Hadoop 2.x伪分布式环境搭建测试
Posted 正义飞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop 2.x伪分布式环境搭建测试相关的知识,希望对你有一定的参考价值。
Hadoop 2.x伪分布式环境搭建测试
标签(空格分隔): hadoop
hadoop,spark,kafka交流群:224209501
1,搭建hadoop所需环境
卸载open JDK
rpm -qa |grep java
rpm -e –nodeps [java]
1.1,在/opt/目录下创建四个目录:
modules/
software/
datas/
tools/
解压hadoop-2.5.0及jdk-7u67-linux-x64.tar.gz至modules目录下。
$tar -zxvf hadoop-2.5.0.tar.gz /opt/modules/
$tar -zxvf jdk-7u67-linux-x64.tar.gz /opt/modules/1.2添加java环境变量。
$sudo vi /etc/profile
添加环境变量:
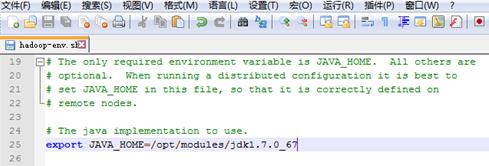
export JAVA_HOME=/opt/modules/jdk1.7.0_67
export PATH=$PATH:$JAVA_HOME/bin
更新配置:
#source etc/profile设置nodepad++与hadoop所在主机链接,以便修改配置。
2,hadoop伪分布式设置
1,添加java指令目录到hadoop-env.sh,yarn-env.sh,mepre-env.sh


2,core-site.xml配置
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-2.6.0-cdh5.4.4/data/tmp
</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://adddeiMac.local:8020</value>
</property>3,hdfs-site.xml配置
<property>
<name>dfs.replication</name>
<value>1</value>
</property>4,mapred-site.xml配置
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>5,yarn-site.xml配置
<property>
<name>yarn.resourcemanager.hostname</name>
<value>adddeiMac.local</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>6,slaves配置
miaodonghua.host//主机名:nodemanager和datanode地址3,启动hadoop。
1,格式化文件系统
$bin/hdfs namenode -format
2,启动hdfs
$sbin/hadoop-daemon.sh start namenode
$sbin/hadoop-daemon.sh start datanode3,创建目录、上传文件并查看文件内容
$bin/hdfs dfs -mkdir /usr/hadoop/tmp
$bin/hdfs dfs -put etc/slaves /usr/hadoop/tmp上传成功后可以在web端口查看:
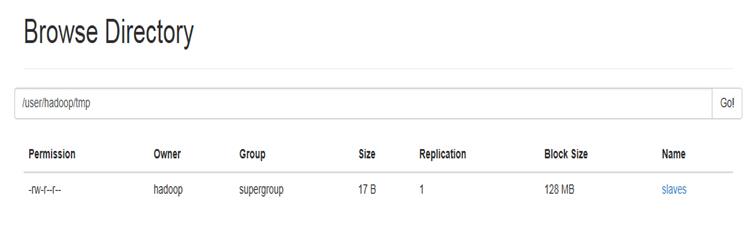
查看slaves内容
$bin/hdfs dfs -cat /usr/hadoop/tmp/slaves
启动yarn
$sbin/yarn-daemon.sh start resourcemanager
$sbin/yarn-daemon.sh start nodemanager启动hdfs和yarn成功后,jps:
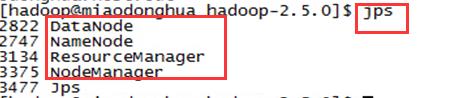
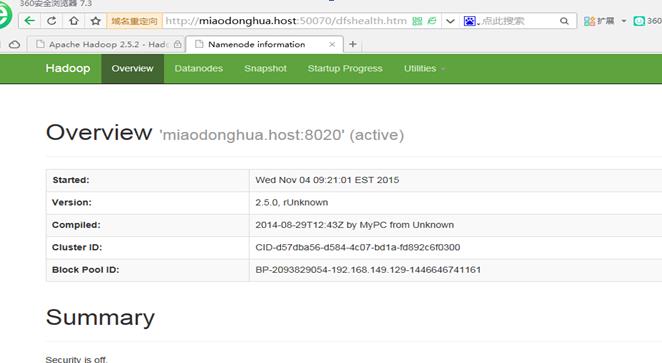
查看namnode和Resourcemanager的webapp

4,在yarn上运行wordcount
1,创建wordcount的输入文件
vi /opt/datas/wc.input
内容:
yarn spark
hadoop mapreduce
mapreduce spark
hdfs yarn
yarn mapreduce
hadoop hdfs
spark spark2,创建目录,并上传wc.input
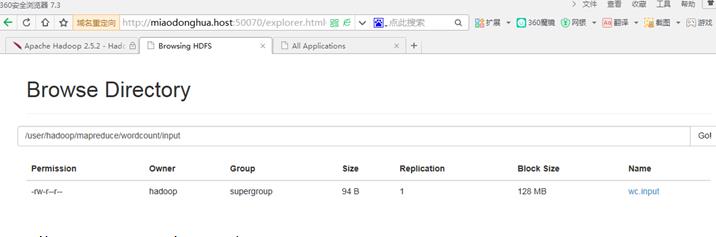
$bin/hdfs dfs -mkdir -p /usr/hadoop/mapreduce/wordcount/input
$bin/hdfs dfs -put /opt/datas/wc.input mapreduce/wordcount/input上传成功:
3,运行wordcount。

webapp查看运行状态
running
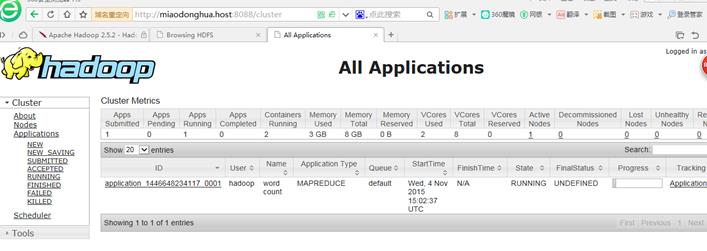
finished
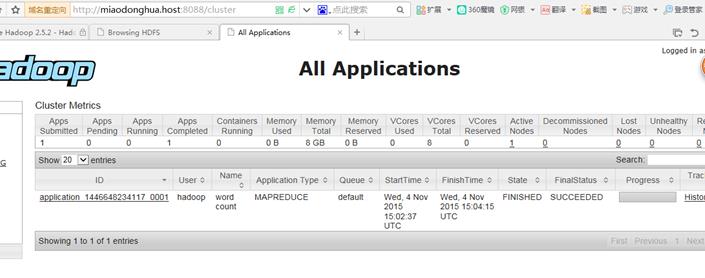
查看结果
在/user/hadoop/mapreduce/output目录下会生成结果文件

在终端中查看结果
$bin/hdfs dfs -text /user/hadoop/mapreduce/wordcount/output/par*
5,自己目前对hadoop组件的理解
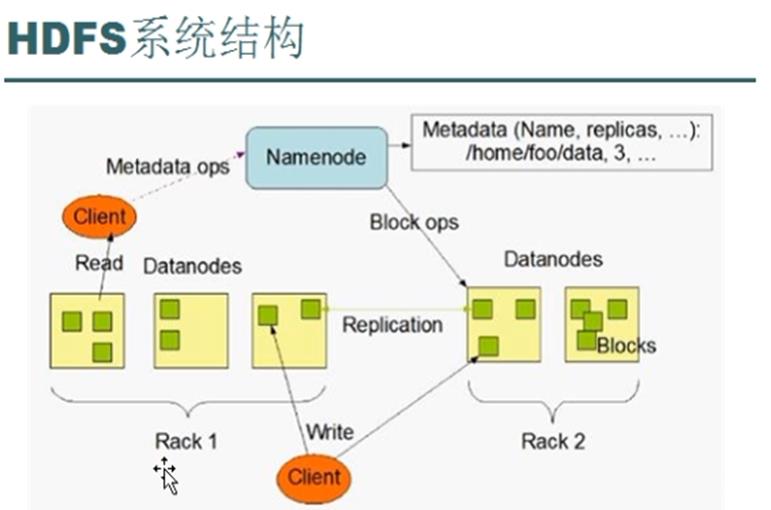
1,对HDFS的理解
Hdfs是一种适合运行在普通廉价服务器上的分布式文件系统,hdfs适合存储超大文件不适合存储小文件,而且hadoop中的文件被分成64M的块而且实际存储内容小于64M的话实际占有内存也不到64M。Hdfs有一个namenode、一个SecondaryNameNode和若干datanode。Namenode用来存储文件的元数据如文件名,文件目录结构,文件属性以及每个文件的块和块所在的datanode等。Datanode在本地文件系统存储文件数据块,以及块数据的校验和。SecondaryNameNode用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
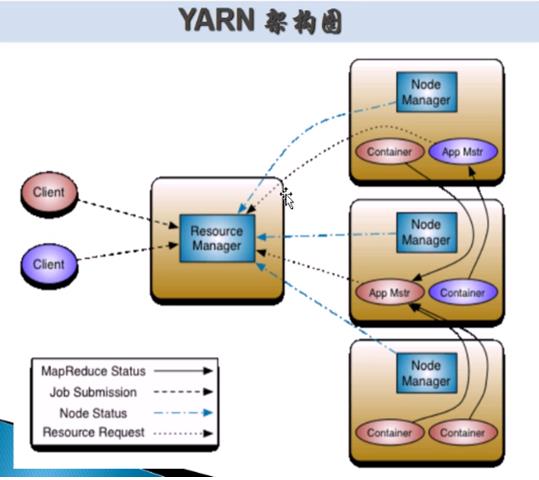
2,对YARN的理解
Yarn是一种新的 Hadoop资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。yarn服务主要由四个部分组成Resopurcemanager、nodemanager、applicationmaster及container。Rsourcemanager主要负责处理客户端请求、启动及监控AllicationMaster监控NodeManager及资源分配及调度。nodeManager主要负责处理来自ResourceManager及来自AllicationMaster的命令,还负责单个节点上的资源管理。AllicationMaster主要负责数据切分,为应用程序申请资源并分配给内部任务,还负责任务监控与容错。Container主要是对任务运行环境的抽象,封装了CPU、内存等对位资源以及变量、启动命令等任务运行相关的信息。
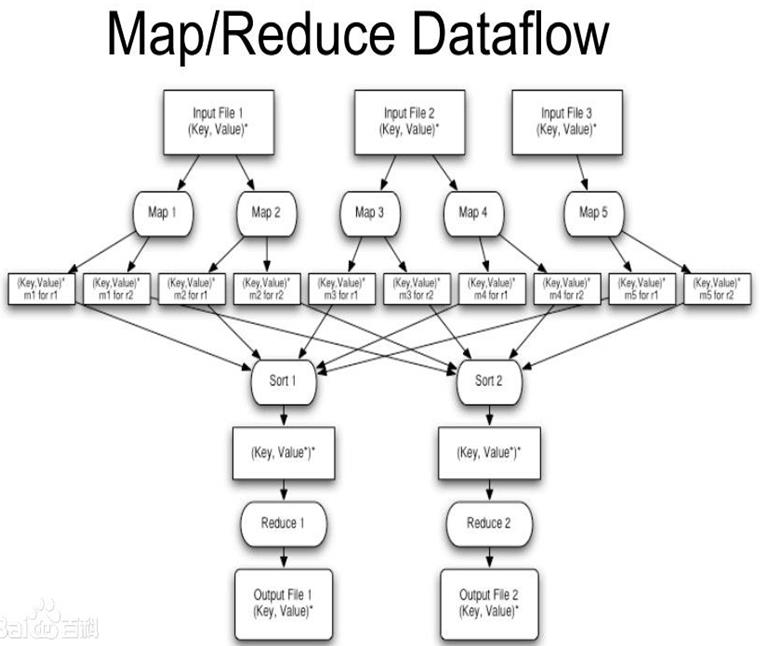
3,对mapreduce的理解
Mapreduce是一种离线框架。它适合大规模的数据运算,他将计算过程分为两个部分,及map和reduce。Map阶段主要进行并行的处理输入的数据,并将数据存储到本地磁盘。Reduce主要从磁盘上读出map阶段存储的数据,然后将map阶段的数据进行化简汇总。mapreduce是仅适合离线处理,并且具有很好的容错性及扩展性,适合处理简单的批处理人数。其缺点是启动开销大、过多的使用磁盘导致效率低下等。
Mapreduce具体执行步骤如下:
1.首先对输入数据源进行切片
2.master调度worker执行map任务
3.worker读取输入源片段
4.worker执行map任务,将任务输出保存在本地
5.master调度worker执行reduce任务,reduce worker读取map任务的输出文件
6.执行reduce任务,将任务输出保存到HDFS
下图是mapreduce的数据流向图.
以上是关于Hadoop 2.x伪分布式环境搭建测试的主要内容,如果未能解决你的问题,请参考以下文章