深度学习Deep Learning(04):权重初始化问题2_ReLu激励函数
Posted 莫失莫忘Lawlite
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习Deep Learning(04):权重初始化问题2_ReLu激励函数相关的知识,希望对你有一定的参考价值。
三、权重初始化问题2_ReLu激励函数
1、说明
- 参考论文:https://arxiv.org/pdf/1502.01852v1.pdf
- 或者查看这里,我放在github上了:https://github.com/lawlite19/DeepLearning_Python/blob/master/paper/Delving%20Deep%20into%20Rectifiers%20Surpassing%20Human-Level%20Performance%20on%20ImageNet%20Classification%EF%BC%88S%E5%9E%8B%E5%87%BD%E6%95%B0%E6%9D%83%E9%87%8D%E5%88%9D%E5%A7%8B%E5%8C%96%EF%BC%89.pdf
2、ReLu/PReLu激励函数
- 目前
ReLu激活函数使用比较多,而上面一篇论文没有讨论,如果还是使用同样初始化权重的方法(Xavier初始化)会有问题 - PReLu函数定义如下:

- 等价于:
- ReLu(左)和PReLu(右)激活函数图像

3、前向传播推导
- 符号说明
- ε……………………………………目标函数
- μ……………………………………动量
- α……………………………………学习率
- f()………………………………激励函数
- l……………………………………当前层
- L……………………………………神经网络总层数
- k……………………………………过滤器
filter的大小 - c……………………………………输入通道个数
- x……………………………………
k^2c*1的向量 - d……………………………………过滤器
filter的个数 - b……………………………………偏置向量
……………………………………………………..(1)
- 根据式
(1)得:
…………………………………………..(2)
- 因为初始化权重
w均值为0,所以期望:,方差:
- 根据式
(2)继续推导:
 ……………………………………..(3)
……………………………………..(3)
- 对于
x来说:,除非
x的均值也是0, - 对于
ReLu函数来说:,所以不可能均值为0
- 对于
w满足对称区间的分布,并且偏置,所以
也满足对称区间的分布,所以:
 ……………………………………(4)
……………………………………(4)- 将上式
(4)代入(3)中得:
……………………………………………….(5)
- 所以对于
L层:
……………………………………………………………(6)
- 从上式可以看出,因为累乘的存在,若是
,每次累乘都会使方差缩小,若是大于
1,每次会使方差当大。 - 所以我们希望:
- 从上式可以看出,因为累乘的存在,若是
- 所以初始化方法为:是
w满足均值为0,标准差为的高斯分布,同时偏置初始化为
0
4、反向传播推导
…………………………………………….(7)
- 假设
 和
和相互独立的
- 当初始化Wie对称区间的分布时,可以得到:
的均值为0
△x,△y都表示梯度,即:
,
- 假设
- 根据反向传播:
- 对于
ReLu函数,f的导数为0或1,且概率是相等的,假设和
是相互独立的,
- 所以:
- 对于
- 所以:
……………………………………………(8)
- 根据
(7)可以得到:
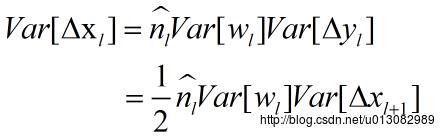
- 将
L层展开得:
…………………………………………………..(9)
同样令:
- 注意这里:
,而
- 注意这里:
所以
应满足均值为0,标准差为:
的分布
5、正向和反向传播讨论、实验和PReLu函数
- 对于正向和反向两种初始化权重的方式都是可以的,论文中的模型都能够收敛
- 比如利用反向传播得到的初始化得到:
对应到正向传播中得到:

所以也不是逐渐缩小的
- 实验给出了与第一篇论文的比较,如下图所示,当神经网络有30层时,Xavier初始化权重的方法(第一篇论文中的方法)已经不能收敛。

- 对于PReLu激励函数可以得到:
- 当
a=0时就是对应的ReLu激励函数 - 当
a=1是就是对应线性函数
- 当
以上是关于深度学习Deep Learning(04):权重初始化问题2_ReLu激励函数的主要内容,如果未能解决你的问题,请参考以下文章