[GCPNet]Scene Parsing with Global Context Embedding
Posted 明天去哪
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[GCPNet]Scene Parsing with Global Context Embedding相关的知识,希望对你有一定的参考价值。
Abstract
加州大学美熹德分校发表在ICCV 2017上的工作.
本文利用全局信息进行场景解析。训练基于场景相似度的网络来产生一张图片的全局信息特征关系,然后利用该信息产生全局和空间的先验知识。最后将这些先验知识作为全局上下文线索结合到分割网络中。实验辨明这种做法可以较少与全局信息相悖的假正例,最后在MIT ADE20k和PASCAL Context上达到了不错的性能.
本文的主要贡献有三点:(1)设计一种Siamese network来学习全局信息表示(2)提出两种方法基于特征学习和非参数先验编码的形式来利用全局信息(3)结合分割网络、上下文特征编码和非参数先验编码提出全局特征嵌入模式来高校进行场景解析.
Motivation

目前的网络大多只考虑局部特征,并不能为网络提供足够的全局线索,导致不能很好地场景中的某一块具体属于什么类别。如图所示。
以前的一些做法是使用MRF, CRF或者全局信息等进行处理,还有一些非参数化的方法,通过对图片进行相似性的检索,将被检索图片的信息对最终结果的头片,但是这中方法往往基于手工构建的特征进行检索。
本文考虑使用深度学习的方法产生这些非参数先验信息,并结合到网络中提高结果。
Framework
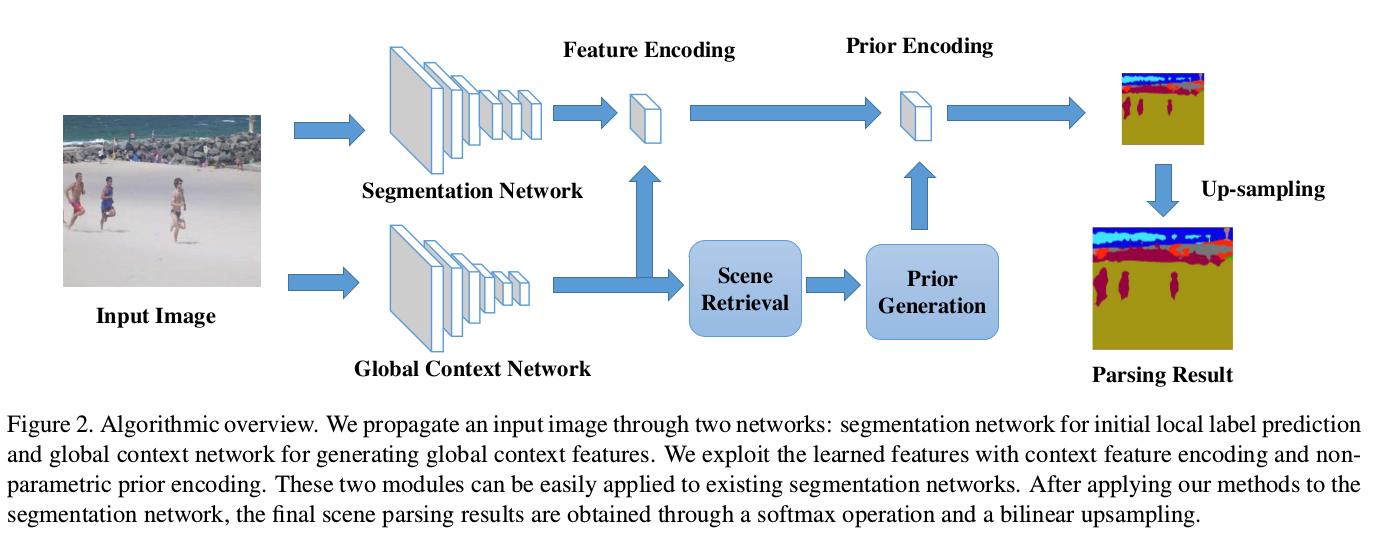
全局上下文信息提取网络
网络结构如下:
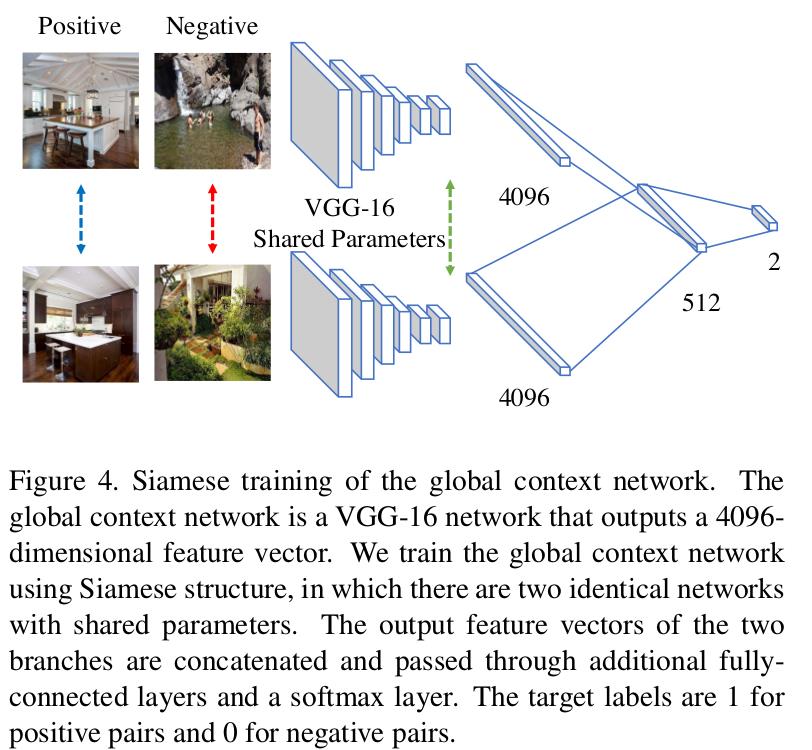
利用ground truth distance来定义两张图片是否相似.为了计算gt distance,先对groundtruth生成空间金字塔,然后对两张图片香味块的标签的直方图计算卡方距离.

图片中hi(s, c)是指在空间金字塔s的位置,像素属于类别c的数量.i和j表示第i张和第j张图.
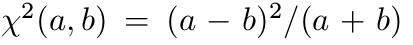
由于有的类别出现的次数比较少,不平衡的样本可能导致训练结果向忽略少样本倾斜,因此需要进行加权处理.
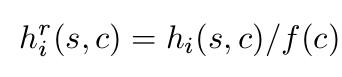
f(c)指在整个数据集中类别c存在的图片的总数量.
加权之后,利用KNN产生相似图片和不相似图片对(即Siamese Network的ground truth),进行后续训练.产生非参数化的先验
使用上述产生的全局信息,利用KNN进行检索,对于检索到的图片,考虑到通常情况下不仅要考虑一个物体是否存在与图片中,还要考虑一张物体在图片中的每个位置的可能性.因此产生两种先验——全局先验和空间先验.
空间先验 的求解过程:
先将被检索到的图片resize到SXS.然后计算:
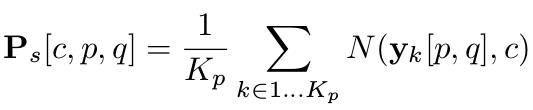
其中Kp表示被检索到的图片总数,yk表示第k张图片,yk[p,q]是坐标为[p,q]的像素,N(yk[p,q], c)在[p,q]位置是否被标记为类别c,Ps表示平均可能性。容易知道Ps的维度为CxSxS.
全局先验 的求解过程:
利用空间位置不变形,仅考虑物体是否存在.
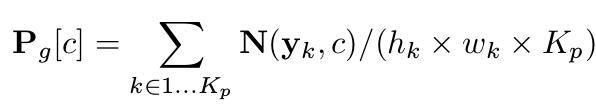
其中,N(yk, c)表示第k张被检索到的图片中类别为c的像素的个数. Pg的维度为1x1xC
- 全局上下文信息和非参数化的先验与分割网络相结合.
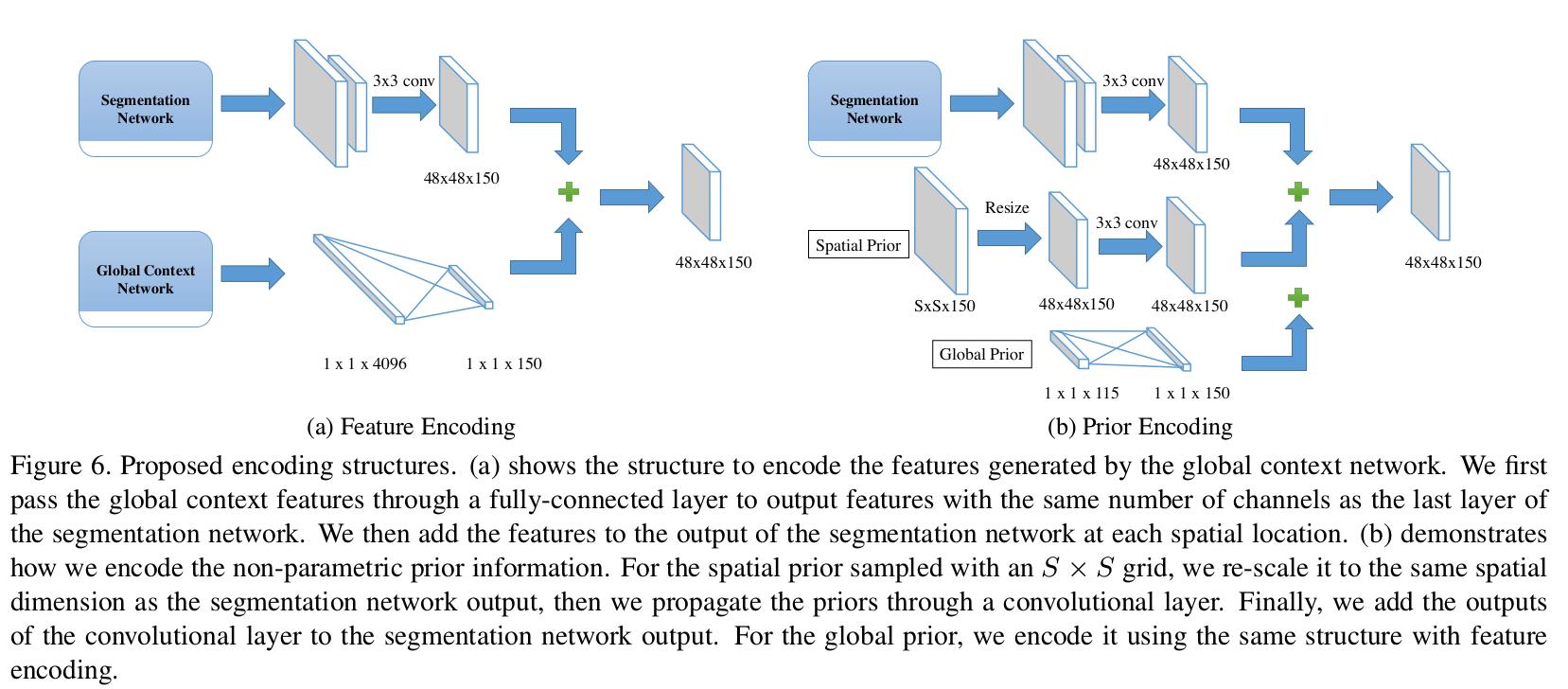
这一部分图下已经解释很清楚了…
Result
本文采用基于Fcn-VGG16-8s和DeepLab-ResNet101.设置Crop size.


Code
Code: https://github.com/hfslyc/GCPNet
Thinking
和我之前的一个想法类似,有借鉴意义,但是从效果看来,提升并不明显.没有在主流数据集PASCAL VOC2012和Cityscapes上的结果.
以上是关于[GCPNet]Scene Parsing with Global Context Embedding的主要内容,如果未能解决你的问题,请参考以下文章