《ROS理论与实践》学习笔记机器视觉处理
Posted Sakurazzy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《ROS理论与实践》学习笔记机器视觉处理相关的知识,希望对你有一定的参考价值。
《ROS理论与实践》学习笔记(六)机器视觉处理
在学习《ROS理论与实践》课程时,记录了学习过程中的编程练习,课后作业以及发现的问题,后续会对尚未解决的问题继续分析并更新,纯小白,仅供参考。
本次学习笔记关于课程中的第七讲:机器视觉处理 。主要学习了ROS的USB摄像头启动、摄像头参数标定、OpenCV及Tensorflow案例的练习。
课程内容
1.ROS摄像头驱动及数据接口
usb摄像头功能包安装:
$ sudo apt-get install ros-melodic-usb-cam
启动usb摄像头并用rqt显示:
$ roslaunch usb_cam usb_cam-test.launch
$ rqt_image_view
usb摄像头具体数据接口见ROS Wiki:wiki usb_cam
在练习时发现了一些问题,与虚拟机的外设链接有关。
1.启动usb摄像头launch文件时出现如下警告:
[ERROR] Cannot identify '/dev/video0': 2, No such file or directory
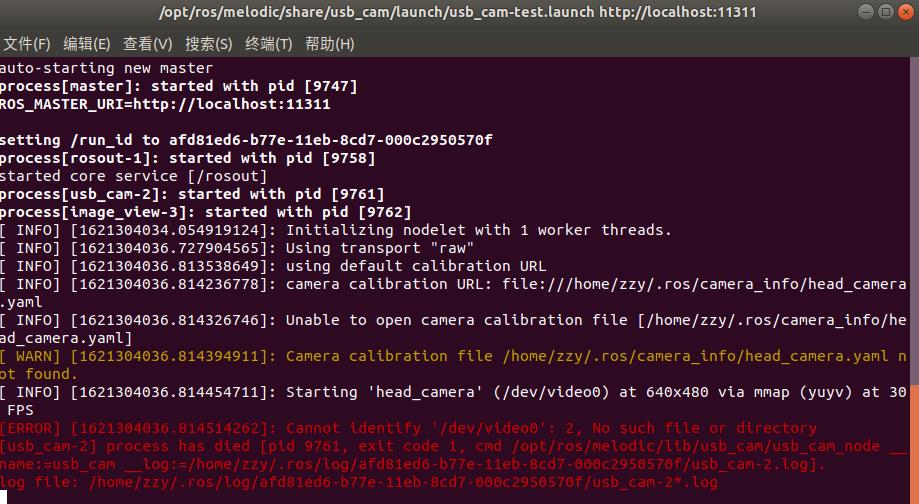
解决方法:在虚拟机设置中勾上显示所有USB输入设备,重启后连接usb摄像头。
具体过程见博客:无法打开USB摄像头
2.如上成功连接摄像头后,启动launch文件又出现如下警告:
[ERROR] [1621304764.757189189]: select timeout
 解决方法:在1的基础上,将虚拟机的USB兼容性改为3.0即可
解决方法:在1的基础上,将虚拟机的USB兼容性改为3.0即可
2.摄像头参数标定
安装calibration参数标定功能包:
$sudo apt-get install ros-melodic-camera-calibration
启动launch文件:
$ roslaunch robot_vision usb_cam.launch
$ rosrun camera_calibration cameracalibrator.py --size 8x6 --square 0.024 image:=/usb_cam/image_raw camera:=/usb_cam
其中size表示标定棋盘的内部角点个数,square表示每个棋盘格的边长,image和camera为设置摄像头发布的图像话题。
将标定靶进行平移和旋转直到X/Y/Size/Skew进度条均变为绿色后,点击CALIBRATE,存储得到如下的标定文件:

3.ROS+OpenCV图像处理方法及案例
ROS OpenCV功能包安装:
$ sudo apt-get install ros-melodic-vision-opencv libopencv-dev python-opencv
主要的API:
- imgmsg_to_cv2() : 将ROS图像消息转换成OpenCV图像数据
- cv2_to_imgmsg() : 将OpenCV格式的图像数据转换成ROS图像消息
- 输入参数:图像信息流;转换的图像数据格式
人脸识别案例流程:
- 初始化:完成ROS节点、图像、识别参数的设置
- 回调函数:将图像转换成OpenCV的数据格式,然后预处理之后开始调用人脸识别的功能函数,最后把识别结果发布
- 人脸识别: 调用OpenCV提供的人脸识别接口,与数据库中的人脸特征进行匹配
$ roslaunch robot_vision usb_cam.launch
$ roslaunch robot_vision face_dector.launch
$ rqt_image_view
跟踪物体特征点案例流程:
- 初始化: 完成ROS节点、图像、识别参数的设置
- 将图像转换成OpenCV格式,完成图像预处理之后开始针对两帧图像进行比较,基于图像差异识别到运动的物体,最后标识结果并发布
$ roslaunch robot_vision usb_cam.launch
$ roslaunch robot_vision motion_dector.launch
$ rqt_image_view
4.ROS+Tensorflow物体识别方法及案例
tensorflow安装:
$ sudo apt-get install python-pip python-dev python-virtualenv
$ virtualenv --system-site-packages ~/tensorflow
$ source ~/tensorflow/bin/activate
$ easy_install -U pip
$ pip install --upgrade tensorflow
剩余代码来自课程代码包,含有物体识别案例
$ roslaunch tensorflow_object_detector usb_cam_detector.launch
本讲作业
1.通过人脸识别方式,发布速度控制指令,控制仿真机器人运动
任务要求:小车根据人脸左右移动方向进行旋转,根据人脸前后移动方向进行移动
实现思路:通过人脸识别例程计算得到人脸的二维坐标点以及人脸大小,对应地写入Twist消息变量,并创建一个发布者vel_pub,向/cmd_vel话题发布Twist速度指令。
为了便于测试,自定义了一个msg消息类型facepos,并通过faceps_pub发布者,向/faceposition话题实时发布人脸位置和大小,其数据结构如下:
uint16 posx
uint16 posy
uint16 facesize
部分代码实现如下:
- 创建face_pub和vel_pub发布者
# 创建人脸位置话题faceposition,消息类型为自定义类型facepos
self.facepos_pub = rospy.Publisher("faceposition",facepos,queue_size=10)
# 创建一个Publisher,发布名为/cmd_vel的topic,消息类型为geometry_msgs::Twist,队列长度10
self.vel_pub = rospy.Publisher('/cmd_vel',Twist,queue_size=10)
- 将人脸数据和速度指令封装到facepos和Twist消息类型
# 将人脸位置信息封装到消息类型facepos中
# 将速度发布指令封装到消息类型Twist中
facepos_data = facepos()
vel_msg = Twist()
# 在opencv的窗口中框出所有人脸区域
if len(faces_result)>0:
for face in faces_result:
x, y, w, h = face
facepos_data.posx = x+w/2
facepos_data.posy = y+h/2
facepos_data.facesize = w*h
cv2.rectangle(cv_image, (x, y), (x+w, y+h), self.color, 2)
# 当人脸偏左,则围绕z轴以0.2速度旋转,反之围绕z轴以-0.2速度旋转
if facepos_data.posx == 0:
vel_msg.angular.z = 0
elif facepos_data.posx > 400:
vel_msg.angular.z = 0.2
else:
vel_msg.angular.z = -0.2
# 当人脸尺寸大于30000(靠前)则前进,反之则后退
if facepos_data.facesize == 0:
vel_msg.linear.x = 0
elif facepos_data.facesize > 30000:
vel_msg.linear.x = 0.5
else:
vel_msg.linear.x = -0.5
- 发布指令
# 发布速度指令
self.vel_pub.publish(vel_msg)
# 将识别后的图像转换成ROS消息并发布
self.image_pub.publish(self.bridge.cv2_to_imgmsg(cv_image, "bgr8"))
# 发布人脸位置信息
self.facepos_pub.publish(facepos_data)
测试结果
可以通过echo相关的话题对程序进行测试:
$ topic echo /cmd_vel
$ topic echo /faceposition
得到结果如下图所示:
 运行Gazebo仿真程序,确实能够实现人脸识别对小车的控制,但是对于戴眼镜的人脸会有严重的跳变,人脸坐标频繁跳变为0,在实际应用中可以再加入跳变检测,并做一些滤波处理。
运行Gazebo仿真程序,确实能够实现人脸识别对小车的控制,但是对于戴眼镜的人脸会有严重的跳变,人脸坐标频繁跳变为0,在实际应用中可以再加入跳变检测,并做一些滤波处理。
2.使用杯子识别发布速度控制指令,控制仿真机器人的运动
实现方法与第一题类似,后续更新。
ps.无法正常import自定义msg消息
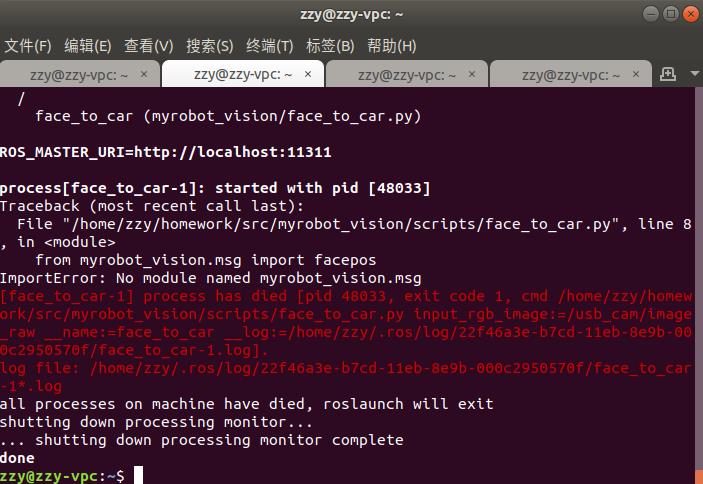
在完成作业第一题时,在myrobot_vision功能包下创建msg文件夹,并建立了自定义msg消息facepos,用于发布人脸的实时坐标和尺寸,同第三讲的内容,对CMakeLists.txt和package.xml文件进行了修改,并使用如下代码进行import:
from myrobot_vision.msg import facepos
在运行代码时出现如下报错提示:
ImportError: No module named myrobot_vision.msg
 但是在学习时使用的learning_communication功能包下的msg文件夹中,同样建立facepos.msg消息,进行如下的import,代码能够运行成功:
但是在学习时使用的learning_communication功能包下的msg文件夹中,同样建立facepos.msg消息,进行如下的import,代码能够运行成功:
from learning_communication.msg import facepos
解决方法:重启一下就好了…?可能是需要手动source一下?
结语
本讲学习了ROS的USB摄像头启动、摄像头参数标定、OpenCV及Tensorflow案例,通过作业巩固了话题通信以及本讲的视觉内容,做了一定的拓展。主要遇到的问题是自定义msg消息的导入,花费了很多的时间检查,最后也不知道怎么解决的…重启一下就好了。
以上是关于《ROS理论与实践》学习笔记机器视觉处理的主要内容,如果未能解决你的问题,请参考以下文章