torchaudio音频基础知识学习
Posted 来点实际的东西
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了torchaudio音频基础知识学习相关的知识,希望对你有一定的参考价值。
torchaudio音频基础知识学习
文章目录
贴出本文学习的主要来源: pytorch官网torchaudio的学习文档
需要使用的工具函数
import torchaudio
import torch
import matplotlib.pyplot as plt
import librosa
# 绘制波形图
def plot_waveform(waveform, sample_rate):
waveform = waveform.numpy()
num_channels, num_frames = waveform.shape
time_axis = torch.arange(0, num_frames) / sample_rate
figure, axes = plt.subplots(num_channels, 1)
if num_channels == 1:
axes = [axes]
for c in range(num_channels):
axes[c].plot(time_axis, waveform[c], linewidth=1)
axes[c].grid(True)
if num_channels > 1:
axes[c].set_ylabel(f"Channel c + 1")
figure.suptitle("waveform")
plt.show()
# 绘制频频谱图
def plot_specgram(waveform, sample_rate, title="Spectrogram"):
waveform = waveform.numpy()
num_channels, num_frames = waveform.shape
figure, axes = plt.subplots(num_channels, 1)
if num_channels == 1:
axes = [axes]
for c in range(num_channels):
axes[c].specgram(waveform[c], Fs=sample_rate)
if num_channels > 1:
axes[c].set_ylabel(f"Channel c + 1")
figure.suptitle(title)
plt.show()
# 绘制梅尔频谱图
def plot_spectrogram(specgram, title=None, ylabel="freq_bin"):
fig, axs = plt.subplots(1, 1)
axs.set_title(title or "Spectrogram(db)")
axs.set_ylabel(ylabel)
axs.set_xlabel("frame")
im = axs.imshow(librosa.power_to_db(specgram), origin="lower", aspect="auto")
fig.colorbar(im, ax=axs)
plt.show()
前置知识
-
sample_rate: 采样率
从原始音频中一秒钟采样的次数,可以得到sample_rate个采样点,每个采样点就是一个数值。原始的音频可以用波形图表示,包含了音量(振幅)、音频(频率)等各种信息,这里的采样就是直接将波形图上的值(可以简单理解为正弦、余弦图上的函数值)量化成数值。因为波形图是连续的,我们没法做到全部采样,只能离散的采样一些值,单位时间采样的值越多,采样率越高,保存的信息就越多,音频质量就越好。
-
bit_per_sample: 位深
采样率中我们提到量化的概念,位深与此有关。常见的位深有 8bit,16bit等,以8bit为例,我们可以将波形图沿竖直方向切分成 2^8(256)份,每个采样点的取值为0-255 .
-
num_channels: 声道数
单声道,双声道,从多个声源采样。声源数量不同,立体音乐就有多个声道,效果更好。
-
encoding : 采样使用的编码格式
了解的有限。。大概有“PCM_S”、“MP3”、“PCM_U”、“ULAW”、“GSM”等音频编码格式。
-
frames: 音频帧
简单来讲,就是一组采样点的集合。 语音信号是一个非稳态的、时变的信号。但在短时间范围内可以认为语音信号是稳态的、时不变的,这个短时间一般取 10-30ms。进行语音信号处理时,为减少语音信号整体的非稳态、时变的影响,从而对语音信号进行分段处理,其中每一段称为一帧,帧长一般取 25ms。为了使帧与帧之间平滑过渡,保持其连续性,分帧一般采用交叠分段的方法,保证相邻两帧相互重叠一部分,末尾不足部分用零填充。相邻两帧的起始位置的时间差称为帧移,我们一般在使用中帧移取值为 10ms。
采样率为16kHz的音频,假设帧长为25ms,一帧就有16000*0.025=400个采样点。(一秒音频有16k个采样点)。从音频开始处,划分帧,但是帧与帧之间会有重叠。
但是在torchaudio中num_frames似乎表示的一段一音频中采样点的数量,而非帧的数量???刚开始的时候把我看迷糊了
音频的表示形式
我们称原始的音频信号为波形, 绘制waveform代码如下:
from torchaudio.utils import download_asset
# 使用download_asset从网上下载音频文件保存到本地,返回本地文件路径
SAMPLE_WAV = download_asset("tutorial-assets/Lab41-SRI-VOiCES-src-sp0307-ch127535-sg0042.wav")
print(SAMPLE_WAV)
# 本地的音频文件路径
audio_file_path = SAMPLE_WAV
metadata = torchaudio.info(SAMPLE_WAV)
print(metadata)
# load中可以传入音频文件的路径(path-like)或者原始的音频文件数据(file-like)
# waveform是一个tensor数据,size:(channels,num_frames),官方写的是num_frames,我理解的是采样点的个数num_samples
waveform, sample_rate = torchaudio.load(SAMPLE_WAV)
plot_waveform(waveform,sample_rate)
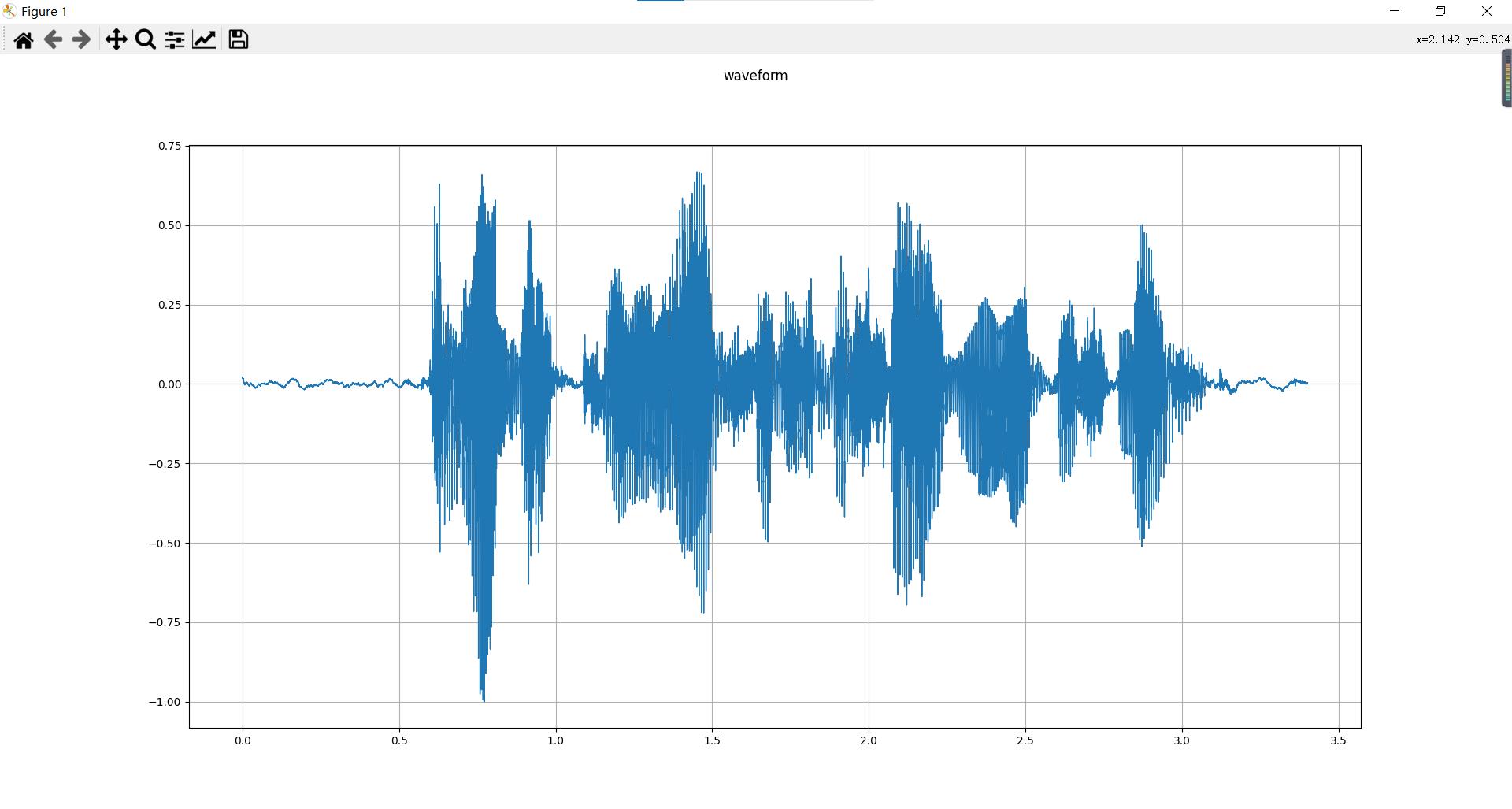
在介绍spectrogram之前,这里先简单介绍一下时域和频域,频谱图
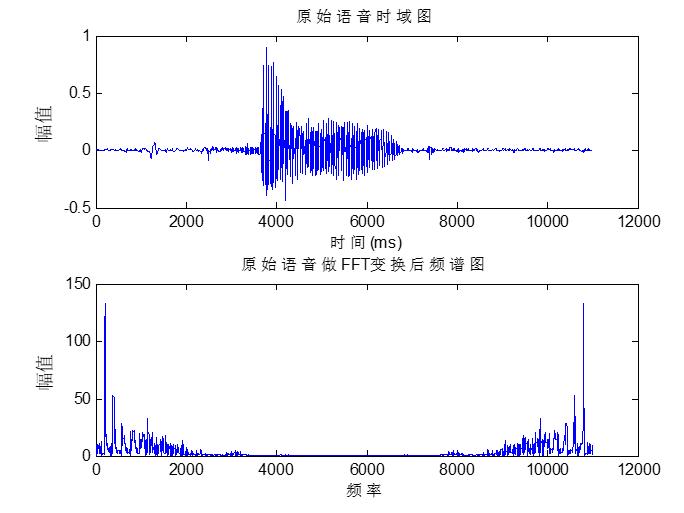
频谱图:简单理解为频率分布图,复杂的信号主要在于信号中包含了不同频率成分的信号。在时域信号上使用傅里叶变换(FT)就能得到信号的频域表示
横坐标为各种不同的频率,纵坐标为振幅值
波形实质上是将各个频率的波形叠加在了一起(波形是由各频率不同幅值和相位的简单正弦波复合叠加得到的。)表示的是一个静态的时间点上各频率正弦波的幅值大小的分布状况。下面的图非常典型,可以加深理解。
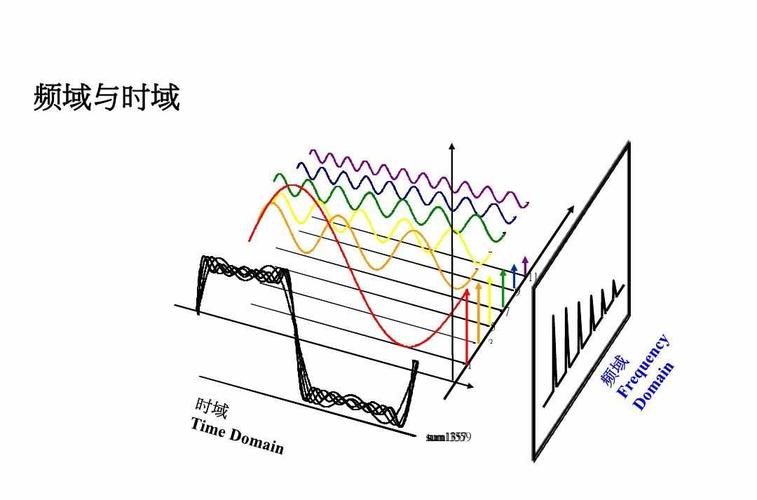
关于时域、频域、时频域的更多分析,可以参考下面这篇博客:https://blog.csdn.net/Robin_Pi/article/details/109204672
关于语谱图更加详细的信息可以参考这篇博客,个人认为非常清晰了。
https://blog.csdn.net/chumingqian/article/details/123019808
下面进入正题,spectrogram是使用短时傅里叶变换得到信号的频谱图。ps:百度百科的介绍是这样的,按我的理解频谱图应该就是频域图,只包含频域信息??这个百度百科的介绍我有点迷惑。
刚入门语音处理,好多基础知识都快把我搞迷糊了,继续坚持😭😭
anyway,大家更多的称spectrogram 为语谱图/时频图/声谱图,语谱图是声音数据通过STFT(短时傅立叶变换)转换得到的。短时很好理解,就是将一段语音信号分成多帧,每一帧包含了一小段时间的语音信号,帧变成了分析处理的基本单元。
语谱图上横轴为时间,纵轴为频率,用颜色表示幅度,可以得到信号的时频分布。经常还对幅度进行相应的转换,得到功率表示(amplitude squared振幅的平方),或者db表示【 10 * log10(S / ref)】。
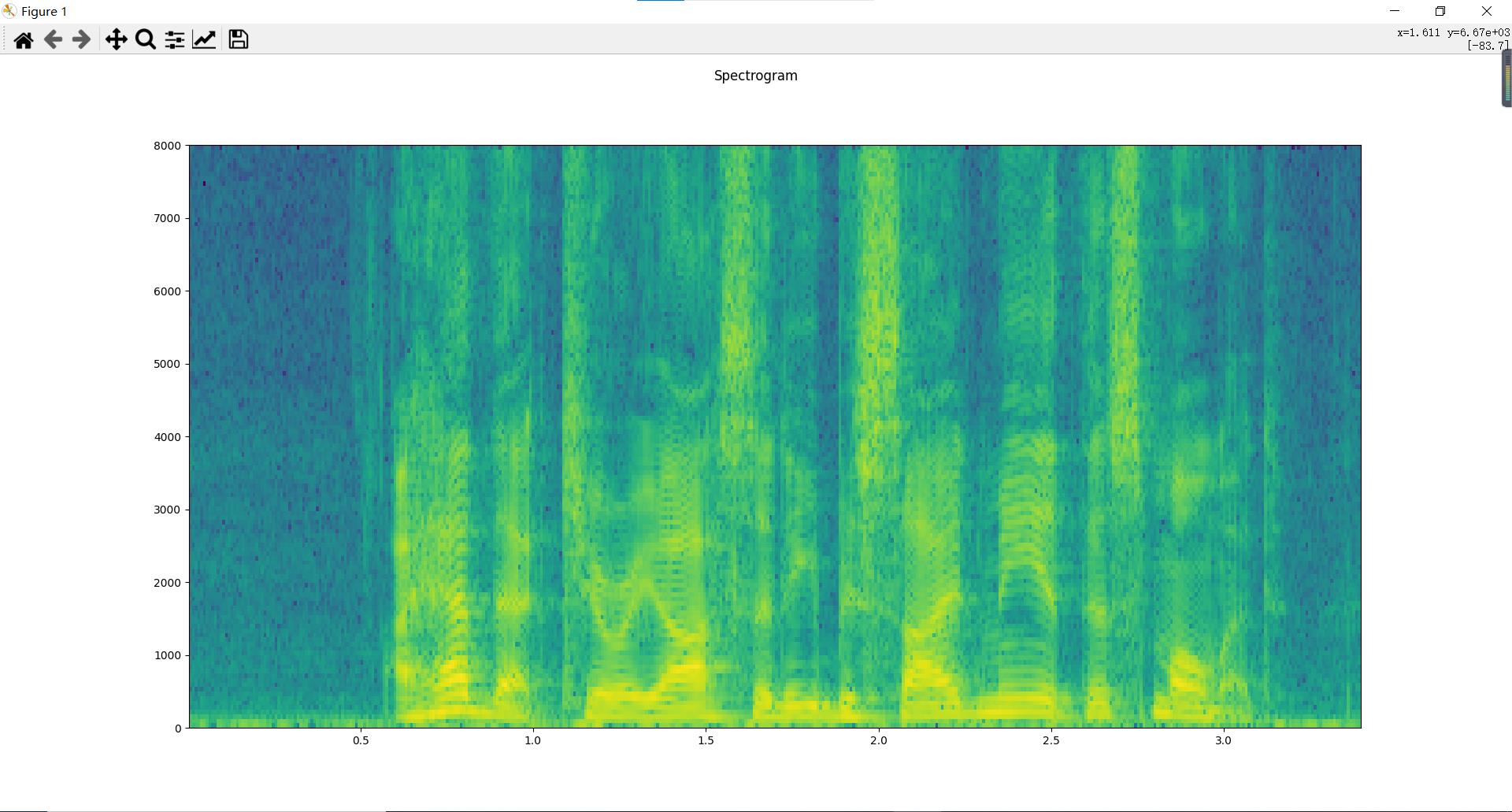
torchaudio中绘制spectrogram 语谱图的代码:
# waveform和sample_rate见上文绘制波形图
plot_specgram(waveform,sample_rate) #详细见工具函数
声谱图对频率范围维持了原始的audio的频率范围,但这个对人耳来说不是好事,人对声音的敏感区域和敏感度有自己的特点。频率的单位是赫兹(Hz),人耳能听到的频率范围是20-20000Hz,但人耳对Hz这种标度单位并不是线性感知关系,所以我们把频率转换到了mel scale尺度下,人的感知在mel scale下就是线性关系。
人耳对低频信号的区别更加敏感,而对高频信号的区别不是那么敏感。在低频段上的两个频度和高频上的两个频度,人们会更容易区分前者。也就是说,频域上相等距离的两对频度,对于人耳来说他们的距离不一定相等。
那么,能不能调整频域的刻度,使得这个新的刻度上相等距离的两对频度,对于人耳来说也相等呢?答案是可以的,这就是梅尔刻度。
在语谱的基础上,我们可以得到梅尔频谱,简单的来讲,梅尔频谱就是将原来的语谱图上的频率刻度转换成梅尔刻度,这是通过梅尔滤波器组(mel-scale filter banks)转换得到的。其实经过这种转换之后,在频度这一维度上,维度是降低了,例如:原来一段语音信号的语谱图中纵坐标(频度Hz)有513个刻度,经过转换之后,变成了mel freq刻度,只有128个刻度。
因此用来表示这段语音信号的数据量减少了,因此在模型训练中使用的话可以大幅减少cost。例如:语谱图中的数据表示(513,359),513是频度(Hz)刻度,359是num_frames(语音信号分成的帧数),变成梅尔频谱后,数据表示为(128,359),数据量约为原来的1/4。
但是!!
既然降维了,那么原本数据的信息必然损失了一部分,但因为梅尔刻度是针对人耳设计的,因此梅尔频谱很大程度上保留了人耳理解原本语音所需的信息,这就是梅尔频谱的精髓所在。
梅尔频谱图
绘制出的梅尔频谱图,横坐标表示帧数(与语谱图似乎有些不对应,语谱图貌似表示的是时间,但是其实语谱图也是分成了多帧,但是相当于做了一个简单的变换,当前帧数/总帧数 音频时长,即可转换成时间),纵坐标表示梅尔刻度下的频度,颜色表示幅度(幅度做一定的变化,平方可以转成功率/能量,在取对数运算转成db)。所以并不总是,一定表示的是 时间-频度-幅度 的三维信息,也可以是时间-频度-功率* 图等等。
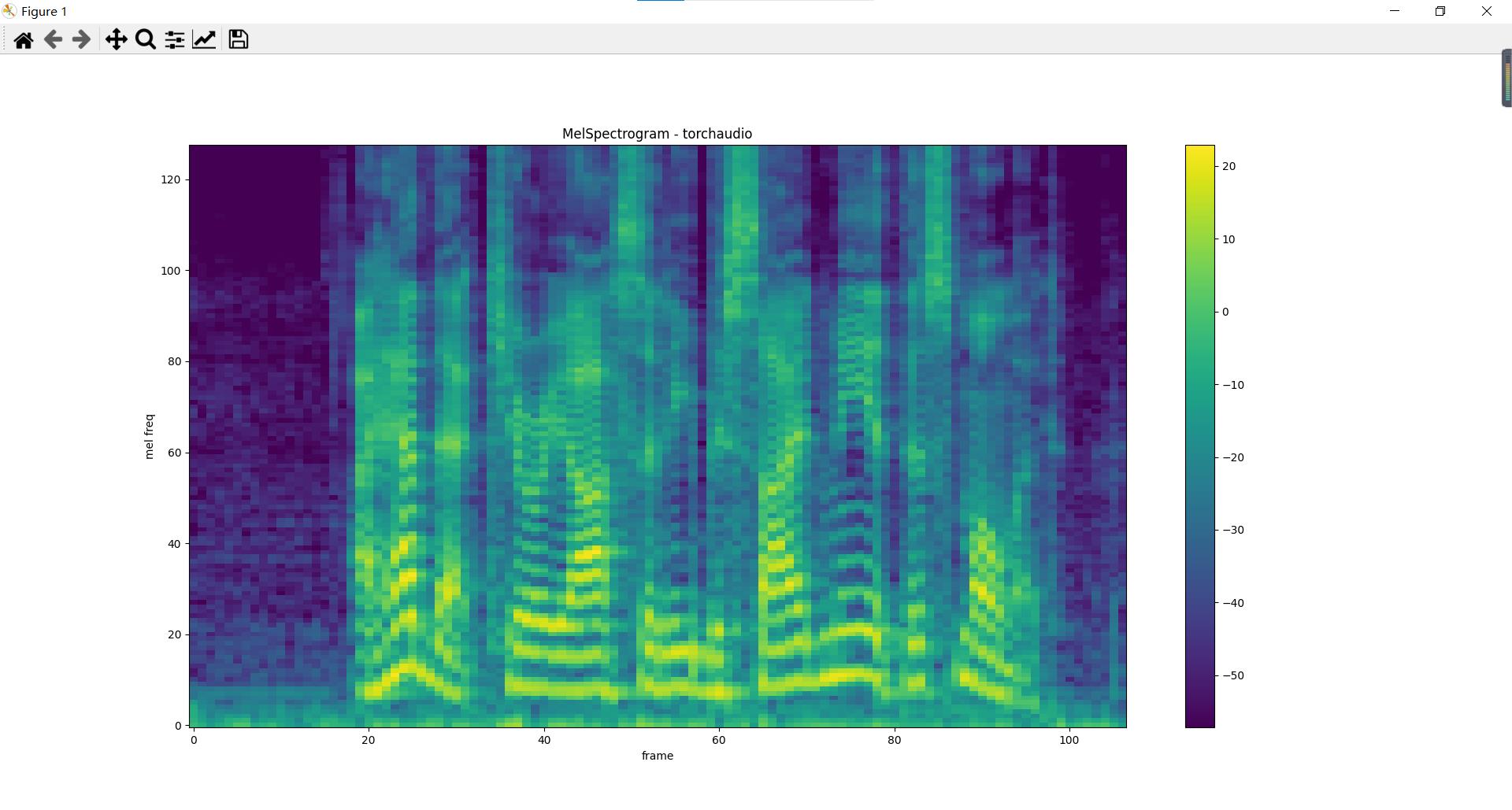
torchaudio中绘制梅尔频谱图的代码如下:
import torchaudio.transforms as T
n_fft = 1024
win_length = None
hop_length = 512
n_mels = 128
mel_spectrogram = T.MelSpectrogram(
sample_rate=sample_rate,
n_fft=n_fft,
win_length=win_length,
hop_length=hop_length,
center=True,
pad_mode="reflect",
power=2.0,
norm="slaney",
onesided=True,
n_mels=n_mels,
mel_scale="htk",
)
melspec = mel_spectrogram(waveform)
plot_spectrogram(melspec[0], title="MelSpectrogram - torchaudio", ylabel="mel freq")
总结
这篇文章是我在入坑深度学习、语音合成(TTS)的基础知识的学习记录,其实期间遇到了不少令人费解的知识点,看了一些博客与文档,算是大致掌握了一些基础的知识,但其实比较细致的东西没有深究,但总体来说,对语音数据的表示有了更加深刻的了解,希望之后能够继续坚持下去。
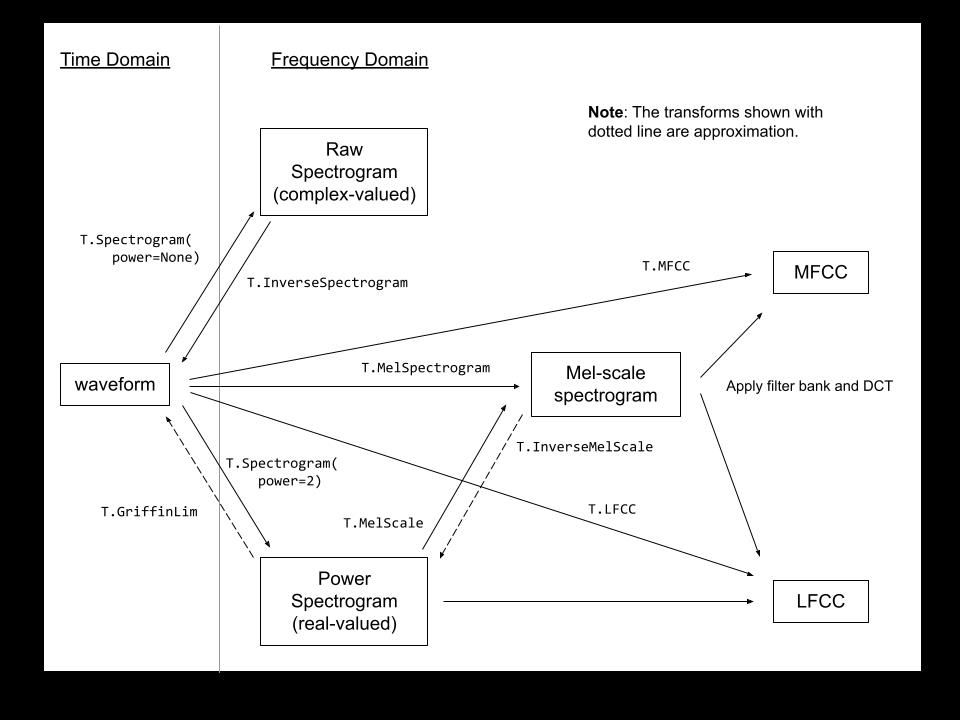
ps:本文只介绍了语音信号的几种表示形式,波形、语谱、梅尔频谱三种比较常见的表达方式,但其实像MFCC也比较常见,但并没有介绍,这里给出pytorch官网的一张图片,给一个概览,各种语音信号表示形式以及它们之间的转换。
以上是关于torchaudio音频基础知识学习的主要内容,如果未能解决你的问题,请参考以下文章