练拳不练功,到老一场空深入浅出计算机组成原理
Posted 结构化思维wz
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了练拳不练功,到老一场空深入浅出计算机组成原理相关的知识,希望对你有一定的参考价值。
深入浅出计算机组成原理
文章目录
- 深入浅出计算机组成原理
练拳不练功,到老一场空
本文是:深入浅出计算机组成原理 (geekbang.org) 学习笔记。有些概念如果不容易理解可以去B站抖音等搜索相关视频,B站推荐:硬件茶谈
如果越早去弄清楚计算机的底层原理,在你的知识体系中“储蓄”起这些知识,也就意味着你有越长的时间来收获学习知识的“利息”。虽然一开始可能不起眼,但是随着时间带来的复利效应,你的长线投资项目,就能让你在成长的过程中越走越快。
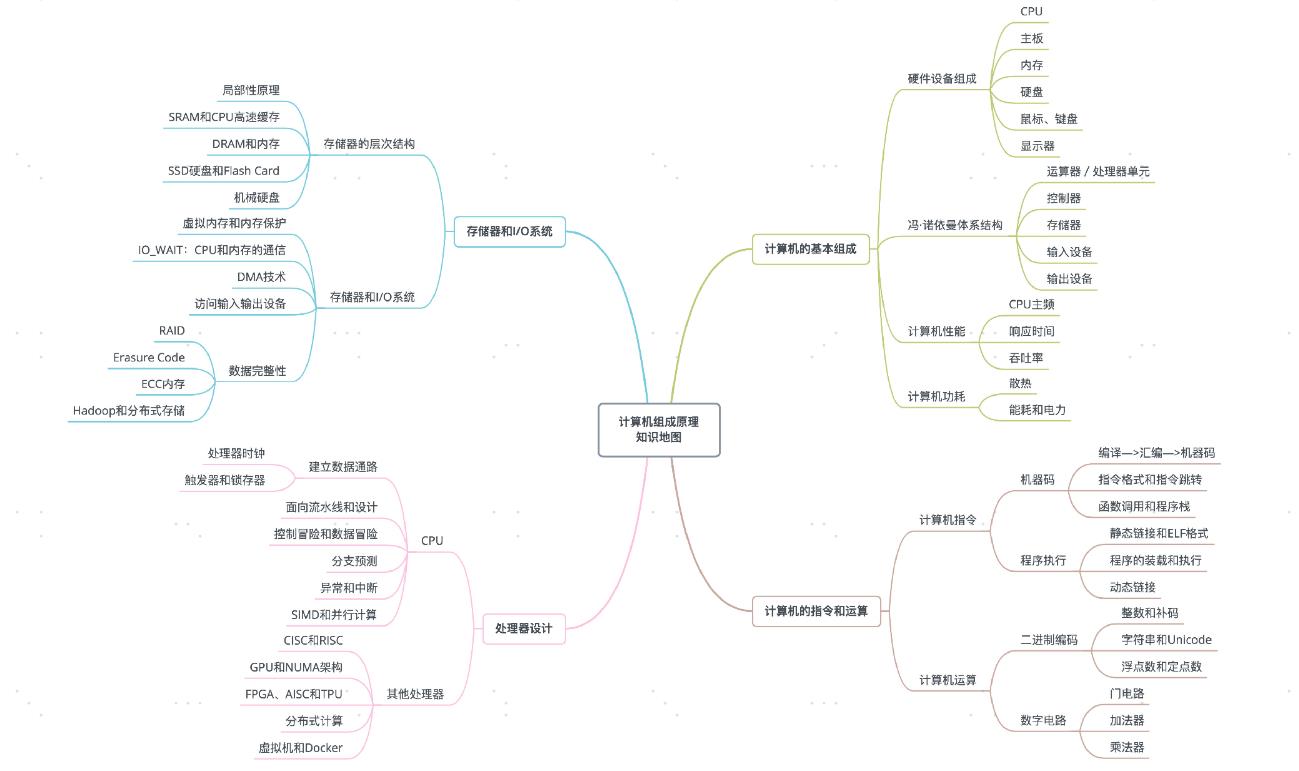
计算机的基本组成
硬件设备组成
**假如我们要自己组装一台计算机。**首先我们要有三大件:CPU、内存、主板
CPU
CPU,全名中央处理器(Central Processing Unit),计算机的所有“计算 ”都是由CPU来进行的。

内存
你撰写的程序、打开的浏览器、运行的游戏,都要加载到内存里才能运行。程序读取的数据、计算得到的结果,也都要放在内存里。内存越大,能加载的东西自然也就越多。

主板
存放在内存里的程序和数据,需要被 CPU 读取,CPU 计算完之后,还要把数据写回到内存。然而 CPU 不能直接插到内存上,反之亦然。
主板是一个有着各种各样,有时候多达数十乃至上百个插槽的配件。我们的 CPU 要插在主板上,内存也要插在主板上。主板的芯片组(Chipset)和总线(Bus)解决了 CPU 和内存之间如何通信的问题。芯片组控制了数据传输的流转,也就是数据从哪里到哪里的问题。总线则是实际数据传输的高速公路。因此,总线速度(Bus Speed)决定了数据能传输得多快。

I/O 设备
输入设备: 显示器…
输入设备: 鼠标、键盘…
鼠标、键盘以及硬盘,这些都是插在主板上的。作为外部 I/O 设备,它们是通过主板上的南桥(SouthBridge)芯片组,来控制和 CPU 之间的通信的。“南桥”芯片的名字很直观,一方面,它在主板上的位置,通常在主板的“南面”。另一方面,它的作用就是作为“桥”,来连接鼠标、键盘以及硬盘这些外部设备和 CPU 之间的通信。
硬盘
有了硬盘,这样各种数据才能持久地保存下来。

如果你去过网吧,那么你会发现,很多网吧的计算机没有硬盘,而是直接通过局域网,读写远程网络硬盘里的数据,类似于我们日常使用的云服务器。
显卡
现在,使用图形界面操作系统的计算机,无论是 Windows、Mac OS 还是 Linux,显卡都是必不可少的。有人可能要说了,我装机的时候没有买显卡,计算机一样可以正常跑起来啊!那是因为,现在的主板都带了内置的显卡。如果你用计算机玩游戏,做图形渲染或者跑深度学习应用,你多半就需要买一张单独的显卡,插在主板上。显卡之所以特殊,是因为显卡里有除了 CPU 之外的另一个“处理器”,也就是GPU(Graphics Processing Unit,图形处理器),GPU 一样可以做各种“计算”的工作。

冯.诺依曼体系结构
智能手机和电脑的硬件组成方式不太一样,但是我们写智能手机上的
App,和写个人电脑的客户端应用似乎没有什么差别,都是通过“高级语言”这样的编程语言撰写、编译之后,一样是把代码和数据加载到内存里来执行。这是为什么呢?因为,无论是个人电脑、服务器、智能手机,还是 Raspberry Pi 这样的微型卡片机,都遵循着同一个“计算机”的抽象概念。
计算机祖师爷之一 冯·诺依曼(John von Neumann)提出的冯·诺依曼体系结构(Von Neumannarchitecture),也叫存储程序计算机。
**什么是存储程序计算机呢?**这里面其实暗含了两个概念,一个是“可编程”计算机,一个是“存储”计算机。
计算机是由各种
门电路组合而成的,然后通过组装出一个固定的电路版,来完成一个特定的计算程序。一旦需要修改功能,就要重新组装电路。这样的话,计算机就是**“不可编程”的,因为程序在计算机硬件层面是“写死”的。最常见的就是老式计算器**,电路板设好了加减乘除,做不了任何计算逻辑固定之外的事情。
冯诺伊曼体系结构:

运算器/处理器单元
完成各种算术、逻辑运算和数据传输等数据加工处理
- 算数运算:加、减、乘、除法等
- 逻辑运算:与、或、非、移位等
- 基本结构
- ALU(Arithmetic Logical Unit):算术逻辑运算单元
- 寄存器
- 连接通路
控制器
控制程序的执行
- 产生指令执行过程所需要的所有控制信号,控制相关功能部件执行相应操作
- 控制信号的形式
- 电平信号
- 脉冲信号
- 产生控制信号的依据
- 指令
- 状态
- 时序
- 控制信号的产生方式
- 微程序
存储器
记住程序和数据
- 功能
- 存储原程序、原数据、运算中间结果
- 工作方式
- 读/写
- 工作原理
- 按地址访问,读/写数据
输入设备
把程序和数据加载到计算机
- 输入设备
- 向计算机输入数据(键盘、鼠标、网卡、扫描仪等)
输出设备
按照要求将处理的数据结果显示给用户
- 输出设备
- 输出处理结果(显示器、声卡、网卡、打印机等)
举个栗子:
你在qq 上发送了一句 “ 在吗 ” 给朋友,数据的流动过程 :
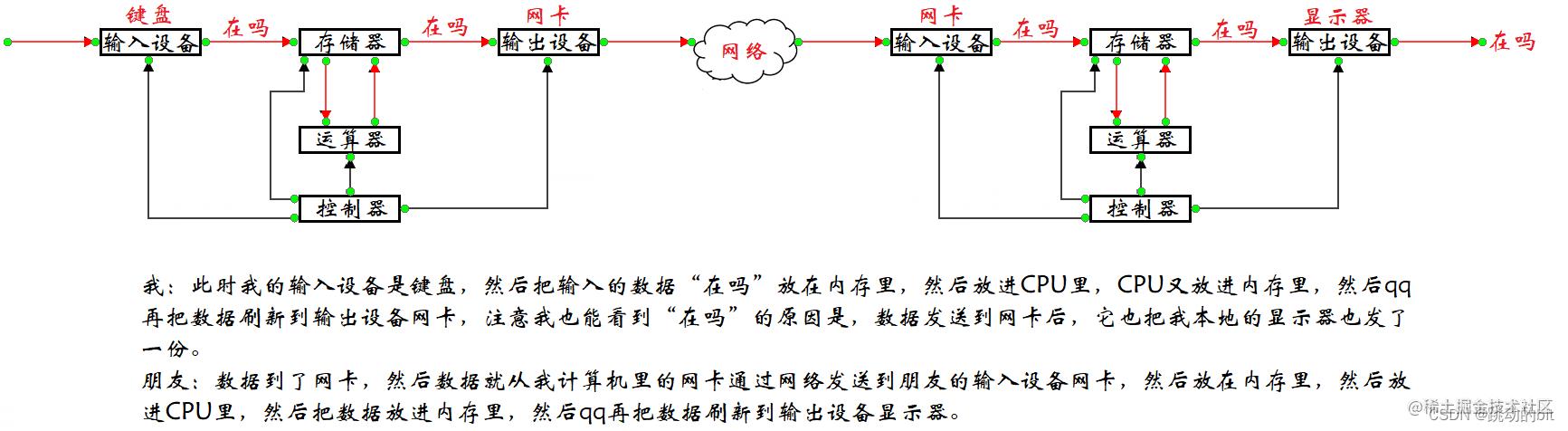
你在qq上发了一个文件给朋友:

计算机的性能与功耗
计算机的性能,其实和我们干体力劳动很像,好比是我们要搬东西。对于计算机的性能,我们需要有个标准来衡量。这个标准中主要有两个指标。
响应时间
响应时间(Response time)或者叫执行时间(Execution time)。想要提升响应时间这个性能指标,你可以理解为让计算机“跑得更快”。
吞吐率
吞吐率(Throughput)或者带宽(Bandwidth),想要提升这个指标,你可以理解为让计算机“搬得更多”。
CPU时钟/主频
计算机可能同时运行着好多个程序,CPU 实际上不停地在各个程序之间进行切换。在这些走掉的时间里面,很可能 CPU 切换去运行别的程序了。而且,有些程序在运行的时候,可能要从网络、硬盘去读取数据,要等网络和硬盘把数据读出来,给到内存和 CPU。
所以说,要想准确统计某个程序运行时间,进而去比较两个程序的实际性能,我们得把这些时间给刨除掉。那这件事怎么实现呢?Linux 下有一个叫 time 的命令,可以帮我们统计出来,同样的 WallClock Time 下,程序实际在 CPU 上到底花了多少时间。

程序实际花费的 CPU 执行时间(CPUTime),就是 user time 加上 sys time。
除了 CPU 之外,时间这个性能指标还会受到主板、内存这些其他相关硬件的影响。所以,我们需要对“时间”这个我们可以感知的指标进行拆解,把程序的 CPU 执行时间变成 CPU时钟周期数(CPU Cycles)和 时钟周期时间(Clock Cycle)的乘积。
程序的 CPU 执行时间 =CPU 时钟周期数×时钟周期时间
我们先来理解一下什么是时钟周期时间。你在买电脑的时候,一定关注过 CPU 的主频。例如Intel Core-i7-7700HQ 2.8GHz,这里的 2.8GHz 就是电脑的主频(Frequency/Clock Rate)。这个 2.8GHz,我们可以先粗浅地认为,CPU 在 1 秒时间内,可以执行的简单指令的数量是 2.8G 条。
2.8GHz详解:
这个 2.8GHz 就代表,我们 CPU 的一个“钟表”能够识别出来的最小的时间间隔。就像我们挂在墙上的挂钟,都是“滴答滴答”一秒一秒地走,所以通过墙上的挂钟能够识别出来的最小时间单位就是秒。
而在 CPU 内部,和我们平时戴的电子石英表类似,有一个叫晶体振荡器(OscillatorCrystal)的东西,简称为晶振。我们把晶振当成 CPU 内部的电子表来使用。晶振带来的每一次“滴答”,就是时钟周期时间。在我这个 2.8GHz 的 CPU 上,这个时钟周期时间,就是 1/2.8G。
我们的 CPU,是按照这个“时钟”提示的时间来进行自己的操作。主频越高,意味着这个表走得越快,我们的CPU 也就“被逼”着走得越快。如果你自己组装过台式机的话,可能听说过“**超频”**这个概念,这说的其实就相当于把买回来的 CPU 内部的钟给调快了,于是 CPU 的计算跟着这个时钟的节奏,也就自然变快了。当然这个快不是没有代价的,CPU 跑得越快,散热的压力也就越大。就和人一样,超过生理极限,CPU 就会崩溃了。
对于软件工程师来说,如何提升性能呢?
- 换CPU
- 减少程序需要的CPU时钟周期数量
对于 CPU 时钟周期数,我们可以再做一个分解,把它变成“指令数×每条指令的平均时钟周期数(Cycles Per Instruction,简称 CPI)
程序的 CPU 执行时间 = (指令数×CPI)× 时钟周期时间
我们可以把自己想象成一个 CPU,坐在那里写程序。
- 计算机主频就好像是你的打字速度,打字越快,你自然可以多写一点程序。
- CPI 相当于你在写程序的时候,熟悉各种快捷键,越是打同样的内容,需要敲击键盘的次数就越少。
- 指令数相当于你的程序设计得够合理,同样的程序要写的代码行数就少。
如果三者皆能实现,你自然可以很快地写出一个优秀的程序,你的“性能”从外面来看就是好的。
计算机的功耗
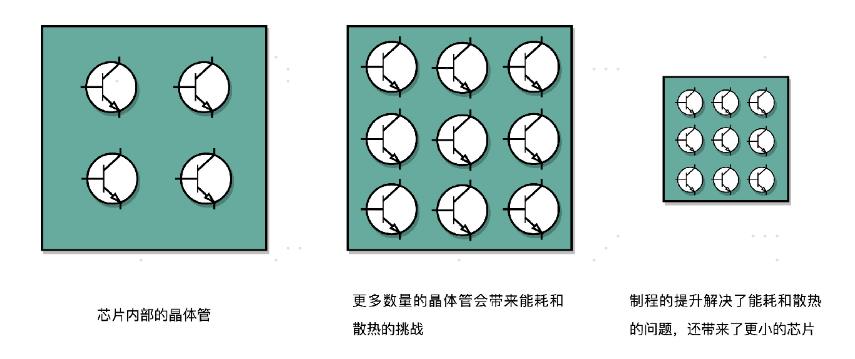
我们的 CPU,一般都被叫作超大规模集成电路(Very-Large-Scale Integration,VLSI)。这些电路,实际上都是一个个晶体管组合而成的。CPU 在计算,其实就是让晶体管里面的“开关”不断地去“打开”和“关闭”,来组合完成各种运算和功能。
想要计算得快,一方面,我们要在 CPU 里,同样的面积里面,多放一些晶体管,也就是增加密度;另一方面,我们要让晶体管“打开”和“关闭”得更快一点,也就是提升主频。而这两者,都会增加功耗,带来耗电和散热的问题。
我们会在 CPU 上面抹硅脂、装风扇,乃至用上水冷或者其他更好的散热设备,就好像在工厂里面装风扇、空调,发冷饮一样。但是同样的空间下,装上风扇空调能够带来的散热效果也是有极限的。
功耗 ~= 1/2 ×负载电容×电压的平方×开关频率×晶体管数量
那么,为了要提升性能,我们需要不断地增加晶体管数量。同样的面积下,我们想要多放一点晶体管,就要把晶体管造得小一点。这个就是平时我们所说的提升**“制程”**。从 28nm到 7nm,相当于晶体管本身变成了原来的 1/4 大小。这个就相当于我们在工厂里,同样的活儿,我们要找瘦小一点的工人,这样一个工厂里面就可以多一些人。我们还要提升主频,让开关的频率变快,也就是要找手脚更快的工人。
我们可以看到,无论是简单地通过提升主频,还是增加更多的 CPU 核心数量,通过并行来提升性能,都会遇到相应的瓶颈。仅仅简单地通过“堆硬件”的方式,在今天已经不能很好地满足我们对于程序性能的期望了。
在整个计算机组成层面,还有这样几个原则性的性能提升方法:
- 加速大概率事件,例如GPU来处理向量和矩阵计算。
- 通过流水线提高性能
- 通过预测提高性能
计算机的指令和运算
计算机中的基本单位:计算机存储单位一般用 bit, Byte, KB, MB, GB, TB, PB, EB, ZB, BB来表示;
1、计算机存储信息的最小单位:
- 位 bit (比特)(Binary Digits):存放一位二进制数,即 0 或 1,最小的存储单位。
2、计算机存储容量基本单位是字节
- 字节 byte:8个二进制位(bit)为一个字节(B),最常用的单位。
1B(Byte 字节)=8bit,
1KB (Kilobyte 千字节)=1024B,
1MB (Megabyte 兆字节 简称“兆”)=1024KB,
1GB (Gigabyte 吉字节 又称“千兆”)=1024MB,
1TB (Trillionbyte 万亿字节 太字节)=1024GB,其中1024=2^10 ( 2 的10次方),
1PB(Petabyte 千万亿字节 拍字节)=1024TB,
1EB(Exabyte 百亿亿字节 艾字节)=1024PB,
1ZB (Zettabyte 十万亿亿字节 泽字节)= 1024 EB,
1YB (Yottabyte 一亿亿亿字节 尧字节)= 1024 ZB,
1BB (Brontobyte 一千亿亿亿字节)= 1024 YB.
计算机指令(机器码)
计算机指令和指令集
在编程的最初期,工程师们使用打孔卡来写程序,因为计算机或者说 CPU 本身,并没有能力理解这些高级语言。即使在 2019 年的今天,我们使用的现代个人计算机,仍然只能处理所谓的“机器码”,也就是一连串的“0”和“1”这样的数字。那么,我们每天用高级语言的程序,最终是怎么变成一串串“0”和“1”的?这一串串“0”和“1”又是怎么在 CPU 中处理的?

在软硬接口中,CPU帮我们做了什么事?
- 从硬件的角度来看,CPU 就是一个超大规模集成电路,通过电路实现了加法、乘法乃至各种各样的处理逻辑。
- 如果我们从软件工程师的角度来讲,CPU 就是一个执行各种计算机指令(InstructionCode)的逻辑机器。这里的计算机指令,就好比一门 CPU 能够听得懂的语言,我们也可以把它叫作机器语言(Machine Language)。
不同的 CPU 能够听懂的语言不太一样。比如,我们的个人电脑用的是 Intel 的 CPU,苹果手机用的是 ARM 的 CPU。这两者能听懂的语言就不太一样。类似这样两种 CPU 各自支持的语言,就是两组不同的计算机指令集,英文叫 Instruction Set。这里面的“Set”,其实就是数学上的集合,代表不同的单词、语法。
所以,如果我们在自己电脑上写一个程序,然后把这个程序复制一下,装到自己的手机上,肯定是没办法正常运行的,因为这两者语言不通。而一台电脑上的程序,简单复制一下到另外一台电脑上,通常就能正常运行,因为这两台 CPU 有着相同的指令集,也就是说,它们的语言相通的。
一个计算机程序,不可能只有一条指令,而是由成千上万条指令组成的。但是 CPU 里不能一直放着所有指令,所以计算机程序平时是存储在存储器中的。这种程序指令存储在存储器里面的计算机,我们就叫作存储程序型计算机(Stored-program Computer)。
机器码
编译->汇编,代码如何变成机器码?
了解了计算机指令和计算机指令集,接下来我们来看看,平时编写的代码,到底是怎么变成一条条计算机指令,最后被 CPU 执行的呢?
int main()
int a = 1;
int b = 2;
a = a + b;
要让这段C语言程序在一个 Linux 操作系统上跑起来,我们需要把整个程序翻译成一个汇编语言(ASM,Assembly Language)的程序,这个过程我们一般叫编译(Compile)成汇编代码。
针对汇编代码,我们可以再用汇编器(Assembler)翻译成机器码(Machine Code)。这些机器码由“0”和“1”组成的机器语言表示。这一条条机器码,就是一条条的计算机指令。这样一串串的 16 进制数字,就是我们 CPU 能够真正认识的计算机指令。
在一个 Linux 操作系统上,我们可以简单地使用 gcc 和 objdump 这样两条命令,把对应的汇编代码和机器码都打印出来。
[root@iZ2ze9ql6wc4u0l1j4f6uiZ ~]# gcc -g -c test.c
[root@iZ2ze9ql6wc4u0l1j4f6uiZ ~]# ls
get-docker.sh install.sh jstack.log test.c test.o
[root@iZ2ze9ql6wc4u0l1j4f6uiZ ~]# objdump -d -M intel -S test.o
test.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
#include<stdio.h>
int main()
0: 55 push rbp
1: 48 89 e5 mov rbp,rsp
int a = 1;
4: c7 45 fc 01 00 00 00 mov DWORD PTR [rbp-0x4],0x1
int b = 2;
b: c7 45 f8 02 00 00 00 mov DWORD PTR [rbp-0x8],0x2
a = a + b;
12: 8b 45 f8 mov eax,DWORD PTR [rbp-0x8]
15: 01 45 fc add DWORD PTR [rbp-0x4],eax
return 0;
18: b8 00 00 00 00 mov eax,0x0
1d: 5d pop rbp
1e: c3 ret
[root@iZ2ze9ql6wc4u0l1j4f6uiZ ~]#
可以看到,左侧有一堆数字,这些就是一条条机器码;右边有一系列的 push、mov、add、pop 等,这些就是对应的汇编代码。一行 C 语言代码,有时候只对应一条机器码和汇编代码,有时候则是对应两条机器码和汇编代码。
这个时候你可能又要问了,我们实际在用 GCC(GUC 编译器套装,GUI CompilerCollectipon)编译器的时候,可以直接把代码编译成机器码呀,为什么还需要汇编代码呢?原因很简单,你看着那一串数字表示的机器码,是不是摸不着头脑?但是即使你没有学过汇编代码,看的时候多少也能“猜”出一些这些代码的含义。
汇编代码其实就是“给程序员看的机器码”

汇编器是怎么吧对应的汇编代码,翻译成为机器码的?——MIPS指令集
CPU是如何执行指令的?
拿我们用的 Intel CPU 来说,里面差不多有几百亿个晶体管。实际上,一条条计算机指令执行起来非常复杂。好在 CPU 在软件层面已经为我们做好了封装。对于我们这些做软件的程序员来说,我们只要知道,写好的代码变成了指令之后,是一条一条顺序执行的就可以了。
逻辑上,我们可以认为,CPU 其实就是由一堆寄存器组成的。而寄存器就是 CPU 内部,由多个触发器(Flip-Flop)或者锁存器(Latches)组成的简单电路。
N 个触发器或者锁存器,就可以组成一个 N 位(Bit)的寄存器,能够保存 N 位的数据。比方说,我们用的 64 位 Intel 服务器,寄存器就是 64 位的。
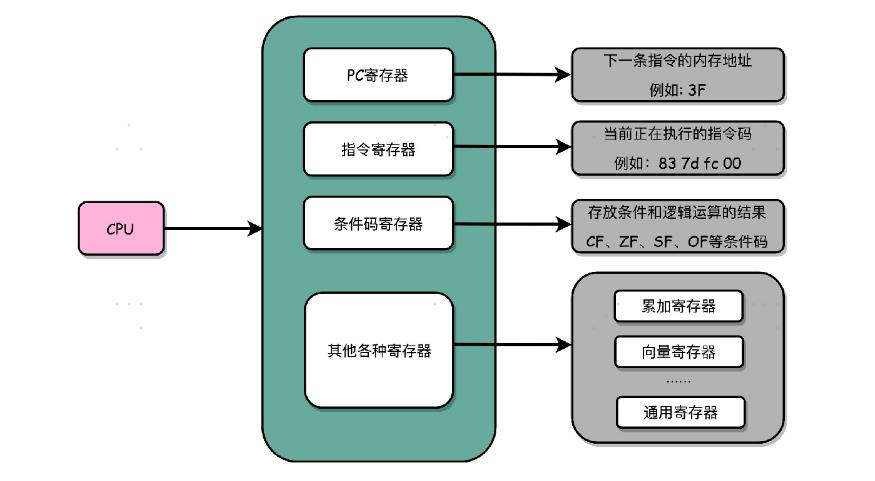
除了这些特殊的寄存器,CPU 里面还有更多用来存储数据和内存地址的寄存器。这样的寄存器通常一类里面不止一个。我们通常根据存放的数据内容来给它们取名字,比如整数寄存器、浮点数寄存器、向量寄存器和地址寄存器等等。有些寄存器既可以存放数据,又能存放地址,我们就叫它通用寄存器。
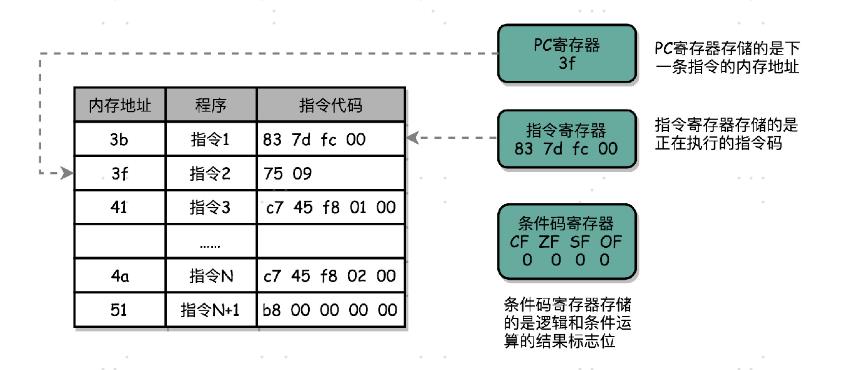
实际上,一个程序执行的时候,CPU 会根据 PC 寄存器里的地址,从内存里面把需要执行的指令读取到指令寄存器里面执行,然后根据指令长度自增,开始顺序读取下一条指令。可以看到,一个程序的一条条指令,在内存里面是连续保存的,也会一条条顺序加载。
程序栈
我们在内存里面开辟一段空间,用栈这个后进先出(LIFO,Last In First Out)的数据结构。作为程序栈,我们可以方便地通过压栈和出栈操作,使得程序在不同的函数调用过程中进行转移。
结合之前的机器码和汇编码来看:
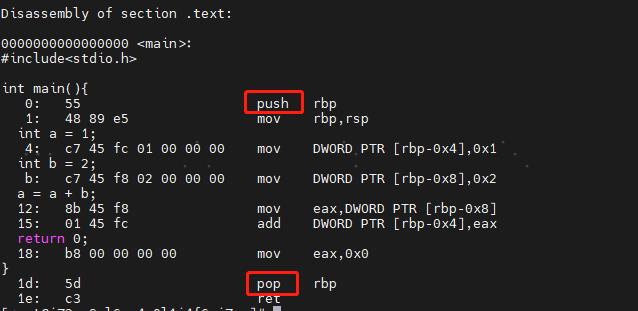
Push 即为入栈, pop即为出栈。
程序执行
静态链接和ELF格式
为什么同样一个程序,在 Linux 下可以执行而在 Windows下不能执行了。其中一个非常重要的原因就是,两个操作系统下可执行文件的格式不一样。
- Linux 下的 ELF 文件格式
- 而Windows 的可执行文件格式是一种叫作PE(Portable Executable Format)的文件格式。
- Linux 下的装载器只能解析 ELF 格式而不能解析 PE 格式。
Linux 下著名的开源项目 Wine,就是通过兼容PE 格式的装载器,使得我们能直接在 Linux 下运行 Windows 程序的。而现在微软的
Windows 里面也提供了 WSL,也就是 Windows Subsystem for Linux,可以解析和加载ELF 格式的文件。
我们去写可以用的程序,也不仅仅是把所有代码放在一个文件里来编译执行,而是可以拆分成不同的函数库,最后通过一个静态链接的机制,使得不同的文件之间既有分工,又能通过静态链接来“合作”(通过链接器,把多个文件合并成一个最终可执行文件),变成一个可执行的程序。
程序的装载(内存的优化)
我们看到了如何通过链接器,把多个文件合并成一个最终可执行文件。在运行这些可执行文件的时候,我们其实是通过一个装载器,解析 ELF 或者 PE 格式的可执行文件。装载器会把对应的指令和数据加载到内存里面来,让 CPU 去执行。
装载器需要满足两个要求:
- 可执行程序加载后占用的内存空间应该是连续的。
- 我们需要同时加载很多个程序,并且不能让程序自己规定正在内存中加载的位置。
我们可以在内存里面,找到一段连续的内存空间,然后分配给装载的程序,然后把这段连续的内存空间地址,和整个程序指令里指定的内存地址做一个映射。–(分段)
- 我们把指令里用到的内存地址叫作虚拟内存地址(Virtual Memory Address)
- 实际在内存硬件里面的空间地址,我们叫物理内存地址(Physical Memory Address)。
我们只需要关心虚拟内存地址就行了,对于任何一个程序来说,它看到的都是同样的内存地址。我们维护一个虚拟内存到物理内存的映射表,这样实际程序指令执行的时候,会通过虚拟内存地址,找到对应的物理内存地址,然后执行。因为是连续的内存地址空间,所以我们只需要维护映射关系的起始地址和对应的空间大小就可以了。
内存分段:
这种找出一段连续的物理内存和虚拟内存地址进行映射的方法,我们叫分段(Segmentation)。这里的段,就是指系统分配出来的那个连续的内存空间。
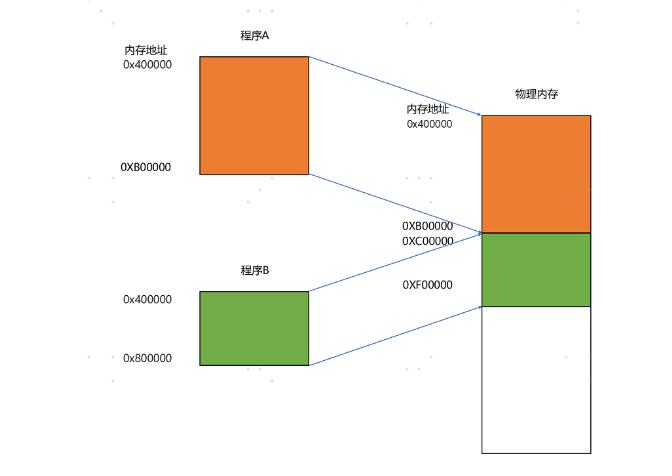
分段的办法很好,解决了程序本身不需要关心具体的物理内存地址的问题,但它也有一些不足之处,第一个就是内存碎片(Memory Fragmentation)的问题。
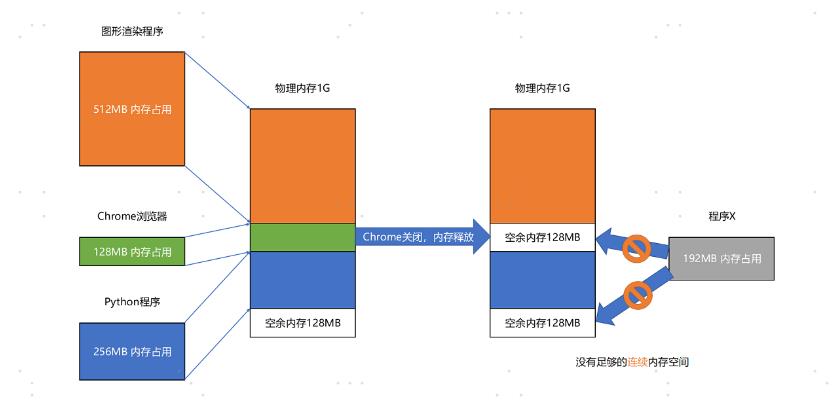
内存交换就是解决内存分段的问题。
我们可以把 Python 程序占用的那 256MB 内存写到硬盘上,然后再从硬盘上读回来到内存里面。不过读回来的时候,我们不再把它加载到原来的位置,而是紧紧跟在那已经被占用了的 512MB 内存后面。这样,我们就有了连续的 256MB 内存空间,就可以去加载一个新的 200MB 的程序。
如果你自己安装过 Linux 操作系统,你应该遇到过分配一个 swap 硬盘分区的问题。这块分出来的磁盘空间,其实就是专门给 Linux 操作系统进行内存交换用的。
内存分页
虚拟内存、分段,再加上内存交换,看起来似乎已经解决了计算机同时装载运行很多个程序的问题。不过,你千万不要大意,这三者的组合仍然会遇到一个性能瓶颈。硬盘的访问速度要比内存慢很多,而每一次内存交换,我们都需要把一大段连续的内存数据写到硬盘上。所以,如果内存交换的时候,交换的是一个很占内存空间的程序,这样整个机器都会显得卡顿。
既然问题出在内存碎片和内存交换的空间太大上,那么解决问题的办法就是,少出现一些内存碎片。另外,当需要进行内存交换的时候,让需要交换写入或者从磁盘装载的数据更少一点,这样就可以解决这个问题。这个办法,在现在计算机的内存管理里面,就叫作内存分页(Paging)。
和分段这样分配一整段连续的空间给到程序相比,分页是把整个物理内存空间切成一段段固定尺寸的大小。而对应的程序所需要占用的虚拟内存空间,也会同样切成一段段固定尺寸的大小。这样一个连续并且尺寸固定的内存空间,我们叫页(Page)。从虚拟内存到物理内存的映射,不再是拿整段连续的内存的物理地址,而是按照一个一个页来的。页的尺寸一般远远小于整个程序的大小。在 Linux 下,我们通常只设置成 4KB。

由于内存空间都是预先划分好的,也就没有了不能使用的碎片,而只有被释放出来的很多 4KB 的页。即使内存空间不够,需要让现有的、正在运行的其他程序,通过内存交换释放出一些内存的页出来,一次性写入磁盘的也只有少数的一个页或者几个页,不会花太多时间,让整个机器被内存交换的过程给卡住。
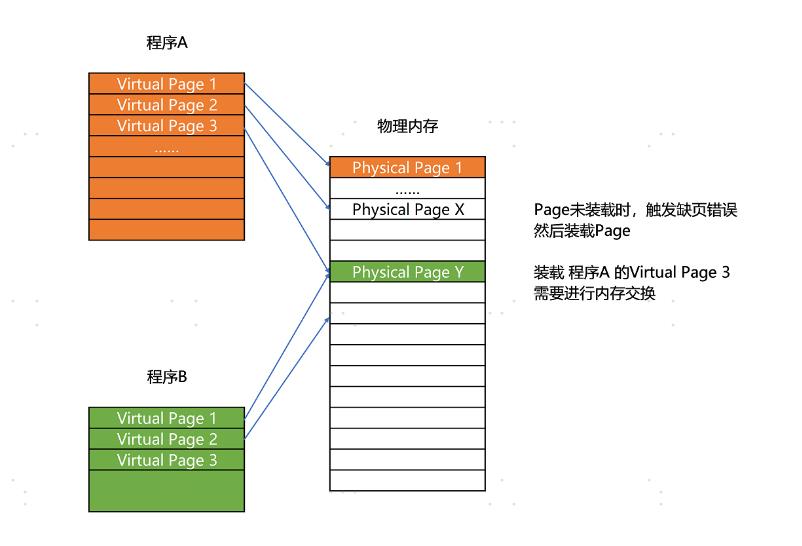
更进一步地,分页的方式使得我们在加载程序的时候,不再需要一次性都把程序加载到物理内存中。我们完全可以在进行虚拟内存和物理内存的页之间的映射之后,并不真的把页加载到物理内存里,而是只在程序运行中,需要用到对应虚拟内存页里面的指令和数据时,再加载到物理内存里面去。
实际上,我们的操作系统,的确是这么做的。当要读取特定的页,却发现数据并没有加载到物理内存里的时候,就会触发一个来自于 CPU 的缺页错误(Page Fault)。我们的操作系统会捕捉到这个错误,然后将对应的页,从存放在硬盘上的虚拟内存里读取出来,加载到物理内存里。这种方式,使得我们可以运行那些远大于我们实际物理内存的程序。同时,这样一来,任何程序都不需要一次性加载完所有指令和数据,只需要加载当前需要用到就行了。
总结:任何一个程序,都只需要把内存当成是一块完整而连续的空间来直接使用。
动态链接
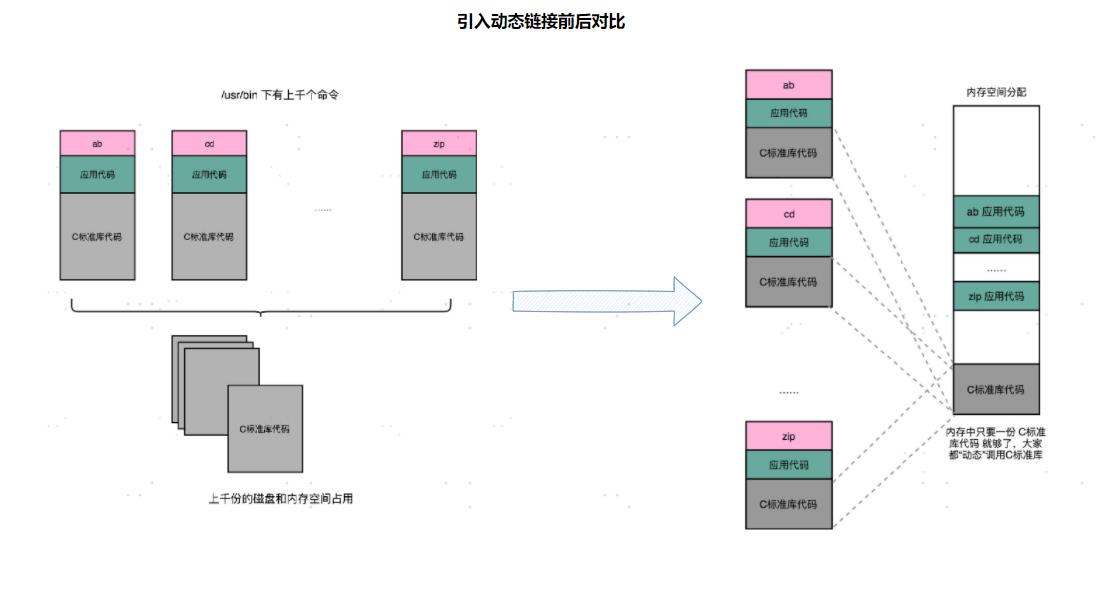
我们之前讲过,程序的链接,是把对应的不同文件内的代码段,合并到一起,成为最后的可执行文件。这个链接的方式,让我们在写代码的时候做到了“复用”。同样的功能代码只要写一次,然后提供给很多不同的程序进行链接就行了。这么说来,“链接”其实有点儿像我们日常生活中的标准化、模块化生产。我们有一个可以生产标准螺帽的生产线,就可以生产很多个不同的螺帽。只要需要螺帽,我们都可以通过链接的方式,去复制一个出来,放到需要的地方去,大到汽车,小到信箱。
但是,如果我们有很多个程序都要通过装载器装载到内存里面,那里面链接好的同样的功能代码,也都需要再装载一遍,再占一遍内存空间。这就好比,假设每个人都有骑自行车的需要,那我们给每个人都生产一辆自行车带在身边,固然大家都有自行车用了,但是马路上肯定会特别拥挤。 我们上一节解决程序装载到内存的时候,讲了很多方法。说起来,最根本的问题其实就是内存空间不够用。如果我们能够让同样功能的代码,在不同的程序里面,不需要各占一份内存空间,那该有多好啊!这个思路就引入一种新的链接方法,叫作动态链接(Dynamic Link)。
在动态链接的过程中,我们想要“链接”的,不是存储在硬盘上的目标文件代码,而是加载到内存中的共享库(Shared Libraries)。
这个加载到内存中的共享库会被很多个程序的指令调用到。在 Windows 下,这些共享库文件就是.dll 文件,也就是 Dynamic-Link Libary(DLL,动态链接库)。在 Linux 下,这些共享库文件就是.so 文件,也就是 Shared Object(一般我们也称之为动态链接库)。这两大操作系统下的文件名后缀,一个用了“动态链接”的意思,另一个用了“共享”的意思,正好覆盖了两方面的含义。
要想要在程序运行的时候共享代码,也有一定的要求,就是这些机器码必须是“地址无关”的。
大部分函数库其实都可以做到地址无关,因为它们都接受特定的输入,进行确定的操作,然后给出返回结果就好了。无论是实现一个向量加法,还是实现一个打印的函数,这些代码逻辑和输入的数据在内存里面的位置并不重要。
而常见的地址相关的代码,比如绝对地址代码(Absolute Code)、利用重定位表的代码等等,都是地址相关的代码。在程序链接的时候,我们就把函数调用后要跳转访问的地址确定下来了,这意味着,如果这个函数加载到一个不同的内存地址,跳转就会失败。
对于所有动态链接共享库的程序来讲,虽然我们的共享库用的都是同一段物理内存地址,但是在不同的应用程序里,它所在的虚拟内存地址是不同的。 —— PLT 和 GOT,动态链接的解决方案。
实际上,在进行 Linux 下的程序开发的时候,我们一直会用到各种各样的动态链接库。C语言的标准库就在 1MB 以上。我们撰写任何一个程序可能都需要用到这个库,常见的Linux 服务器里,/usr/bin 下面就有上千个可执行文件。如果每一个都把标准库静态链接进来的,几 GB 乃至几十 GB 的磁盘空间一下子就用出去了。如果我们服务端的多进程应用要开上千个进程,几 GB 的内存空间也会一下子就用出去了。这个问题在过去计算机的内存较少的时候更加显著。
通过动态链接这个方式,可以说彻底解决了这个问题。就像共享单车一样,如果仔细经营,是一个很有社会价值的事情,但是如果粗暴地把它变成无限制地复制生产,给每个人造一辆,只会在系统内制造大量无用的垃圾。
计算机运算(二进制)
上算法和数据结构课的时候,老师们都会和你说,程序 = 算法 + 数据结构。如果对应到组成原理或者说硬件层面,算法就是我们前面讲的各种计算机指令,数据结构就对应我们接下来要讲的二进制数据。众所周知,现代计算机都是用 0 和 1 组成的二进制,来表示所有的信息。前面几讲的程序指令用到的机器码,也是使用二进制表示的;我们存储在内存里面的字符串、整数、浮点数也都是用二进制表示的。万事万物在计算机里都是 0 和 1,所以呢,搞清楚各种数据在二进制层面是怎么表示的,是我们必备的一课。
对于基础类型的转换(十进制 —>二进制),以及原码、补码,相信大家都不陌生,所以此处重点讲解字符串编码。
字符串是如何转为二进制的?
最早计算机只需要使用英文字符,加上数字和一些特殊符号,然后用 8 位的二进制,就能表示我们日常需要的所有字符了,这个就是我们常常说的ASCII码(American Standard Code for Information Interchange,美国信息交换标准代码)。
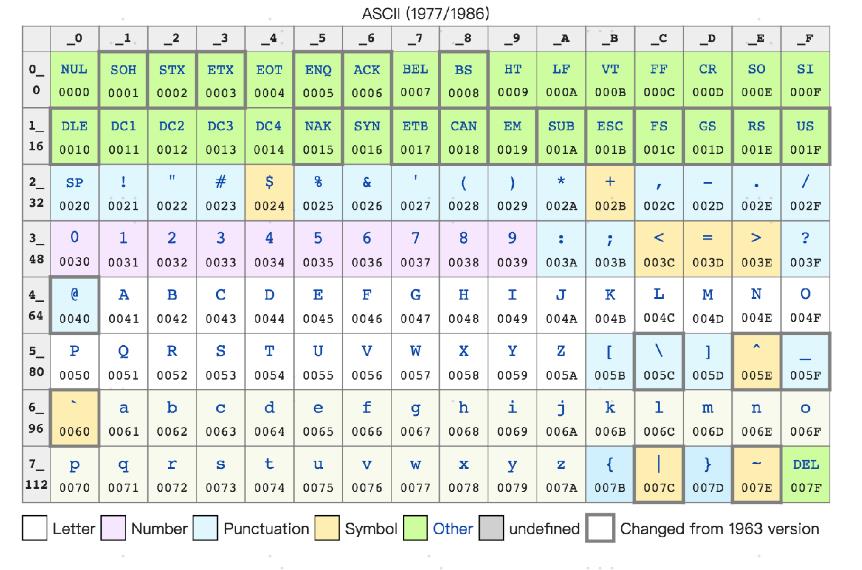
ASCII 码就好比一个字典,用 8 位二进制中的 128 个不同的数,映射到 128 个不同的字符里。比如,小写字母 a 在 ASCII 里面,就是第 97 个,也就是二进制的 0110 0001,对应的十六进制表示就是 61。而大写字母 A,就是第 65 个,也就是二进制的 0100 0001,对应的十六进制表示就是 41。在 ASCII 码里面,数字 9 不再像整数表示法里一样,用 0000 1001 来表示,而是用 00111001 来表示。字符串 15 也不是用 0000 1111 这 8 位来表示,而是变成两个字符 1 和 5连续放在一起,也就是 0011 0001 和 0011 0101,需要用两个 8 位来表示。
我们可以看到,最大的 32 位整数,就是 2147483647。如果用整数表示法,只需要 32 位就能表示了。但是如果用字符串来表示,一共有 10 个字符,每个字符用 8 位的话,需要整整 80 位。比起整数表示法,要多占很多空间。
这也是为什么,很多时候我们在存储数据的时候,要采用二进制序列化这样的方式,而不是简单地把数据通过 CSV 或者 JSON,这样的文本格式存储来进行序列化。不管是整数也好,浮点数也好,采用二进制序列化会比存储文本省下不少空间。
字符集、字符编码
ASCII 码只表示了 128 个字符,一开始倒也堪用,毕竟计算机是在美国发明的。然而随着越来越多的不同国家的人都用上了计算机,想要表示譬如中文这样的文字,128 个字符显然是不太够用的。于是,计算机工程师们开始各显神通,给自己国家的语言创建了对应的字符集(Charset)和字符编码(Character Encoding)。
- **字符集:**表示的可以是字符的一个集合,“第一版《新华字典》里面出现的所有汉字”,这是一个字符集。(一个字符在不在这个集合里面。比如,我们日常说的 Unicode,其实就是一个字符集,包含了 150 种语言的 14 万个不同的字符。)
- **字符编码:**是对于字符集里的这些字符,怎么一一用二进制表示出来的一个字典。Unicode,就可以用 UTF-8、UTF-16,乃至 UTF-32 来进行编码,存储成二进制。
同样的文本,采用不同的编码存储下来。如果另外一个程序,用一种不同的编码方式来进行解码和展示,就会出现乱码。这就好像两个军队用密语通信,如果用错了密码本,那看到的消息就会不知所云。
拓展:“手持两把锟斤拷,口中疾呼烫烫烫。脚踏千朵屯屯屯,笑看万物锘锘锘。”

实现一个 “锟斤拷”
print('�'.encode('utf-8'))
b'\\xef\\xbf\\xbd'
print('锟斤拷'.encode('gbk'))
b'\\xef\\xbf\\xbd\\xef\\xbf\\xbd'
print('�'.encode('utf-8').decode('gbk'))
# UnicodeDecodeError: 'gbk' codec can't decode byte 0xbd in position 2: incomplete multibyte sequence
print('�'.encode('utf-8').decode('gbk', errors='ignore'))
锟
print('�'.encode('utf-8').decode('gbk', errors='replace'))
锟�
print('��'.encode('utf-8').decode('gbk'))
锟斤拷
遇到全是烫烫烫的这种情况,赶紧为CPU降频,CPU太烫了!(狗头)
烫,屯,葺 三个字符的频繁出现是和微软系的编译器有关,
- 静态分配而未初始化的内存空间,默认使用 CC 填充,CCCC 对应 GBK 编码的
烫 - 动态分配而未初始化的内存空间,默认使用 CD 填充,CDCD 对应 GBK 编码的
屯 - 动态分配然后被回收的内存空间,默认使用 DD 填充,DDDD 对应 GBK 编码的
葺
Windows 中文版本的默认编码是 GBK,一输出就显示成了 烫烫烫, 屯屯屯, 葺葺葺。
print((b'\\xcc' * 6).decode('gbk'))
# 烫烫烫
print((b'\\xcd' * 6).decode('gbk'))
# 屯屯屯
print((b'\\xdd' * 6).decode('gbk'))
# 葺葺葺
数字电路
数字电路相关知识 ->数字电路基础 - 简书 (jianshu.com)
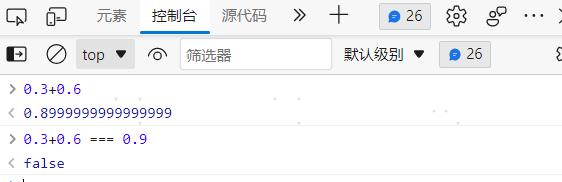
浮点数和定点数(0.3+0.6==0.9为啥为false)
我们现在用的计算机通常用 16/32 个比特(bit)来表示一个数。32 个比特,只能表示 2 的 32 次方个不同的数,差不多是 40 亿个。如果表示的数要超过这个数,就会有两个不同的数的二进制表示是一样的。那计算机可就会一筹莫展,不知道这个数到底是多少。
我到底应该让这 40 亿个数映射到实数集合上的哪些数,在实际应用中才能最划得来呢?
定点数的表示
有一个很直观的想法,就是我们用 4 个比特来表示 0~9 的整数,那么 32 个比特就可以表示 8 个这样的整数。然后我们把最右边的 2 个 0~9 的整数,当成小数部分;把左边 6 个0~9 的整数,当成整数部分。这样,我们就可以用 32 个比特,来表示从 0 到 999999.99这样 1 亿个实数了。
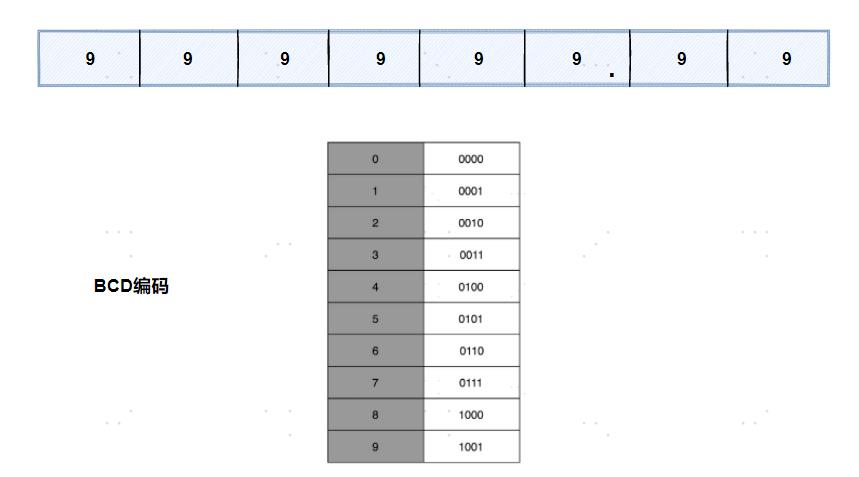
它的运用非常广泛,最常用的是在超市、银行这样需要用小数记录金额的情况里。在超市里面,我们的小数最多也就到分。这样的表示方式,比较直观清楚,也满足了小数部分的计算。
不过,这样的表示方式也有几个缺点:
- 浪费,本来 32 个比特我们可以表示 40 亿个不同的数,但是在 BCD 编码下,只能表示 1 亿个数,如果我们要精确到分的话,那么能够表示的最大金额也就是到 100 万。
- **这样的表示方式没办法同时表示很大的数字和很小的数字。**我们在写程序的时候,实数的用途可能是多种多样的。有时候我们想要表示商品的金额,关心的是 9.99 这样小的数字;有时候,我们又要进行物理学的运算,需要表示光速,也就是 这样很大的数字。3 × 10^8
浮点数的表示
一个现实问题:有限宽度的便签,只能写下有限大小的数字。
这里的纸张宽度,就和我们 32 个比特一样,是在空间层面的限制。那么,在现实生活中,我们是怎么表示一个很大的数的呢?比如说,我们想要在一本科普书里,写一下宇宙内原子的数量,莫非是用一页纸,用好多行写下很多个 0 么?
到这里你肯定能想到,科学计数法。
在计算机里,我们也可以用一样的办法,用科学计数法来表示实数。浮点数的科学计数法的表示,有一个IEEE的标准,它定义了两个基本的格式。
- 用 32 比特表示单精度的浮点数,也就是我们常常说的
float或者float32类型。 - 另外一个是用 64 比特表示双精度的浮点数,也就是我们平时说的
double或者float64类型。
单精度:
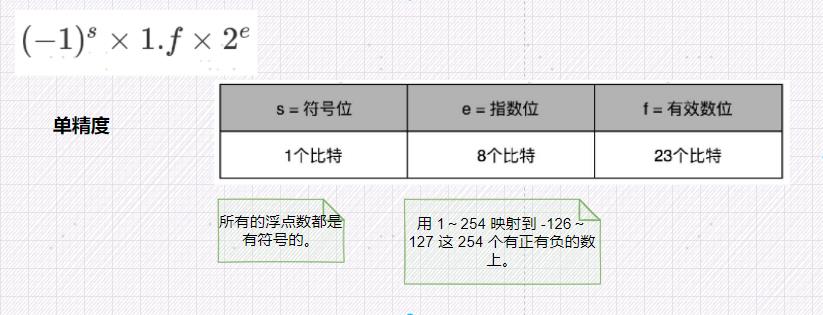
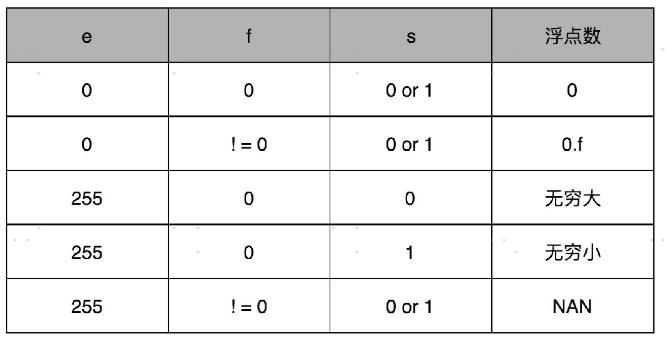
你会发现,这里的浮点数,没有办法表示 0。的确,要表示 0 和一些特殊的数,我们就要用上在 e 里面留下的 0 和 255 这两个表示,这两个表示其实是两个标记位。在 e 为 0 且 f为 0 的时候,我们就把这个浮点数认为是 0。至于其它的 e 是 0 或者 255 的特殊情况,你可以看下面这个表格,分别可以表示出无穷大、无穷小、NAN 以及一个特殊的不规范数。
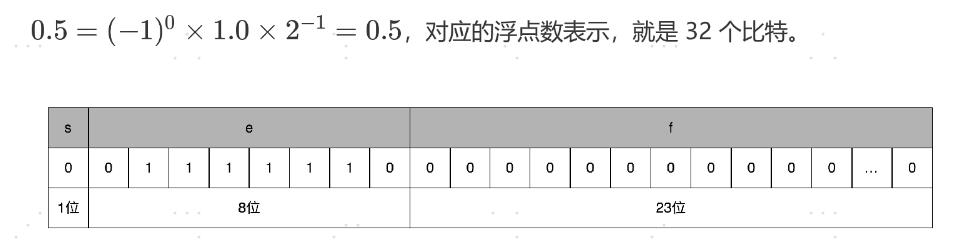
举个栗子:0.5该如何表示呢?
精度问题:为什么我们用 0.3 + 0.6 不能得到 0.9 呢?
浮点数没有办法精确表示 0.3、0.6 和 0.9。事实上,我们拿出 0.1~0.9 这 9 个数,其中只有 0.5 能够被精确地表示成二进制的浮点数,也就是 s = 0、e = -1、f = 0 这样的情况。而 0.3、0.6 乃至我们希望的 0.9,都只是一个近似的表达。
那么,在使用过程中,我们该怎么来使用浮点数,以及使用浮点数会遇到些什么问题呢?
深入理解浮点数到底怎么用
浮点数可以大到
3.40 × 10^38,也可以小到1.17 × 10^38这样的数值。同时,我们也发现,其实我们平时写的 0.1、0.2 并不是精确的数值,只是一个近似值。只有 0.5 这样,可以表示成2^1这种形式的,才是一个精确的浮点数。
我们在实际应用中,该怎么用好浮点数呢?
搞清楚了怎么把一个十进制的数值,转化成 IEEE-754 标准下的浮点数表示,我们现在来看一看浮点数的加法是怎么进行的。其实原理也很简单,你记住六个字就行了,那就是先对齐、再计算。
两个浮点数的指数位可能是不一样的,所以我们要把两个的指数位,变成一样的,然后只去计算有效位的加法就好了。
其中指数位较小的数,需要在有效位进行右移,在右移的过程中,最右侧的有效位就被丢弃掉了。这会导致对应的指数位较小的数,在加法发生之前,就丢失精度。
举个例子,两个差距非常大的浮点数相加,小的精度就会被完全抛弃:(加到 1600 万之后的加法因为精度丢失都没有了)
public class