Hadoop——WordCount运行和解读
Posted mmい
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop——WordCount运行和解读相关的知识,希望对你有一定的参考价值。
执行WordCount程序
1.以hadoop用户进入到linux系统

2.启动hadoop
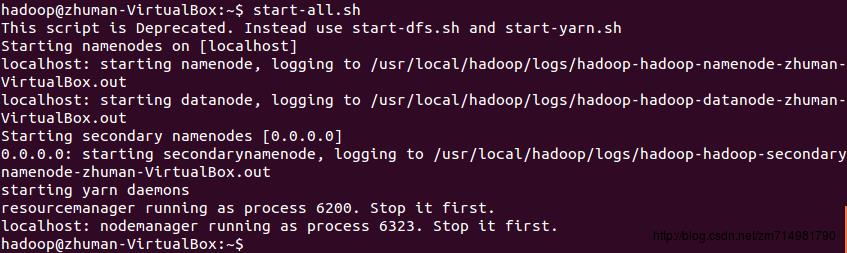
3.在home目录下创建一个file文件夹,”~/”表示在home目录下,”/”表示在根目录下。并且在文件夹file内创建两个文本文件file1.txt和file2.txt.
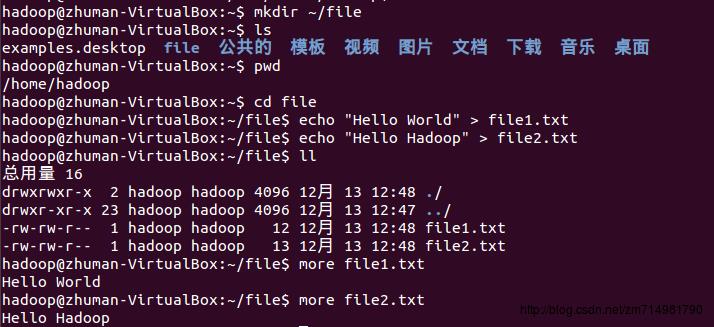
4.在HDFS上创建输入文件夹。调用文件系统(FS)Shell命令应使用bin/hadoop fs 的形式,因为环境变量配置的是”$HADOOP_HOME/bin,所以可以省略掉bin直接使用
<args>hadoop fs <args>来执行文件系统命令。在运行hadoop程序处理存储在HDFS上的数据之前,你需要首先把数据放在HDFS上。HDFS有一个默认的工作目录/user/USER,其中USER是你的登录用户名。我登录的hadoop用户所以是/user/hadoop,你需要用你的用户名来替换。下面我创建了两个目录,一个是使用默认的HDFS工作目录,一个是指明了绝对路径/user/hadoop/.
因为我们在ore-site.xml中配置了
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>所以完整的URIhdfs://localhost:9000/user/hadoop/input缩短为/user/hadoop/input
5.上传本地file中文件到集群的input目录下,put命令从本地文件系统中复制单个或多个源路径到目标文件系统。也支持从标准输入中读取输入写入目标文件系统。

6.已经编译好的WordCount的Jar在/usr/local/hadoop/share/hadoop/mapreduce目录下,其中/usr/local/hadoop是hadoop的安装目录。
7.执行jar命令时运行WordCount程序,记得把路径写全了,不然会提示找不到该jar包。

8.MapReduce执行过程显示信息,以下就是Hadoop Job的运行记录,从这里可以看到,这个Job被赋予了一个ID号:job_local509694306_0001,而且得知输入文件有两个(Total input paths to process : 2)。
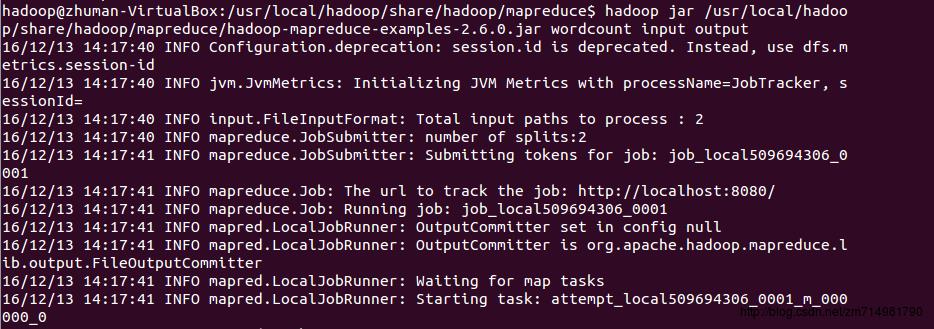
9.map任务全部结束后才会开始执行reduce任务

10.MapReduce运行参数
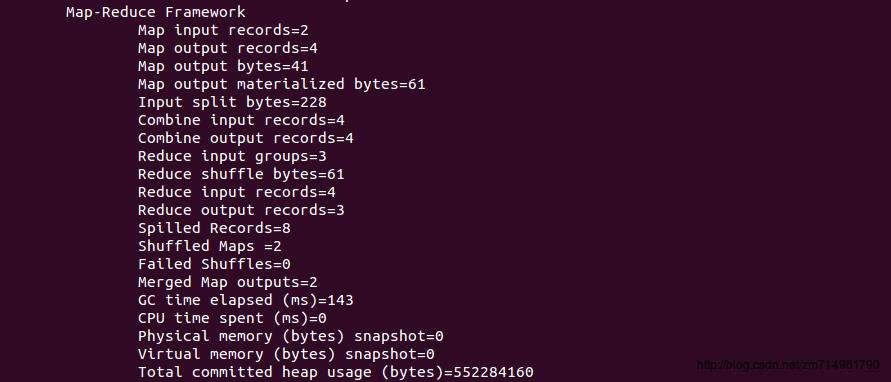
11.查看HDFS上output目录内容,结果和我们预想的一样。

也可以将HDFS中的文件读取到本地来,使用get命令:
WordCount源码分析
WordCount 类里面有两个嵌套类(静态内部类)TokenizerMapper和IntSumReducer,它们分别实现了Mapper和Reducer抽象类.
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
/*context: 用户与MR系统交互的上下文*/
public void map(Object key, Text value, Context context)throws IOException, InterruptedException
/*StringTokenizer:将字符串分解为一个个单词*/
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
word.set(itr.nextToken());//将token写入word
context.write(word, one);//word出现一次产生一个键值对,因此value一直是one.
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable>
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,Context context)
throws IOException, InterruptedException
int sum = 0;
/*遍历同一个key集合中所有的value 累加求和得到token的词频*/
for (IntWritable val : values)
sum += val.get();
result.set(sum);
context.write(key, result);
public static void main(String[] args) throws Exception
Configuration conf = new Configuration();//读取Hadoop配置信息
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2)
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
Job job = new Job(conf, "word count"); //创建MR Job
job.setJarByClass(WordCount.class); //设置启动类
job.setMapperClass(TokenizerMapper.class); //设置Mapper类
job.setCombinerClass(IntSumReducer.class); //设置中间结果合并类
job.setReducerClass(IntSumReducer.class); //设置Reducer类
job.setOutputKeyClass(Text.class); //设置输出Key的类型
job.setOutputValueClass(IntWritable.class); //设置输出值的类型
FileInputFormat.addInputPath(job, new Path(otherArgs[0])); //设置输入文件目录
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); //设置输出文件目录
System.exit(job.waitForCompletion(true) ? 0 : 1); //等待Job完成
因为map的结果是<单词,个数>,所以key设置为”Text”类型,相当于Java中String类型。Value设置为”IntWritable”,相当于Java中的Integer类型。
map的输出通过context交给reduce函数之前,要把相同key的value都合并到一个集合里,因此reduce的第二个参数是集合类型,第一个参数key即为token。
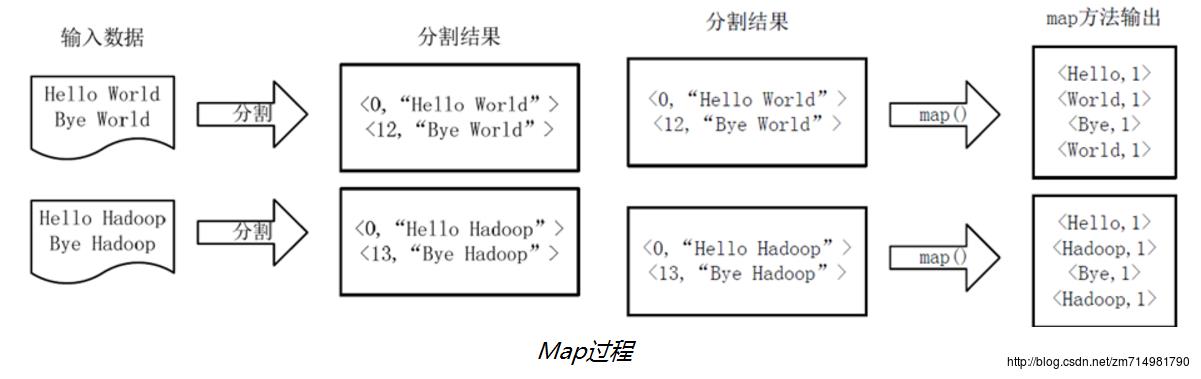
Hadoop预定义了多种方法将不同类型的输入数据转化为map能够处理的
<key,value>对,它们都继承自InputFormat,其中TextInputFormat是Hadoop默认的输入方法,在TextInputFormat中,每个文件(或其一部分)都会单独地作为map的输入,而这个是继承自FileInputFormat的。之后,每行数据都会生成一条记录,每条记录则表示成<key,value>形式。我们在主函数里省略掉了FileInputFormat的设置,可以添加下面代码,效果是一样的:
job.setInputFormat(TextInputFormat.class);
job.setOutputFormat(TextOutputFormat.class);InputFormat()和InputSplit
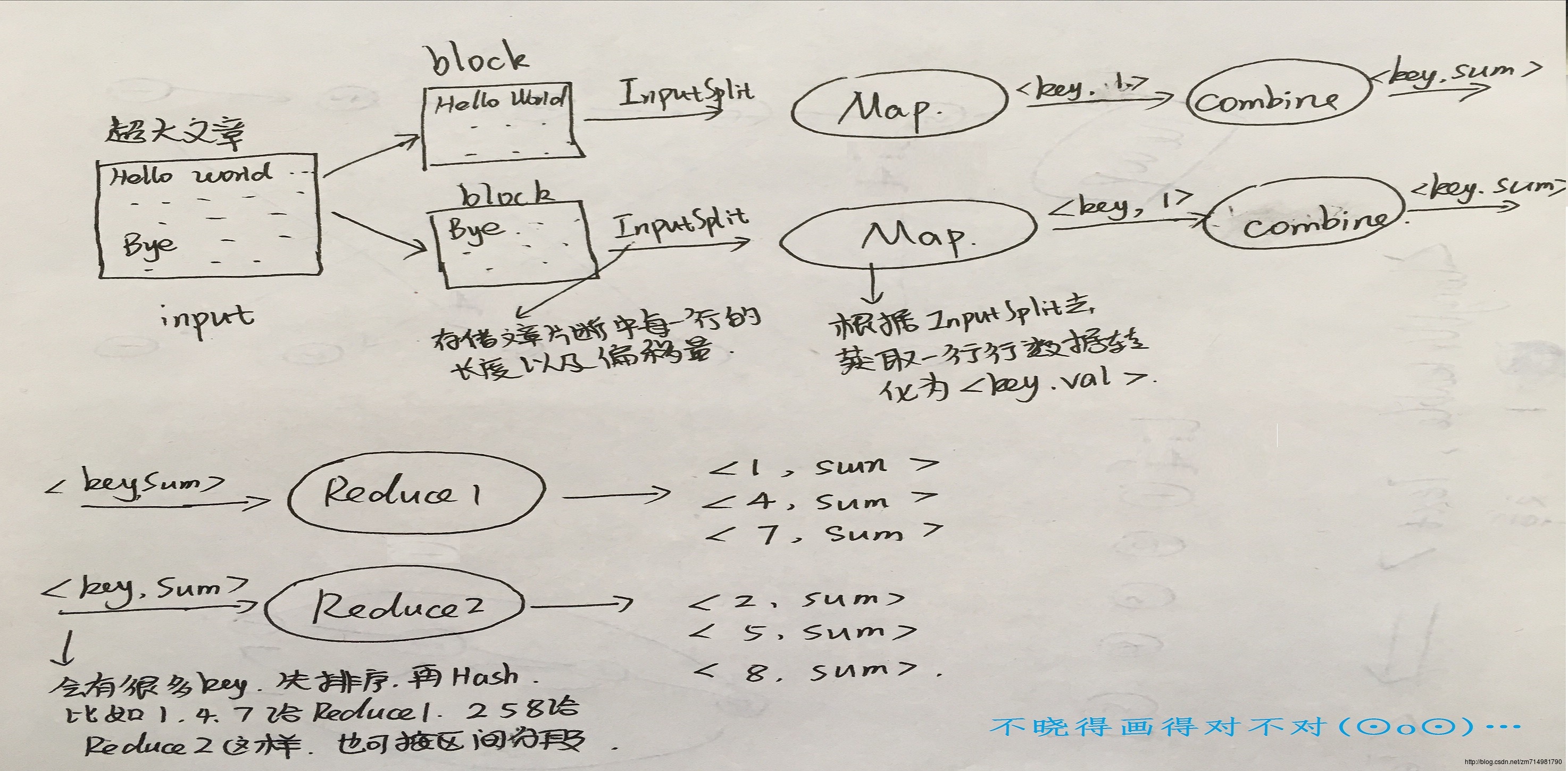
InputSplit是Hadoop中用来把输入数据传送给每个单独的Map,InputSplit存储的并非是数据本身,而是一个分片长度和一个记录数据位置的数组。当数据传送给map时,map会将输入分片传送到InputFormat,InputFormat则调用方法getRecordReader()生成RecordReader,RecordReader再通过creatKey()、creatValue()方法创建可供map处理的
<key,value>对。简而言之,InputFormat()方法是用来生成可供map处理的<key,value>对的。Mapper处理的数据是由InputFormat分解过的数据集,其中InputFormat的作用是将数据集切割成小数据集InputSplit,每一个InputSplit将由一个Mapper负责处理。此外,InputFormat的默认值是TextInputFormat,它针对文本文件,按行将文本切割成InputSplit,并用LineRecodeReader将InputSplit解析成
<key,value>对,key是行在文本中的位置(偏移量),value是文件中的一行。
假设我们输入的文件有两个file1,file2.因为文件太小假设一个文件一个block。然后两个block分给两个map任务去执行,每个block包含一个文件的所有内容,hadoop会在处理每个block后将其作为一个InputSplit。InputSplit存储的是一个分片长度和一个记录数据位置的数组。然后MR会去读取InputSplit中记录的分片信息生成标准的输入键值对:将文件的每一行作为一个value,而key是这一行在文件中的偏移量,比如上图中Hello Hadoop为一行其偏移量是0,那么形成
<0,"Hello Hadoop">这样一个标准的map输入。map任务的中间结果是存储在本地磁盘上的,而不是在HDFS中,因为传输到HDFS中会降低MapReduce任务的执行效率,并且在Job执行完毕后即可删除。
同时需要注意当有n个reduce任务时会产生n个输出文件,每个reduce会搜集一个或者多个key值。没有reduce任务时系统会直接将map的输出结果作为最终结果。
MapReduce任务优化
任务调度
计算方面:Hadoop总会优先将任务分配给空闲的机器,使得所有任务能公平的分享系统资源。
I/O方面:Hadoop会尽量将Map任务分配给InputSplit所在的机器,以减少网络I/O的消耗。数据预处理与InputSplit的大小
在处理大量小数据时,先对数据进行合。也可以参考Map任务的运行时间,当一个Map任务只需要运行几秒就结束时,可以考虑是否给它分配更多的数据,通常一个Map任务的执行时间在一分钟左右比较合适。在FileInputFormat中hadoop会在处理每个block后将其作为一个InputSplit,因此合理设置block的大小是很重要的调节方式,除此之外也可以设置Map任务的数量来调节Map任务的数据输入。Map和Reduce任务的数量
Map/Reduce任务槽:是这个集群中能够同时运行Map/Reduce任务的最大数量。比如10台机器的集群,设置每台机器最多可同时运行5个Map任务和3个Reduce任务,那么这个集群的Map/Reduce任务槽就是50/30.设置Map任务的数量主要是参考map的运行时间,设置Reduce的数量参考Reduce的任务槽。一般Reduce的数量是任务槽的0.95或者1.75倍,设置0.95时一个Reduce任务失败时可以很快的找到另一个空闲的机器重新执行,设置为1.75时运行较快的机器可以获得更多的Reduce任务,使得负载均衡。Combine函数
用于本地数据合并。每个Map任务可能会产生千万个<the,1>记录,若一一传给reduce任务是很耗时的,在WordCount程序中,合并程序和Reduce程序所做的事情一样,都是将n个<the,1>合并为一个<the,n>.压缩
可以选择对Map的输出和最终的输出结果进行压缩,减少网络上的数据传输量,虽然压缩会减少写入HDFS的时间,但是会增大读取HDFS的时间,因此根据实际情况来选择取舍。自定义comparator
在Hadoop中可以自定义数据类型来实现更复杂的目的,比如k-means算法中定义k个整数的集合,此时也要自定义comparator函数实现对象的比较。
Hadoop流的工作原理
当一个可执行文件作为Mapper时,每一个Map任务会以一个独立的进程启动这个可执行文件,然后在Map任务运行时,会把输入切分成行提供给供给可执行文件,并作为它的标准输入内容。当可执行文件运行出结果时,Map从标准输出中收集数据,并将其转化为
<key,value>对,作为Map的输出。

Reduce与Map相同,如果可执行文件做Reducer时,Reduce任务会启动这个可执行文件,并将<key,value>对转化为行作为这个可执行文件的标准输入,然后Reduce会收集这个可执行文件的标准输出的内容,并把每一行转化为<key,value>对,作为Reduce的输出。
- Map和Reduce中将输出转化为
<key,value>对的默认方式时:将每行的第一个tab符号之前的内容作为key,之后的内容作为value.如果没有tab符号,那么这一行的所有内容回座位key,而value为null,当然这是可以更改的。
以上是关于Hadoop——WordCount运行和解读的主要内容,如果未能解决你的问题,请参考以下文章