eclipse远程连接hadoop-2.6.0
Posted owen-li
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了eclipse远程连接hadoop-2.6.0相关的知识,希望对你有一定的参考价值。
1:准备工作;
工具: hadoop2-6.0 tar包 eclipse 连接hadoop的eclipse插件:hadoop-eclipse-plugin-2.6.0 可以自行到官网下载,此处提供三者下载链接。 百度云盘下载: 链接:http://pan.baidu.com/s/1dFGIeXz 密码:j8sh2:下载hadoop2.6和eclipse解压到自己电脑硬盘。
3:把hadoop-eclipse-plugin-2.6.0插件放到eclipse的plugins目录。
4:配置hadoop环境变量;
右击计算机在系统高级属性中配置环境变量。
配置Path(把hadoop的bin目录放到path目录,让系统可以运行bin下面的命令)

验证:在dos窗口敲命名hdfs可以看到如下结果及环境变量配置成功。
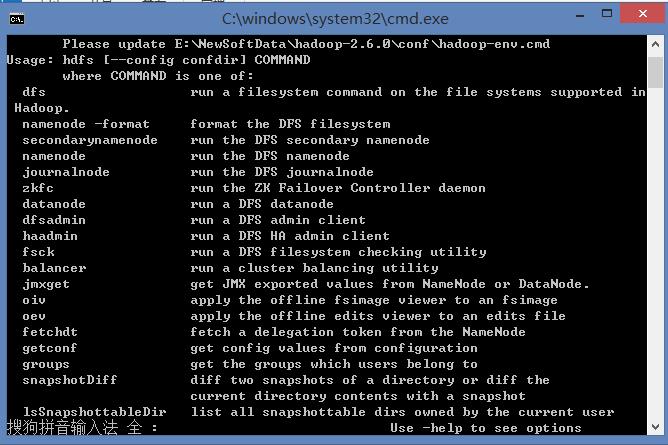
5:配置eclipse:
打开eclipse,windows->perference,选择Hadoop Map/Reduce,选择你解压hadoop-2.6.0的路径,保存。如图:

5.1:在eclipse显示hadoop标志大象:
操作: window->show view->other->MapReduce Tools->点击Map/Reduce Location。
5.2:接下来配置hadoop位置:
点击小象添加一个连接。(如图)
配置hadoop集群连接位置:
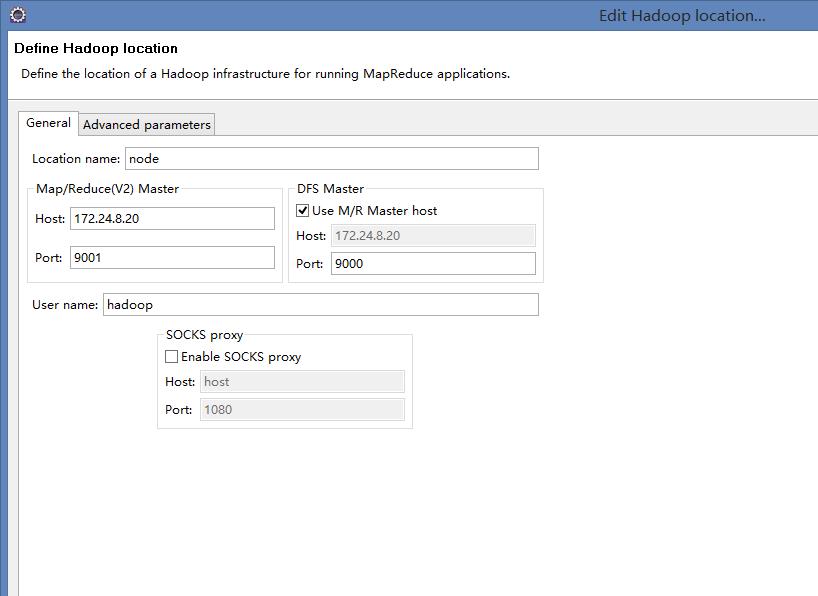
注意:Location name随意填写,Host是你的集群中master的ip端口号是你在配置文件中配置的端口号。配置好后,你就可以看见你的hdfs文件系统。

6:新建你的hadoop项目。
新建project,建立Map/Reduce Project。接下来就和编写java一毛一样操作了。此时我们可以跑一个wordcount示例来测试一下下。 在src目录下面新建一个class取名为WordCount;粘贴以下代码。
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class WordCount
public static class WordCountMap extends
Mapper<LongWritable, Text, Text, IntWritable>
private final IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException
String line = value.toString();
StringTokenizer token = new StringTokenizer(line);
while (token.hasMoreTokens())
word.set(token.nextToken());
context.write(word, one);
public static class WordCountReduce extends
Reducer<Text, IntWritable, Text, IntWritable>
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException
int sum = 0;
for (IntWritable val : values)
sum += val.get();
context.write(key, new IntWritable(sum));
public static void main(String[] args) throws Exception
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(WordCount.class);
job.setJobName("wordcount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(WordCountMap.class);
job.setReducerClass(WordCountReduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path("hdfs://172.24.8.20:9000/data"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://172.24.8.20:9000/output"));
job.waitForCompletion(true);
温馨提醒:为了以防空指针等一些莫名其妙的的错误在此处需要把你的hadoop的配置文件里面的core-site.xml、hdfs-site.xml和log4j.properties复制过来放在你的 src目录下。然后在开始运行你的程序了。在此处我们准备做测试的文件放在集群根目录下的data下。所需需要在你的hdfs文件系统的根目录创建data文件夹,并上传你要的测试文件。
hadoop fs -mkdir /datahadoop fs -put ./file*.txt /data以上是关于eclipse远程连接hadoop-2.6.0的主要内容,如果未能解决你的问题,请参考以下文章