19 分布式缓存集群的伸缩性设计
Posted water___Wang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了19 分布式缓存集群的伸缩性设计相关的知识,希望对你有一定的参考价值。

不同于应用服务器集群的伸缩性设计,分布 式缓存集群的伸缩性不能使用简单的负载均衡手段来实现。
和所有服务器都部署相同应用的应用服务器集群不同,分布式缓存服务器集群中不同服务器中缓存的数据各不相同,缓存访问请求不可以在缓存服务器集群中的任意一台 处理,必须先找到缓存有需要数据的服务器,然后才能访问。这个特点会严重制约分布 式缓存集群的伸缩性设计,因为新上线的缓存服务器没有缓存任何数据,而已下线的缓 存服务器还缓存着网站的许多热点数据。
必须让新上线的缓存服务器对整个分布式缓存集群影响最小,也就是说新加入缓存 服务器后应使整个缓存服务器集群中已经缓存的数据尽可能还被访问到,这是分布式缓 存集群伸缩性设计的最主要目标。
1 Memcached分布式缓存集群的访问模型
以Memcached为代表的分布式缓存,访问模型如图6.10所示。
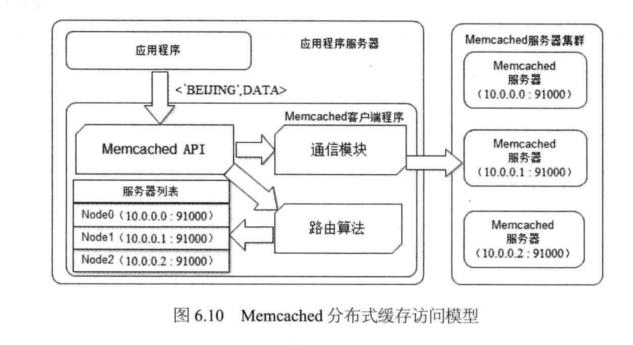
应用程序通过Memcached客户端访问Memcached服务器集群,Memcached客户端主 要由一组API、Memcached服务器集群路由算法、Memcached服务器集群列表及通信模 块构成。
其中路由算法负责根据应用程序输入的缓存数据KEY计算得到应该将数据写入到 Memcached的哪台服务器(写缓存)或者应该从哪台服务器读数据(读缓存)。
一个典的型缓存写操作如图6.10中箭头所示路径。应用程序输入需要写缓存的数据 v,BEIJING,DATA>, API将KEY (•BEIJING’)输入路由算法模块,路由算法根据KEY和 Memcached集群服务器列表计算得到一台服务编号(NODE1),进而得到该机器的IP地 址和端口( 10.0.0.0:91000)。API调用通信模块和编号为NODE1的服务器通信,将数据 <,BEIJING\\DATA>写入该服务器。完成一次分布式缓存的写操作。
读缓存的过程和写缓存一样,由于使用同样的路由算法和服务器列表,只要应用程 序提供相同的KEY ('BEIJING*), Memcached客户端总是访问相同的服务器(NODE1 ) 去读取数据。只要服务器还缓存着该数据,就能保证缓存命中。
2 Memcached分布式缓存集群的伸缩性挑战
由上述讨论可得知,在Memcached分布式缓存系统中,对于服务器集群的管理,路由算法至关重要,和负载均衡算法一样,决定着究竟该访问集群中的哪台服务器。
简单的路由算法可以使用余数Hash:用服务器数目除以缓存数据KEY的Hash值, 余数为服务器列表下标编号。假设图6.10中BEIJING的Hash值是490806430 ( Java中的HashCode()返回值),用服务器数目3除以该值,得到余数1,对应节点NODElo由于 HashCode具有随机性,因此使用余数Hash路由算法可保证缓存数据在整个Memcached 服务器集群中比较均衡地分布。
对余数Hash路由算法稍加改进,就可以实现和负载均衡算法中加权负载均衡一样的加权路由。事实上,如果不需要考虑缓存服务器集群伸缩性,余数Hash几乎可以满足绝 大多数的缓存路由需求。
但是,当分布式缓存集群需要扩容的时候,事情就变得棘手了。
假设由于业务发展,网站需要将3台缓存服务器扩容至4台。更改服务器列表,仍旧使用余数Hash,用4除以EEIJING的Hash值49080643,余数为2,对应服务器NODE2o 由于数据<,BEIJING,DATA>缓存在NODE1,对NODE2的读缓存操作失败,缓存没有命 中。
很容易就可以计算出,3台服务器扩容至4台服务器,大约有75%( 3/4)被缓存了的数据不能正确命中,随着服务器集群规模的增大,这个比例线性上升。当100台服务 器的集群中加入一台新服务器,不能命中的概率是99% (N/(N+1))。
这个结果显然是不能接受的,在网站业务中,大部分的业务数据读操作请求事实上 是通过缓存获取的,只有少量读操作请求会访问数据库,因此数据库的负载能力是以有 缓存为前提而设计的。当大部分被缓存了的数据因为服务器扩容而不能正确读取时,这 些数据访问的压力就落到了数据库的身上,这将大大超过数据库的负载能力,严重的可 能会导致数据库宕机(这种情况下,不能简单重启数据库,网站也需要较长时间才能逐 渐恢复正常。详见本书第13章。)
本来加入新的缓存服务器是为了降低数据库的负载压力,但是操作不当却 导致了数据库的崩溃。如果不对问题和解决方案有透彻了解,网站技术总有想 不到的陷阱让架构师一脚踩空。遇到这种情况,用某网站一位资深架构师的话说,就是“一股寒气从脚底板窜到了脑门心”。
一种解决办法是在网站访问量最少的时候扩容缓存服务器集群,这时候对数据库的 负载冲击最小。然后通过模拟请求的方法逐渐预热缓存,使缓存服务器中的数据重新分 布。但是这种方案对业务场景有要求,还需要技术团队通宵加班(网站访问低谷通常是 在半夜)o
能不能通过改进路由算法,使得新加入的服务器不影响大部分缓存数据的正确命中 呢?目前比较流行的算法是一致性Hash算法。
3 分布式缓存的一致性Hash算法
一致性Hash算法通过一个叫作一致性Hash环的数据结构实现KEY到缓存服务器的 Hash映射,如图6.11所示。
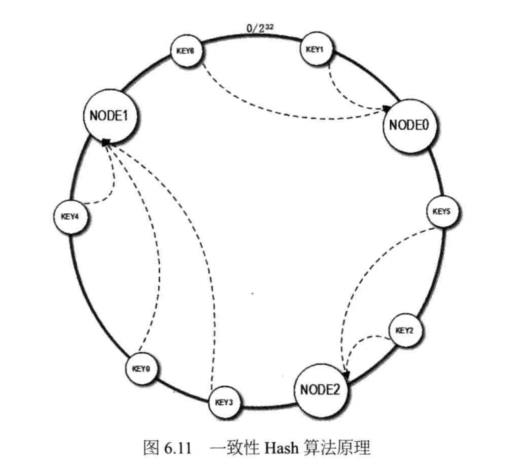
具体算法过程为:先构造一个长度为。02的32次方的整数环(这个环被称作一致性Hash环),根据节点名称的Hash值(其分布范围同样为02的32次方)将缓存服务器节点放置在这个Hash 环上。然后根据需要缓存的数据的KEY值计算得到其Hash值(其分布范围也同样为0~2的32次方),然后在而‘代环上顺时针查找距离这个KEY的Hash值最近的缓存服务器节点,完成KEY到服务器的Hash映射查找。
在图 6.11 中,假设 N0DE1 的 Hash 值为 3,594,963,423, NODE2 的 Hash 值为1,845,328,979,而KEYO的Hash值为2,534,256,785,那么KEYO在环上顺时针查找,找
到的最近的节点就是NODEl。
当缓存服务器集群需要扩容的时候,只需要将新加入的节点名称(NODE3 )的Hash 值放入一致性Hash环中,由于KEY是顺时针查找距离其最近的节点,因此新加入的节点只影响整个环中的一小段,如图6.12中深色一段。
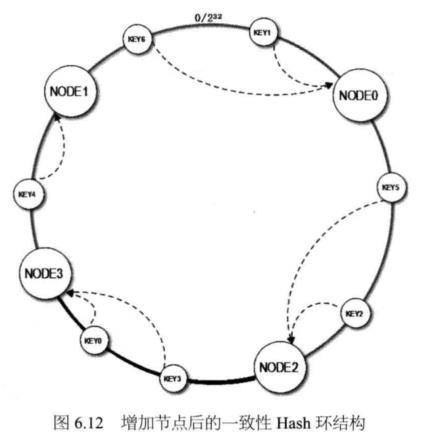
假设 NODE3 的 Hash 值是 2,790,324,235,那么加入 NODE3 后,KEY0( Hash 值 2,534, 256,785 )顺时针查找得到的节点就是NODE3。
图6.12中,加入新节点NODE3后,原来的KEY大部分还能继续计算到原来的节点, 只有KEY3、KEY0从原来的NODE1重新计算到NODE3。这样就能保证大部分被缓存的 数据还可以继续命中。3台服务器扩容至4台服务器,可以继续命中原有缓存数据的概率 是75%,远高于余数Hash的25%,而且随着集群规模越大,继续命中原有缓存数据的概率也逐渐增大,100台服务器扩容增加1台服务器,继续命中的概率是99%。虽然仍有小 部分数据缓存在服务器中不能被读到,但是这个比例足够小,通过访问数据库获取也不 会对数据库造成致命的负载压力。
具体应用中,这个长度为232的一致性Hash环通常使用二叉查找树实现,Hash查找过程实际上是在二叉查找树中查找不小于查找数的最小数值。当然这个二叉树的最右边 叶子节点和最左边的叶子节点相连接,构成环。
但是,上面描述的算法过程还存在一个小小的问题。
新加入的节点NODE3只影响了原来的节点NODE1,也就是说一部分原来需要访问NODE1的缓存数据现在需要访问N0DE3 (概率上是50% )。但是原来的节点NODEO和NODE2不受影响,这就意味着NODEO和NODE2缓存数据量和负载压力是NODE1与NODE3的两倍。如果4台机器的性能是一样的,那么这种结果显然不是我们需要的。
怎么办?
计算机领域有句话:计算机的任何问题都可以通过增加一个虚拟层来解决。计算机 硬件、计算机网络、计算机软件都莫不如此。计算机网络的7层协议,每一层都可以看 作是下一层的虚拟层;计算机操作系统可以看作是计算机硬件的虚拟层;Java虚拟机可 以看作是操作系统的虚拟层;分层的计算机软件架构事实上也是利用虚拟层的概念。
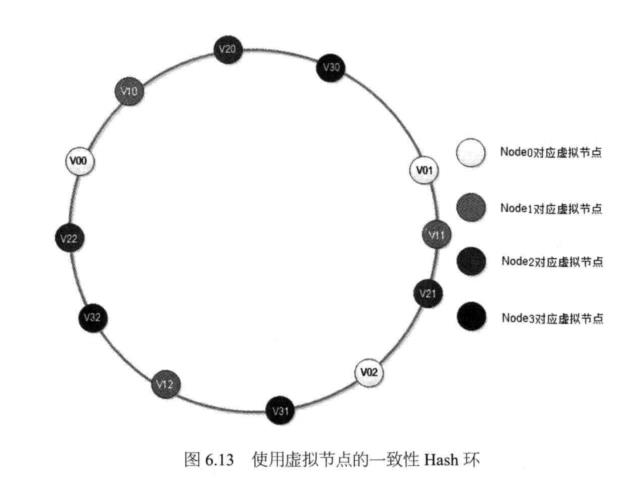
解决上述一致性Hash算法带来的负载不均衡问题,也可以通过使用虚拟层的手段: 将每台物理缓存服务器虚拟为一组虚拟缓存服务器,将虚拟服务器的Hash值放置在Hash 环上,KEY在环上先找到虚拟服务器节点,再得到物理服务器的信息。
这样新加入物理服务器节点时,是将一组虚拟节点加入环中,如果虚拟节点的数目足够多,这组虚拟节点将会影响同样多数目的已经在环上存在的虚拟节点,这些已经存 在的虚拟节点又对应不同的物理节点。最终的结果是:新加入一台缓存服务器,将会较 为均匀地影响原来集群中已经存在的所有服务器,也就是说分摊原有缓存服务器集群中 所有服务器的一小部分负载,其总的影响范围和上面讨论过的相同。如图6.13所示。
在图6.13中,新加入节点NODE3对应的一组虚拟节点为V30, V31, V32,加入到 一致性Hash环上后,影响V01, V12, V22三个虚拟节点,而这三个虚拟节点分别对应 NODEO, NODEI, NODE2三个物理节点。最终Memcached集群中加入一个节点,但是同时影响到集群中已存在的三个物理节点,在理想情况下,每个物理节点受影响的数据 量(还在缓存中,但是不能被访问到数据)为其节点缓存数据量的1/4 (A7(NE¥), N为原 有物理节点数,X为新加入物理节点数),也就是集群中已经被缓存的数据有75%可以被 继续命中,和未使用虚拟节点的一致性Hash算法结果相同。
显然每个物理节点对应的虚拟节点越多,各个物理节点之间的负载越均衡,新加入 物理服务器对原有的物理服务器的影响越保持一致(这就是一致性Hash这个名称的由 来)。那么在实践中,一台物理服务器虚拟为多少个虚拟服务器节点合适呢?太多会影响 性能,太少又会导致负载不均衡,一般说来,经验值是150,当然根据集群规模和负载均 衡的精度需求,这个值应该根据具体情况具体对待。
以上是关于19 分布式缓存集群的伸缩性设计的主要内容,如果未能解决你的问题,请参考以下文章