读点论文Focal Self-attention for Local-Global Interactions in Vision Transformers局部和全局注意力进行交互实现新SOTA
Posted 羞儿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了读点论文Focal Self-attention for Local-Global Interactions in Vision Transformers局部和全局注意力进行交互实现新SOTA相关的知识,希望对你有一定的参考价值。
Focal Self-attention for Local-Global Interactions in Vision Transformers
Abstract
-
本文提出了一种焦点自注意力机制 Focal-Self-Attention(FSA),然后基于焦点自注意力机制,提出了一种 Focal Transformer。
-
最近,Vision Transformer及其变体在各种计算机视觉任务上表现出了巨大的潜力。通过自我关注捕捉短期和长期视觉依赖的能力是成功的关键。但由于二次方计算复杂度开销,特别是对于高分辨率视觉任务(例如,物体检测),它也带来了挑战。
-
最近的许多工作都试图通过应用粗粒度全局关注或细粒度局部关注来降低计算和内存成本并提高性能。然而,这两种方法都削弱了多层变压器原始自我关注机制的建模能力,从而导致次优解决方案。
-
在本文中,本文提出了焦点自我关注,这是一种结合了细粒度局部和粗粒度全局交互的新机制。在这一新机制中,每个令牌以细粒度关注其最近的周围令牌,而以粗粒度关注远处的令牌,因此可以高效和有效地捕获短期和长期视觉依赖。
-
通过焦点自我关注,本文提出了一种新的视觉transformer模型变体,称为Focal Transformer,它在一系列公共图像分类和对象检测基准上实现了优于最先进(SoTA)视觉变换器的性能。
-
特别是,本文的Focal Transformer模型的中等尺寸为51.1M,较大尺寸为89.8M,在ImageNet分类为224×224时,分别达到83.5%和83.8%的Top-1精度。当用作主干时,Focal Transformers在6种不同的物体检测方法中实现了与当前SoTA Swin Transformers一致的实质性改进。
-
最大的Focal Transformer在COCO mini val/test dev上产生58.7/58.9盒mAP和50.9/51.3掩模mAP,在ADE20K上产生55.4 mIoU用于语义分割,在三个最具挑战性的计算机视觉任务上创建了新的SoTA。
-
这是 NeurIPS 2021 Spotlight 的文章,提出了一种细粒度和粗粒度全局交互的注意力机制,精度得到了大幅提升。模型整体网络采用 PVT,只是将中间的 Attention 模块替换成了提出的 Focal Attention。
-
因为全局注意力机制需要考虑到所有特征彼此关联,随着图片大小的增长,计算量的增长更为剧烈。因此为了缓解这种计算量增长,先前部分工作考虑粗粒度的全局注意力或重点放在局部注意力上。但实际上,因为注意力模块往往都有多个注意力头以学习不同的特征关系,模型本身就能够获取到不同的粗细粒度信息,如标题图左示意。这种人为强行划分注意力的方法便于这种模型自学习的能力相重复,为了更好利用这些特点,本文提出了粗细粒度全局交互的注意力机制,重点放在局部,但也粗度考虑远处。
-
论文地址:[2107.00641] Focal Self-attention for Local-Global Interactions in Vision Transformers (arxiv.org)
Introduction
-
如今,Transformer已成为自然语言处理(NLP)中的一种流行模型架构。鉴于其在NLP中的成功,在使其适应计算机视觉(CV)方面有越来越多的努力。自从视觉transformer(ViT)首次展示了其前景以来,见证了用于图像分类、对象检测[detr、 Deformable detr、End-to-end object detection with adaptive clustering transformer、Up-detr]和语义分割的全transformer模型的蓬勃发展。除了这些静态图像任务,它还被应用于各种时间理解任务,例如动作识别、对象跟踪、场景流估计。
-
在transformer中,自我关注是关键组成部分,使其与广泛使用的卷积神经网络(CNN)不同。在每个Transformer层,它支持不同图像区域之间的全局内容相关交互,以建模短期和长期依赖关系。通过完全自我关注的可视化,确实观察到它学会了同时关注局部环境(如CNN)和全局环境(见图1左侧)。
-
然而,当涉及到用于密集预测(例如对象检测或分割)的高分辨率图像时,由于与特征图中的网格数量相关的二次计算成本,全局和细粒度的自我关注变得非常重要。最近的工作交替地利用了粗粒度的全局自关注[Pyramid vision transformer,Cvt]或细粒度的局部自关注[Swin transformer,Multiscale vision longformer,Scaling local self-attention for parameter efficient visual backbones]来减少计算负担。然而,这两种方法都削弱了原始完全自我关注的能力,即同时模拟短期和长期视觉依赖的能力,如图左侧所示。
-
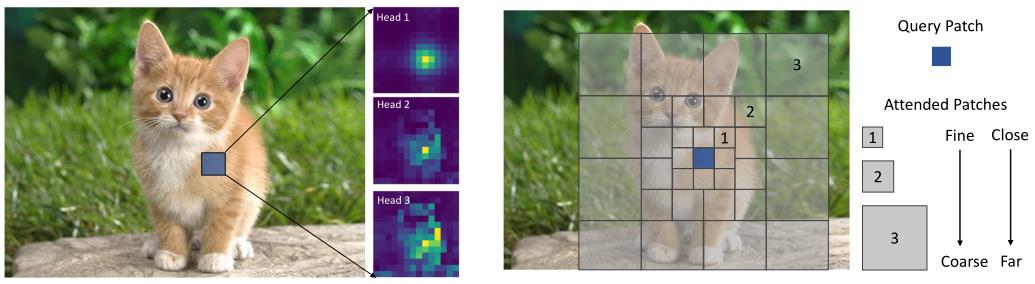
-
左图:DeiT Tiny模型第一层中给定查询补丁(蓝色)处三个头部的注意力图可视化。
-
右图:焦点自我注意机制的说明性描述。三个粒度级别用于组成蓝色查询的关注区域。
-
-
在本文中,提出了一种新的自我关注机制,以捕获高分辨率输入的Transformer层中的局部和全局交互。考虑到附近区域之间的视觉依赖性通常比远处区域更强,只在局部区域执行细粒度的自我关注,而在全局执行粗粒度的关注。
-
如上图右侧所示,特征图中的查询标记以最精细的粒度关注其最近的环境。然而,当它到达更远的区域时,它会关注汇总的标记以捕获粗粒度的视觉依赖。区域离查询越远,粒度越粗。因此,它可以有效地覆盖整个高分辨率特征图,同时在自关注计算中引入的令牌数量比在完全自关注机制中少得多。因此,它能够有效地捕获短期和长期的视觉依赖。我们称这种新机制为焦点自我关注,因为每一个标记都以焦点的方式关注其他标记。基于所提出的焦点自我关注,通过
-
1)利用多尺度架构来维持高分辨率图像的合理计算成本,
-
2)将特征图分割成多个窗口,其中令牌共享相同的环境,开发了一系列焦点transformer模型,而不是对每个令牌执行焦点自我关注。
-
-
通过对图像分类、目标检测和分割的全面实证研究,验证了所提出的焦点自我关注的有效性。结果表明,本文的Focal Transformer具有相似的模型大小和复杂性,在各种设置中始终优于SoTA Vision Transformer模型。值得注意的是,本文的具有51.1M参数的小型Focal Transformer模型可以在ImageNet-1K上获得83.5%的top-1精度,而具有89.8M参数的基础模型可以获得83.8%的top-1准确性。
-
当转移到物体检测时,本文的Focal Transformers在六种不同的物体检测方法上始终优于SoTA Swin Transformers。最大的Focal Transformer模型在COCO测试设备上分别实现了58.9盒mAP和51.3掩模mAP,用于对象检测和实例分割,在ADE20K上实现了55.4 mIoU,用于语义分割。这些结果表明,焦点自我注意力在视觉transformer中的局部-全局交互建模中非常有效。
Method
Model architecture
-
为了适应高分辨率视觉任务,本文的模型架构与[Pyramid vision transformer,Multiscale vision longformer,Swin transformer]共享类似的多尺度设计,这允许本文在早期阶段获得高分辨率特征图。
-
如下图所示,图像I∈RH×W×3 首先将划分为大小为4×4的patch,得到维数为4×4×3的H /4×W /4视觉标记。然后,使用面片嵌入层,该面片嵌入层由卷积层组成,滤波器大小和步长均等于4,将这些面片投影为维数为d的隐藏特征。给定该空间特征图,然后本文将其传递给四个阶段的焦点Transformer块。
-
在每个阶段i∈ {1,2,3,4},焦点transformer块由Ni焦点transformer层组成。在每个阶段之后,使用另一个面片嵌入层来将特征图的空间大小减小因子2,而特征维度增加了2。对于图像分类任务,取上一阶段输出的平均值,并将其发送到分类层。对于物体检测,根据本文使用的特定检测方法,将最后3个或所有4个阶段的特征图馈送到检测器头。模型容量可以通过改变输入特征尺寸d和每个阶段N1、N2、N3、N4的聚焦transformer层的数量来定制。
-

-
焦点transformer的模型架构。如浅蓝色方框所强调的,本文的主要创新是在每个Transformer层中提出的焦点自我关注机制。
-
-
标准的自我关注可以在细粒度上捕捉短距离和长距离交互,但当它在高分辨率特征图上执行关注时,它的计算成本很高,如[Multiscale vision longformer]中所述。以上图中的阶段1为例。对于尺寸为H/4×W/4×d的特征图,自我关注的复杂性为O((H/4×W/3)^2d),考虑到最小(H,W)为800或更大,因此导致时间和内存成本的爆炸。接下来,将描述本文如何通过提出的焦点自我关注来解决这一问题。
Focal self-attention
-
在本文中,提出了焦点自我关注,以使Transformer层可扩展到高分辨率输入。建议只在局部参加细粒度tokens,而在全局范围内参加汇总tokens,而不是参加细粒度的所有tokens。因此,它可以覆盖与标准自我关注一样多的地区,但成本要低得多。在下图中,显示了当本文逐渐添加更多的关注标记时,标准自我关注和本文的焦点自我关注的感受野区域。对于一个查询位置,当本文对其远处的环境使用逐渐变粗的颗粒时,焦点自我注意力可以具有明显更大的感受野,代价是观看与基线相同数量的视觉标记。
-

-
感受野(yaxis)的大小随着标准和我们的焦点自我注意力使用标记(x轴)的增加而增加。对于焦点自我关注,假设将窗口粒度逐渐增加因子2,但不超过8。注意,y轴是对数轴。
-
-
本文的焦点机制能够以更少的时间和内存成本实现长距离的自我关注,因为它关注的周围(汇总)tokens数量要少得多。然而,在实践中,为每个查询位置提取周围的令牌会带来很高的时间和内存成本,因为本文需要为所有可以访问它的查询复制每个令牌。
-
这一实际问题已被许多先前的工作[Scaling local self-attention for parameter efficient visual backbones,Multiscale vision longformer,Swin transformer]注意到,常见的解决方案是将输入特征图划分为窗口。
-
在他们的启发下,本文在窗口级别进行集中的自我关注。给定x∈RM×N×d的特征图空间大小为M×N,本文首先将其划分为大小为sp×sp的窗口网格。然后,本文找到每个窗口的环境,而不是单个令牌。在下文中,本文详细阐述了窗口式焦点自我关注。
Window-wise attention
-
下图显示了所提出的窗口式焦点自我关注的示例。为了清晰起见,首先定义了三个术语:
-
Focal levels L:为焦点自我关注提取令牌的粒度级别数。在上文第一张图中,例如,总共显示了3个焦点级别。
-
Focal window size s w l s^l_w swl:子窗口的大小,在该子窗口上获取级别的汇总令牌 l∈ {1,…,L},对于上文第一张图中的三个级别为1,2和4。
-
Focal region size s r l s^l_r srl–水平和垂直方向上在级别 l 的关注区域中的子窗口数量,在上文第一张图中,从级别1到级别3,它们分别为3、4和4。
-
-
使用上述三个术语L,sw,sr,可以指定本文的焦点自我关注模块,分两个主要步骤进行:
-
Sub-window pooling:假设输入特征图x∈ RM×N×d,其中M×N是空间维度,d是特征维度。本文为所有L级执行子窗口池。对于焦点级别l,首先将输入特征图x分割成大小为slw×slw的子窗口网格。然后,使用一个简单的线性层flp,通过以下方式在空间上汇集子窗口:
-
x l = f p l ( x ) ∈ R M s w l ∗ N s w l ∗ d , x = R e s h a p e ( x ) ∈ R M s w l ∗ N s w l ∗ d ∗ ( s w l ∗ s w l ) , ( 1 ) x^l=f^l_p(x)\\in R^\\fracMs^l_w*\\fracNs^l_w*d,\\\\ x=Reshape(x)\\in R^\\fracMs^l_w*\\fracNs^l_w*d*(s^l_w*s^l_w),(1) xl=fpl(x)∈RswlM∗swlN∗d,x=Reshape(x)∈RswlM∗swlN∗d∗(swl∗swl),(1)
-
不同级别的合并特征图{xl}L1提供了细粒度和粗粒度的丰富信息。由于本文为与输入特征图具有相同粒度的第一焦点级别设置slw=1,因此不需要执行任何子窗口池。考虑到焦点窗口大小通常很小(在本文的设置中最大为7个),这些子窗口池引入的额外参数的数量可以忽略不计。
-
Attention computation:一旦获得了所有L个级别的集合特征映射xlL1,本文就使用三个线性投影层fq、fk和fv计算第一级别的查询以及所有级别的关键字和值:
-
Q = f q ( x l ) , K = K l 1 L = f k ( x 1 , . . . , x L ) , V = V l 1 L = f v ( x 1 , . . . , x L ) , ( 2 ) Q=f_q(x^l),\\\\ K=\\K^l\\^L_1=f_k(\\x^1,...,x^L\\),\\\\ V=\\V^l\\^L_1=f_v(\\x^1,...,x^L\\),(2) Q=fq(xl),K=Kl1L=fk(x1,...,xL),V=Vl1L=fv(x1,...,xL),(2)
-
为了执行焦点自我关注,本文需要首先提取特征图中每个查询标记的周围标记。如前所述,窗口分区sp×sp内的令牌共享相同的环境集。对于第i个窗口Qi∈ Rsp×sp×d内的查询,从查询所在的窗口周围的Kl和V1中提取slr×slr keys和值,然后从所有l中收集关键字和值,以获得Ki=K1i,…,KLi∈ Rs×d和Vi=V 1i,…,V Li∈ Rs×d,其中s是所有级别的焦点区域的总和,即,s=PL l=1(slr)^2。
-
注意,上文图中的焦点自我关注的严格版本要求排除不同级别的重叠区域。在本文的模型中,有意保留它们,以便捕获重叠区域的金字塔信息。最后,根据[swin transformer]计算相对位置偏差,并通过以下公式计算Qi的焦点自我关注度:
-
A t t e n t i o n ( Q i , K i , V i ) = S o f t m a x ( Q i K i T d + B ) V i , ( 3 ) Attention(Q_i,K_i,V_i)=Softmax(\\fracQ_iK_i^T\\sqrt d+B)V_i,(3) Attention(Qi,Ki,Vi)=Softmax(dQiKiT+B)Vi,(3)
-
其中B=BlL1是可学习的相对位置偏差。它由L个焦点级别的L个子集组成。与[swin transformer]类似,对于第一级,我们将其参数化为B1∈ R(2sp−1) ×(2sp−1) ,考虑到水平和垂直位置范围都在[−sp+1,sp− 1]. 对于其他焦点级别,考虑到它们对查询的粒度不同,对窗口中的所有查询一视同仁,并使用Bl∈ Rslr×slr,表示查询窗口和每个slr×slr池令牌之间的相对位置偏差。
-
由于每个窗口的焦点自我关注独立于其他窗口,我们可以并行计算等式(3)。一旦完成了整个输入特征图的计算,将其发送到MLP块,以便照常进行计算。
-
Complexity analysis
-
本文分析了上面讨论的两个主要步骤的计算复杂性。对于输入功能图 x ∈ R M × N × d x∈ R^M×N×d x∈RM×N×d,在焦点级有 M s w l × N s w l \\fracMs^l_w×\\fracNs^l_w swlM×以上是关于读点论文Focal Self-attention for Local-Global Interactions in Vision Transformers局部和全局注意力进行交互实现新SOTA的主要内容,如果未能解决你的问题,请参考以下文章