Spark中文手册4:Spark之基本概念
Posted wanmeilingdu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark中文手册4:Spark之基本概念相关的知识,希望对你有一定的参考价值。
转自:http://www.aboutyun.com/thread-11516-1-1.html
问题导读
1、什么是DStream转换?2、什么是窗口计算?
3、怎样最有效的将发生数据到外部系统?

DStream中的转换(transformation) 和RDD类似,transformation允许从输入DStream来的数据被修改。DStreams支持很多在RDD中可用的transformation算子。一些常用的算子如下所示:
UpdateStateByKey操作 updateStateByKey操作允许不断用新信息更新它的同时保持任意状态。你需要通过两步来使用它
- 定义状态-状态可以是任何的数据类型
- 定义状态更新函数-怎样利用更新前的状态和从输入流里面获取的新值更新状态
- def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] =
- val newCount = ... // add the new values with the previous running count to get the new count
- Some(newCount)
这个函数被用到了DStream包含的单词上
- import org.apache.spark._
- import org.apache.spark.streaming._
- import org.apache.spark.streaming.StreamingContext._
- // Create a local StreamingContext with two working thread and batch interval of 1 second
- val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
- val ssc = new StreamingContext(conf, Seconds(1))
- // Create a DStream that will connect to hostname:port, like localhost:9999
- val lines = ssc.socketTextStream("localhost", 9999)
- // Split each line into words
- val words = lines.flatMap(_.split(" "))
- // Count each word in each batch
- val pairs = words.map(word => (word, 1))
- val runningCounts = pairs.updateStateByKey[Int](updateFunction _)
更新函数将会被每个单词调用,newValues拥有一系列的1(从 (词, 1)对而来),runningCount拥有之前的次数。要看完整的代码,见 例子 Transform操作 transform操作(以及它的变化形式如transformWith)允许在DStream运行任何RDD-to-RDD函数。它能够被用来应用任何没在DStream API中提供的RDD操作(It can be used to apply any RDD operation that is not exposed in theDStream API)。 例如,连接数据流中的每个批(batch)和另外一个数据集的功能并没有在DStream API中提供,然而你可以简单的利用transform方法做到。如果你想通过连接带有预先计算的垃圾邮件信息的输入数据流 来清理实时数据,然后过了它们,你可以按如下方法来做:
- val spamInfoRDD = ssc.sparkContext.newAPIHadoopRDD(...) // RDD containing spam information
-
- val cleanedDStream = wordCounts.transform(rdd =>
- rdd.join(spamInfoRDD).filter(...) // join data stream with spam information to do data cleaning
- ...
- )
事实上,你也可以在transform方法中用 机器学习和 图计算算法
窗口(window)操作 Spark Streaming也支持窗口计算,它允许你在一个滑动窗口数据上应用transformation算子。下图阐明了这个滑动窗口。
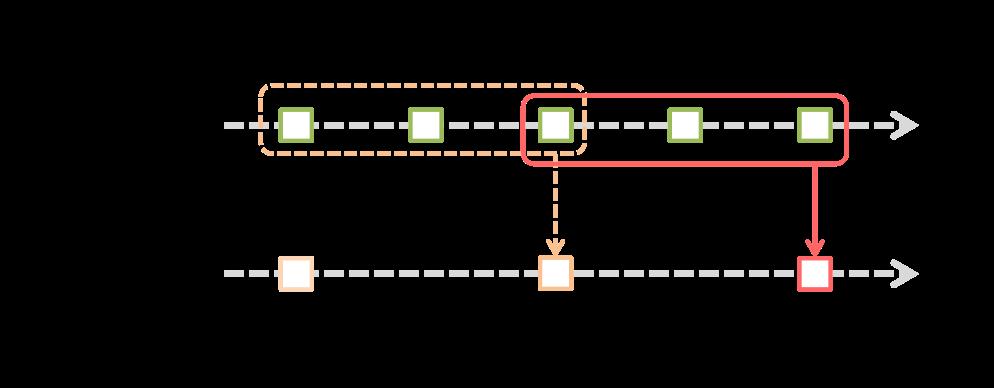
如上图显示,窗口在源DStream上滑动,合并和操作落入窗内的源RDDs,产生窗口化的DStream的RDDs。在这个具体的例子中,程序在三个时间单元的数据上进行窗口操作,并且每两个时间单元滑动一次。 这说明,任何一个窗口操作都需要指定两个参数:
- 窗口长度:窗口的持续时间
- 滑动的时间间隔:窗口操作执行的时间间隔
这两个参数必须是源DStream的批时间间隔的倍数。 下面举例说明窗口操作。例如,你想扩展前面的 例子用来计算过去30秒的词频,间隔时间是10秒。为了达到这个目的,我们必须在过去30秒的pairs DStream上应用reduceByKey 操作。用方法reduceByKeyAndWindow实现。
- // Reduce last 30 seconds of data, every 10 seconds
- val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(30), Seconds(10))
一些常用的窗口操作如下所示,这些操作都需要用到上文提到的两个参数:窗口长度和滑动的时间间隔
DStreams上的输出操作 输出操作允许DStream的操作推到如数据库、文件系统等外部系统中。因为输出操作实际上是允许外部系统消费转换后的数据,它们触发的实际操作是DStream转换。目前,定义了下面几种输出操作:
利用foreachRDD的设计模式 dstream.foreachRDD是一个强大的原语,发送数据到外部系统中。然而,明白怎样正确地、有效地用这个原语是非常重要的。下面几点介绍了如何避免一般错误。
- 经常写数据到外部系统需要建一个连接对象(例如到远程服务器的TCP连接),用它发送数据到远程系统。为了达到这个目的,开发人员可能不经意的在Spark驱动中创建一个连接对象,但是在Spark worker中 尝试调用这个连接对象保存记录到RDD中,如下:
- dstream.foreachRDD(rdd =>
- val connection = createNewConnection() // executed at the driver
- rdd.foreach(record =>
- connection.send(record) // executed at the worker
- )
- )
这是不正确的,因为这需要先序列化连接对象,然后将它从driver发送到worker中。这样的连接对象在机器之间不能传送。它可能表现为序列化错误(连接对象不可序列化)或者初始化错误(连接对象应该 在worker中初始化)等等。正确的解决办法是在worker中创建连接对象。
- 然而,这会造成另外一个常见的错误-为每一个记录创建了一个连接对象。例如:
- dstream.foreachRDD(rdd =>
- rdd.foreach(record =>
- val connection = createNewConnection()
- connection.send(record)
- connection.close()
- )
- )
通常,创建一个连接对象有资源和时间的开支。因此,为每个记录创建和销毁连接对象会导致非常高的开支,明显的减少系统的整体吞吐量。一个更好的解决办法是利用rdd.foreachPartition方法。 为RDD的partition创建一个连接对象,用这个两件对象发送partition中的所有记录。
- dstream.foreachRDD(rdd =>
- rdd.foreachPartition(partitionOfRecords =>
- val connection = createNewConnection()
- partitionOfRecords.foreach(record => connection.send(record))
- connection.close()
- )
- )
这就将连接对象的创建开销分摊到了partition的所有记录上了。
- 最后,可以通过在多个RDD或者批数据间重用连接对象做更进一步的优化。开发者可以保有一个静态的连接对象池,重复使用池中的对象将多批次的RDD推送到外部系统,以进一步节省开支。
- dstream.foreachRDD(rdd =>
- rdd.foreachPartition(partitionOfRecords =>
- // ConnectionPool is a static, lazily initialized pool of connections
- val connection = ConnectionPool.getConnection()
- partitionOfRecords.foreach(record => connection.send(record))
- ConnectionPool.returnConnection(connection) // return to the pool for future reuse
- )
- )
需要注意的是,池中的连接对象应该根据需要延迟创建,并且在空闲一段时间后自动超时。这样就获取了最有效的方式发生数据到外部系统。 其它需要注意的地方:
- 输出操作通过懒执行的方式操作DStreams,正如RDD action通过懒执行的方式操作RDD。具体地看,RDD actions和DStreams输出操作接收数据的处理。因此,如果你的应用程序没有任何输出操作或者 用于输出操作dstream.foreachRDD(),但是没有任何RDD action操作在dstream.foreachRDD()里面,那么什么也不会执行。系统仅仅会接收输入,然后丢弃它们。
- 默认情况下,DStreams输出操作是分时执行的,它们按照应用程序的定义顺序按序执行。
以上是关于Spark中文手册4:Spark之基本概念的主要内容,如果未能解决你的问题,请参考以下文章