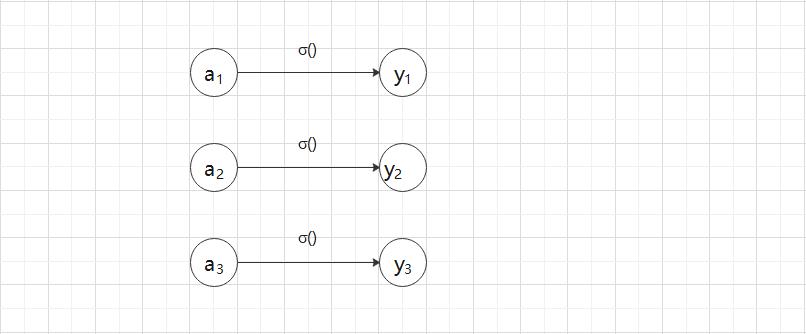
(2)softmax 函数
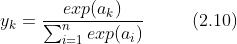
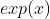 :表示
:表示 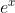 的指数函数(e 是纳皮尔常数 2.7182...)。
的指数函数(e 是纳皮尔常数 2.7182...)。
式 (2.10) 表示假设输出层共有 n 个神经元,计算第 k 个神经元的输出 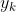 。softmax 函数的分子是输入信号
。softmax 函数的分子是输入信号 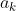 的指数函数,分母是所有输入信号的指数函数的和。
的指数函数,分母是所有输入信号的指数函数的和。
用图表示 softmax 函数,如图 2-19 所示。
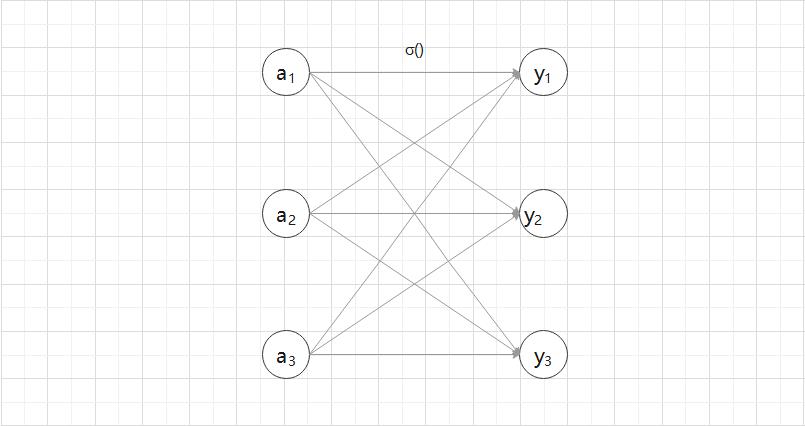
使用代码实现 softmax 函数:
"""
softmax 函数
"""
import numpy as np
def softmax(a):
exp_a = np.exp(a) # 指数函数
sum_exp_a = np.sum(exp_a) # 指数函数的和
y = exp_a / sum_exp_a
return y
if __name__ == "__main__":
a = np.array([0.3, 2.9, 4.0])
y = softmax(a) # [0.01821127 0.24519181 0.73659691]
print(y)5.2 实现 softmax 函数时的注意事项
上面 softmax 函数的实现,在计算机的运算上有一定的缺陷。这个缺陷就是溢出问题。softmax 函数的实现中要进行指数函数的运算,但是此时指数函数的值容易变得非常大。比如,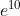 的值会超过20000,
的值会超过20000,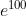 会变成一个后面有 40 多个 0 的超大值,
会变成一个后面有 40 多个 0 的超大值,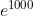 的结果会返回一个表示无穷大的 inf。如果在这些超大值之间进行除法运算,结果会出现 “不确定” 的情况。
的结果会返回一个表示无穷大的 inf。如果在这些超大值之间进行除法运算,结果会出现 “不确定” 的情况。
溢出:计算机处理 “数” 时,数值必须在 4 字节或 8 字节的有限数据宽度内。
这意味着数存在有效位数,也就是说,可以表示的数值范围是有限的。
因此,会出现超大值无法表示的问题。这个问题称为溢出。
结果 “不确定” 的情况:
>>> import numpy as np
>>> a = np.array([1010, 1000, 990])
>>> np.exp(a) / np.sum(np.exp(a))
array([nan, nan, nan])对 softmax 函数进行改进:在进行 softmax 的指数函数的运算时,加上(或者减去)某个常数并不会改变运算的结果。

a、在分子和分母上都乘上 C 这个任意的常数(因为同时对分母和分子乘以相同的常数,所以计算结果不变);
b、把这个 C 移动到指数函数(exp)中,记为 logC;
c、把 logC 替换为另一个符号 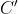 。
。
注:这里的 可以使用任何值,但是为了防止溢出,一般会使用输入信号中的最大值。
改进后的情况:
>>> import numpy as np
>>> a = np.array([1010, 1000, 990])
>>> np.exp(a) / np.sum(np.exp(a))
array([nan, nan, nan])
>>> c = np.max(a)
>>> a - c
array([ 0, -10, -20])
>>> np.exp(a-c) / np.sum(np.exp(a - c))
array([9.99954600e-01, 4.53978686e-05, 2.06106005e-09])"""
softmax 函数
"""
import numpy as np
def softmax(a):
c = np.max(a)
exp_a = np.exp(a - c) # 指数函数,溢出对策:-c
sum_exp_a = np.sum(exp_a) # 指数函数的和
y = exp_a / sum_exp_a
return y
if __name__ == "__main__":
# a = np.array([0.3, 2.9, 4.0])
a = np.array([1010, 1000, 999])
y = softmax(a) # [9.99937902e-01 4.53971105e-05 1.67006637e-05]
print(y)5.3 softmax 函数的特征
使用 softmax 函数,计算神经网络的输出:softmax 函数的输出是 0.0 到 1.0 之间的实数。并且,softmax 函数的输出值的总和是 1(因为这个性质,我们才可以把 softmax 函数的输出解释为 “概率”)。
"""
softmax 函数
"""
import numpy as np
def softmax(a):
c = np.max(a)
exp_a = np.exp(a - c) # 指数函数,溢出对策:-c
sum_exp_a = np.sum(exp_a) # 指数函数的和
y = exp_a / sum_exp_a
return y
if __name__ == "__main__":
a = np.array([0.3, 2.9, 4.0])
y = softmax(a) # [0.01821127 0.24519181 0.73659691]
print(np.sum(y)) # 1.0示例解释:因为第 2 个元素的概率最高,所以答案是第 2 个类别。
a、y[0] 的概率是0.018(1.8%),y[1] 的概率是 0.245(24.5%),y[2] 的概率是 0.737(73.7%);
b、有 73.7% 的概率是第 2 个类别,有 24.5% 的概率是第 1 个类别,有 1.8% 的概率是第 0 个类别。
注意:即便使用了 softmax 函数,各个元素之间的大小关系也不会发生改变。这是因为指数函数(y=exp(x))是单调递增函数。比如 a 的最大值是第 2 个元素,y 的最大值也仍然是第 2 个元素。
5.4 输出层的神经元数量
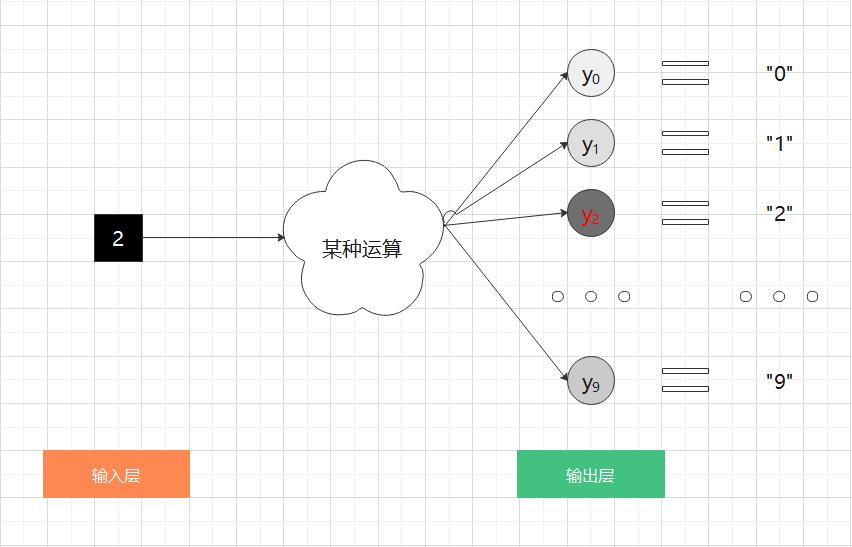
输出层的神经元数量需要根据待解决的问题来决定。对于分类问题,输出层的神经元数量一般设定为类别的数量。
比如,对于某个输入图像,预测是图中的数字 0 到 9 中的哪一个的的问题(10 类别分类问题),可以像图 2-20 这样,将输出层的神经元设定为 10个。
如图 2-10 所示,在这个例子中,输出层的神经元从上往下依次对应数字 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 。此外,图中输出层的神经元的值用不同的灰度表示。这个例子中的神经元 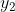 颜色最深,输出的值最大。这表明这个神经网络预测的是 对应的类别,也就是 “2”。
颜色最深,输出的值最大。这表明这个神经网络预测的是 对应的类别,也就是 “2”。
6、手写数字识别
使用神经网络解决问题时,需要首先使用训练数据(学习数据)进行权重参数的学习;进行推理时,使用刚才学习到的参数,对输入数据进行分类。
6.1 MNIST 数据集
提供 6w 张 28*28 像素点(像素的取值在 0 到 255 之间)的 0~9 手写数字图片和标签,用于训练。
提供 1w 张 28*28 像素点(像素的取值在 0 到 255 之间)的 0~9 手写数字图片个标签,用于测试。

(1)下载 MNIST 数据集,并且将这些数据转换成 NumPy 数组(dataset.mnist.py)
"""
手写数字识别
"""
import os
import sys
import gzip
import pickle
import urllib
import numpy as np
base_url = "http://yann.lecun.com/exdb/mnist/"
key_file =
"train_img": "train-images-idx3-ubyte.gz",
"train_label": "train-labels-idx1-ubyte.gz",
"test_img": "t10k-images-idx3-ubyte.gz",
"test_label": "t10k-labels-idx1-ubyte.gz"
dataset_dir = os.path.dirname(os.path.abspath(__file__))
save_file = dataset_dir + "/mnist.pkl"
train_num = 60000
test_num = 10000
img_dim = (1, 28, 28)
img_size = 784
def progressbar(cur, total=100):
percent = ':.2%'.format(cur / total)
sys.stdout.write('\\r')
sys.stdout.write("[%-100s] %s" % ('=' * int(cur), percent))
sys.stdout.flush()
def schedule(block_num, block_size, total_size):
"""
下载百分比
:param block_num: 当前已经下载的块
:param block_size: 每次传输的块大小
:param total_size: 每次传输的块大小
:return:
"""
if total_size == 0:
percent = 0
else:
percent = block_num * block_size / total_size
if percent > 1.0:
percent = 1.0
percent = percent * 100
progressbar(percent)
def _download(file_name):
file_path = dataset_dir + "/" + file_name
if os.path.exists(file_path):
return
print("Downloading " + file_name + " ... ")
urllib.request.urlretrieve(base_url + file_name, file_path, schedule)
print("Done")
def download_mnist():
for v in key_file.values():
_download(v)
def _load_label(file_name):
file_path = dataset_dir + "/" + file_name
print(f"Converting file_name to Numpy Array ...")
with gzip.open(file_path, "rb") as f:
labels = np.frombuffer(f.read(), np.uint8, offset=8)
print("Done")
return labels
def _load_img(file_name):
file_path = dataset_dir + "/" + file_name
print(f"Converting file_name to Numpy Array ...")
with gzip.open(file_path, "rb") as f:
data = np.frombuffer(f.read(), np.uint8, offset=16)
data = data.reshape(-1, img_size)
print("Done")
return data
def _convert_numpy():
dataset =
dataset["train_img"] = _load_img(key_file["train_img"])
dataset["train_label"] = _load_label(key_file["train_label"])
dataset["test_img"] = _load_img(key_file["test_img"])
dataset["test_label"] = _load_label(key_file["test_label"])
return dataset
def init_mnist():
download_mnist()
dataset = _convert_numpy()
print("Creating pickle file ...")
with open(save_file, "wb") as f:
pickle.dump(dataset, f, -1)
print("Done!")
def _change_one_hot_label(X):
T = np.zeros((X.size, 10))
for idx, row in enumerate(T):
row[X[idx]] = 1
return T
def load_mnist(normalize=True, flatten=True, one_hot_label=False):
"""
读入MNIST数据集
:param normalize: 将图像的像素值正规化为 0.0~1.0 的值
:param flatten: 是否将图像展开为一维数组
:param ont_hot_label: 为True的情况下,标签作为one-hot数组返回(one-hot数组:指[0, 0, 1, 0, 0, 0, 0, 0, 0, 0]这样的数组)
:return: (训练图像, 训练标签), (测试图像, 测试标签)
"""
if not os.path.exists(save_file):
init_mnist()
with open(save_file, "rb") as f:
dataset = pickle.load(f)
if normalize:
for key in ("train_img", "test_img"):
dataset[key] = dataset[key].astype(np.float32)
dataset[key] /= 255.0
if one_hot_label:
dataset["train_label"] = _change_one_hot_label(dataset["train_label"])
dataset["test_label"] = _change_one_hot_label(dataset["test_label"])
if not flatten:
for key in ("train_img", "test_img"):
dataset[key] = dataset[key].reshape(-1, 1, 28, 28)
return (dataset["train_img"], dataset["train_label"]), (dataset["test_img"], dataset["test_label"])
if __name__ == "__main__":
init_mnist()(2)显示 MNIST 图像
"""
显示MNIST图像
"""
import os
import sys
import numpy as np
from PIL import Image
sys.path.append(os.pardir)
from dataset.mnist import load_mnist
def img_show(img):
# Image.fromarray() 将保存为 NumPy 数组的图像数据转换为 PIL 用的数据对象
pil_img = Image.fromarray(np.uint8(img))
pil_img.show()
# (训练图像, 训练标签), (测试图像, 测试标签)
(x_train, y_train), (x_test, y_test) = load_mnist(normalize=False, flatten=True)
img = x_train[0]
label = y_train[0]
print(label) # 5
print(img.shape) # (784,)
img = img.reshape(28, 28) # 把图像的形状变成原来的尺寸
print(img.shape) # (28, 28)
img_show(img)
6.2 神经网络的推理
正规化(normalization):将数据限定到某个范围内的处理。
预处理(pre-processing):对神经网络的输入数据进行某种既定的转换。
数据白化(whitening):将数据整体的分布状态均匀化。
"""
神经网络的推理处理
"""
import os
import sys
import pickle
import numpy as np
from datetime import datetime
sys.path.append(os.pardir)
from dataset.mnist import load_mnist
def sigmoid(x):
"""
sigmoid 激活函数
:param x:
:return:
"""
return 1 / (1 + np.exp(-x))
def softmax(x):
"""
softmax 激活函数
:param x:
:return:
"""
if x.ndim == 2:
x = x.T
x = x - np.max(x, axis=0)
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
x = x - np.max(x) # 溢出对策
return np.exp(x) / np.sum(np.exp(x))
def get_data():
"""
获取 MNIST 数据集
:return:
"""
(x_trian, y_train), (x_test, y_test) = load_mnist(normalize=True, flatten=True, one_hot_label=False)
return x_test, y_test
def init_network():
"""
生成网络
:return:
"""
with open("dataset/sample_weight.pkl", "rb") as f:
network = pickle.load(f)
return network
def predict(network, x):
"""
图像分类
:param network:
:param x:
:return:
"""
w1, w2, w3 = network["W1"], network["W2"], network["W3"]
b1, b2, b3 = network["b1"], network["b2"], network["b3"]
a1 = np.dot(x, w1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, w2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, w3) + b3
y = softmax(a3)
return y
x_test, y_test = get_data()
network = init_network()
accuracy_cnt = 0
start_time = datetime.now()
# for 循环逐一取出数据集中的图像数据,使用 predict() 函数进行分类
for i in range(len(x_test)):
y = predict(network, x_test[i])
p = np.argmax(y) # 获取概率最高的元素的索引
if p == y_test[i]:
accuracy_cnt += 1
print(f"Accuracy: float(accuracy_cnt) / len(x_test)")
end_time = datetime.now()
print(f"run time: end_time - start_time")
# Accuracy: 0.9352
# run time: 0:00:00.781155
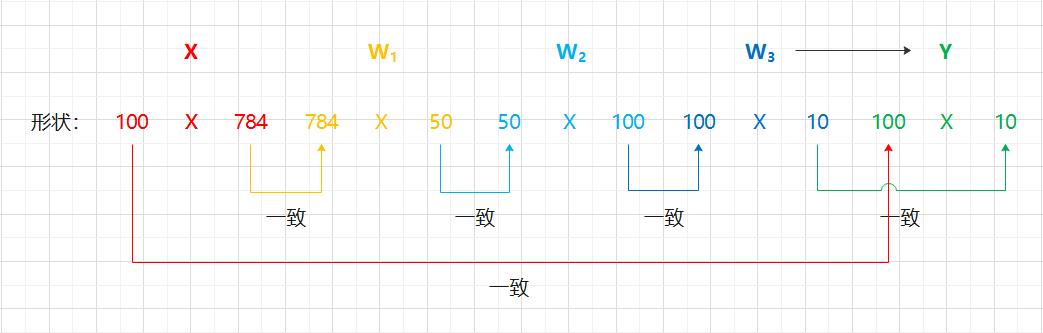
6.3 批处理
>>> x_test, y_test = get_data()
>>> network = init_network()
>>> w1, w2, w3 = network["W1"], network["W2"], network["W3"]
>>>
>>> x_test.shape
(10000, 784)
>>> x_test[0].shape
(784, 0)
>>> w.shape
(784, 50)
>>> w2.shape
(50, 100)
>>> w3.shape
(100, 10)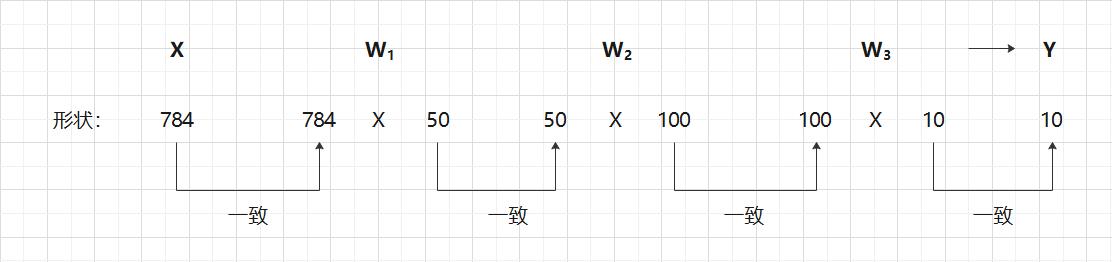
"""
神经网络的推理处理
"""
import os
import sys
import pickle
import numpy as np
from datetime import datetime
sys.path.append(os.pardir)
from dataset.mnist import load_mnist
def sigmoid(x):
"""
sigmoid 激活函数
:param x:
:return:
"""
return 1 / (1 + np.exp(-x))
def softmax(x):
"""
softmax 激活函数
:param x:
以上是关于python深度学习入门-神经网络的主要内容,如果未能解决你的问题,请参考以下文章