多标签文本分类《融合注意力与CorNet的多标签文本分类》
Posted 征途黯然.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多标签文本分类《融合注意力与CorNet的多标签文本分类》相关的知识,希望对你有一定的参考价值。
·阅读摘要:
本文主要提出标签与文本注意力+文本注意力、CorNet增强标签预测概率两个创新点,提升了实验精度。
·参考文献:
[1] 融合注意力与CorNet的多标签文本分类
参考论文信息
论文名称:《融合注意力与CorNet的多标签文本分类》
发布期刊:《西北大学学报(自然科学版)》
期刊信息:CSCD扩展

[0] 摘要
目前文本分类存在问题:只关注文本本身的信息,忽略了标签的信息。
为了解决这个问题:论文提出使用图注意力网络GAT来编码标签信息,然后使用 “文本-标签”注意力机制来强化标签与文本的语义联系,最后把它与文本的注意力向量融合,得到最终编入了标签信息的文本向量。
论文最后使用CorNet模型增强标签预测概率。
[1] 相关工作
论文介绍多标签文本分类算法的历史:机器学习算法和深度学习算法。
机器学习算法有BR、CC、ML-DT、SVM、KNN等老算法;
深度学习算法有CNN系列、RNN系列模型,比如CNN、LSTM、LSTM_Attention、Seq2Seq、SGM、CNN-RNN等。
【注一】:这里已经被各个论文介绍烂了,老生常谈。
最后,还介绍了LSAN、GCN等会用到标签信息的模型。
【注二】:2022年的论文,竟然不介绍预训练语言模型,比如ELMo、BERT、XLNet这些。
[2] 模型
模型图如下:

该模型主要分为6个部分:
1、嵌入层+LSTM层
2、多标签注意力层
3、图注意力网络
4、“文本 -标签”注意力机制
5、自适应融合机制
6、CorNet模块
1、嵌入层+LSTM层
论文使用的是Glove预训练词向量作为embedding层,然后输入到Bi-LSTM层得到文本表示。
【注三】:使用embedding+Bi-LSTM是比较早的深度学习方法,现在更多的是用预训练语言模型来微调。
2、多标签注意力层
论文原文写的是:多标签文本可以由多个标签标记,每个标签对应的最相关文本是不同的。通过多标签注意力机制计算每个标签对应的文本向量hi的线性组合,可以有效地表示文本的重要程度。
论文给的小标题“多标签注意力层”比较让人困惑,似乎这里用了标签的信息?看原文的意思是用了,但是看他贴的公式并没有用,而且我也想象不到怎么使用标签信息。
【注四】:这里我去论文贴出来的参考论文《A structured self-attentive sentence embedding》看了一下,人家写的是文本数据自注意,如下图:
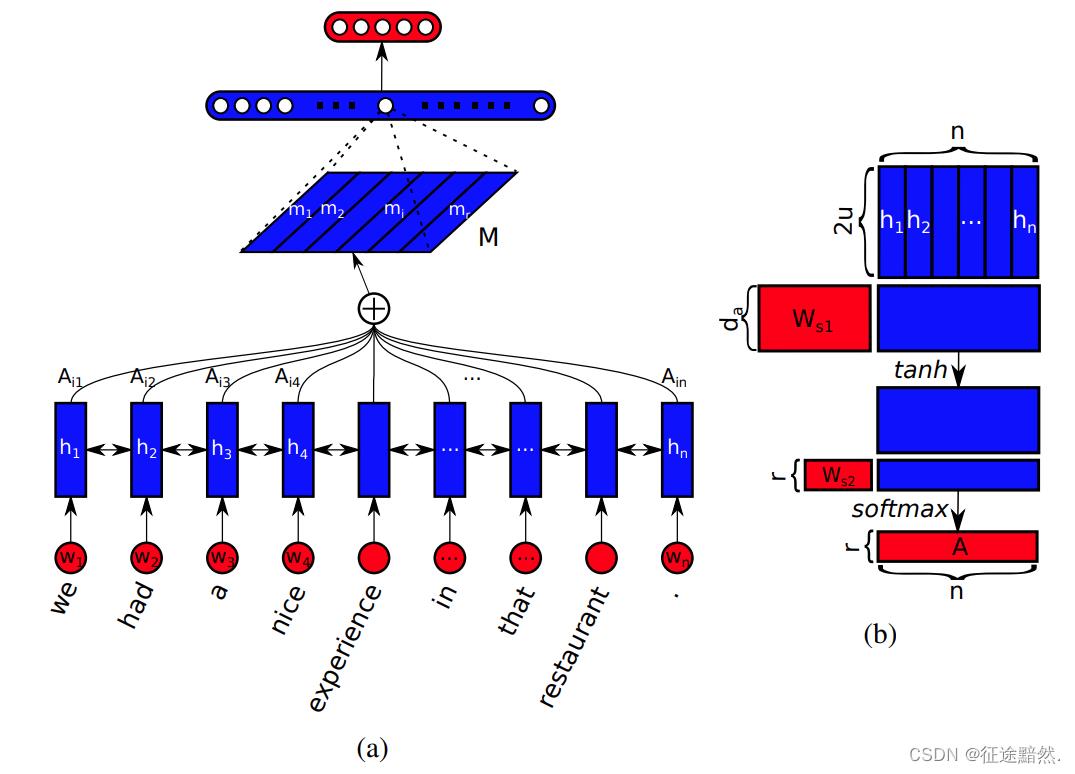
3、图注意力网络
图注意力网络GAT是比较火的一种图神经网络,不再介绍。
它的输入是标签嵌入,输出是经过注意力机制后的标签向量。
【注五】:GAT原文 《GRAPH ATTENTION NETWORKS》值得一看
4、“文本 -标签”注意力机制
强化标签之间的语义联系,将标签语义信息与文本上下文语义信息进行交互,获得基于标签语义的文本特征表示。
论文的做法是,把 嵌入层+LSTM层 的输出与 图注意力网络 的输出相乘。
5、自适应融合机制
自适应融合机制是把 多标签注意力层 的输出与 **“文本 -标签”注意力机制 ** 的输出加权相乘,得到最终的文本表示。

公式13有点疑惑,
β
\\beta
β与
γ
\\gamma
γ不应该是公式12的输出嘛?怎么会相加等于1?用Softmax处理一下可以做好,但是论文没有提。
6、CorNet模块
CorNet模块能够学习标签相关性,使用相关性知识增强原始标签预测,并输出增强的标签预测。
【注六】:CorNet模型原文:《Correlation Networks for Extreme Multi-label Text Classification》
以上是关于多标签文本分类《融合注意力与CorNet的多标签文本分类》的主要内容,如果未能解决你的问题,请参考以下文章