pytorch dataset dataloader
Posted Melody2050
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pytorch dataset dataloader相关的知识,希望对你有一定的参考价值。
Dataset
pytorch提供了方便的接口,在实操环境中,你只需要:
- 实现一个自定义的Dataset类
- 赋值给内置的DataLoader,用于为训练模型提供batch。
那么如何实现Dataset类?只要重写改类中的两个函数即可:
__len__函数:返回数据集大小- _
_getitem__函数:返回对应索引的数据集中的样本
举个例子,实现一个取数Dataset,能返回从1到1000之间的所有数字:
from torch.utils.data import Dataset
class NumbersDataset(Dataset):
def __init__(self):
self.samples = list(range(1, 1001))
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
return self.samples[idx]
if __name__ == '__main__':
dataset = NumbersDataset()
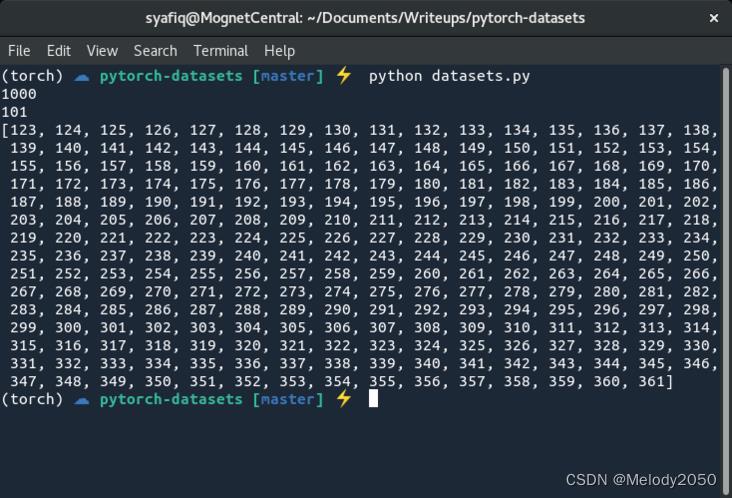
print(len(dataset))
print(dataset[100])
print(dataset[122:361])
运行程序,可看到如下结果。所以,Dataset的实现类可以做到取索引、取切片操作。
Dataloader
在实操中,通常使用原生的Dataloader即可,要复用现有的Dataset。其作用有二:
- 提供批次读取功能
- 提供乱序功能
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
class NumbersDataset(Dataset):
def __init__(self):
self.samples = list(range(1, 101))
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
return self.samples[idx]
if __name__ == '__main__':
dataset = NumbersDataset()
dataloader = DataLoader(dataset, batch_size=10)
for num in dataloader:
print(num)
我们沿用上面的NumbersDataset,并修改参数为显示1到100之间的数。然后定义了Dataloder,批次大小为10,再用for循环打印它们,输出如下:
tensor([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
tensor([11, 12, 13, 14, 15, 16, 17, 18, 19, 20])
tensor([21, 22, 23, 24, 25, 26, 27, 28, 29, 30])
tensor([31, 32, 33, 34, 35, 36, 37, 38, 39, 40])
tensor([41, 42, 43, 44, 45, 46, 47, 48, 49, 50])
tensor([51, 52, 53, 54, 55, 56, 57, 58, 59, 60])
tensor([61, 62, 63, 64, 65, 66, 67, 68, 69, 70])
tensor([71, 72, 73, 74, 75, 76, 77, 78, 79, 80])
tensor([81, 82, 83, 84, 85, 86, 87, 88, 89, 90])
tensor([ 91, 92, 93, 94, 95, 96, 97, 98, 99, 100])
Process finished with exit code 0
修改Dataloader为shuffle=True:
dataloader = DataLoader(dataset, batch_size=10, shuffle=True)
输出变成了如下:
tensor([70, 67, 30, 55, 11, 27, 44, 58, 5, 24])
tensor([96, 35, 57, 19, 59, 98, 18, 85, 89, 52])
tensor([16, 77, 78, 37, 61, 28, 3, 17, 48, 23])
tensor([95, 45, 82, 81, 90, 94, 49, 56, 6, 8])
tensor([69, 51, 64, 7, 54, 80, 74, 66, 39, 46])
tensor([71, 87, 93, 4, 99, 68, 73, 53, 88, 92])
tensor([36, 76, 43, 42, 63, 72, 22, 75, 26, 29])
tensor([31, 38, 83, 15, 84, 97, 21, 12, 62, 50])
tensor([47, 20, 33, 91, 2, 10, 9, 41, 14, 32])
tensor([ 60, 86, 1, 13, 40, 79, 34, 25, 100, 65])
Process finished with exit code 0
以上是关于pytorch dataset dataloader的主要内容,如果未能解决你的问题,请参考以下文章