cv算法工程师学习成长路线
Posted 嵌入式视觉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了cv算法工程师学习成长路线相关的知识,希望对你有一定的参考价值。
- 前言
- 一,计算机系统
- 二,编程语言
- 三,数据结构与算法
- 四,机器学习
- 五,深度学习
- 5.3,经典CNN分析文章
- 六,计算机视觉
- 七,模型压缩与量化
- 八,高性能计算
- 九,模型部署(算法SDK开发)
- 博客阅读后的知识点总结
- 参考资料
文章同步发于 github 仓库和 csdn 博客,最新版以
github为主。如果看完文章有所收获,一定要先点赞后收藏。毕竟,赠人玫瑰,手有余香.
更多干货文章和面经,点击查看我的公众号-嵌入式视觉,扫码关注我的公众号!
{kind=link}
本文内容为 cv 算法工程师成长子路上的经典学习教材汇总,对于一些新兴领域则给出了较好的博客文章链接。本文列出的知识点目录是成系统且由浅至深的,可作为 cv 算法工程师的常备学习路线资料。部分学习资料存在离线 PDF 电子版,其可在 github仓库-cv_books 中下载。
前言
课程学习方法,三句话总结:
- 看授课视频形成概念,发现个人感兴趣方向。
- 读课程笔记理解细节,夯实工程实现的基础。
- 码课程作业实现算法,积累实验技巧与经验。
再引用一下学习金字塔的图:

图片来源
github仓库 DeepLearning Tutorial
关于科研和研发的思考,可参考文章-中国人民大学赵鑫:AI 科研入坑指南。
一,计算机系统
1.1,计算机系统书籍
- 《深入理解计算机系统第三版》: 网上有电子版,
PDF电子书下载方式在文章首页。
1.2,设计模式教程
- 设计模式: 内容很全,存在
C++示例代码。
二,编程语言
2.1,C++ 学习资料
- cpp reference:
C++库接口参考标准文档,官方文档,包含各个函数定义及使用example。 - http://www.cplusplus.com/reference/stl/
- Cpp Primer 学习: 《C++ Primer 中文版(第 5 版)》学习仓库,包括笔记和课后练习答案。
- C++ Tips of the Week: 谷歌出品的
C++编程技巧。
2.2,Python 学习资料
- 《廖雪峰-Python3教程》: 内容很全且通俗易懂,适合初学者,但代码示例不够丰富。描述的知识点有:
Python基础、函数、高级特性、函数式编程、模块、面向对象编程、面向对象高级编程、错误、调试和测试、IO编程、进程和线程、正则表达式、常用内建模块、常用第三方模块、图形界面、网络编程、异步IO等内容。电子书可在github仓库-cv_books 中下载。 - Python 工匠系列文章: 很适合深入理解
Python面向对象编程、装饰器、模块、异常处理等内容。
三,数据结构与算法
3.1,数据结构与算法课程
- 《图解算法》:存在
PDF电子版,内容较为基础且通俗易懂,适合快速了解数据结构与算法的基础知识,但深度不够,示例代码为Python。 - 专栏-数据结构与算法之美: 学习数据结构与算法的知识点课程,内容全且深度足够。官方例子为
java代码,同时github仓库提供C/C++/GO/Python等代码。
3.2,算法题解
- 《剑指Offer》面试题: Python实现: 题目为《剑指 Offer》书籍原题,代码实现为
Python,仓库简洁,阅读体验不错,无任何广告,适合刚学完数据结构与算法基础知识的同学。 - 力扣+±算法图解:
leetcode高频题图解,题解分析很多,部分题目有动画分析,提供Python/Java/C++实现,但也存在部分题解分析废话较多,不够精简的问题。 - 小浩算法: 一部图解算法题典,讲解
105道高频面试算法题目,go代码实现。 - LeetCode题解:
leetcode高频题题解,全书代码默认使用C++11语法编写,题解为文字性描述,题解分析较短且不够通俗易懂。本书的目标读者是准备去硅谷找工作的码农,也适用于在国内找工作的码农,以及刚接触ACM算法竞赛的新手。
四,机器学习
4.1,机器学习课程
- 《机器学习》-周志华(西瓜书):存在
PDF电子版,内容很全,很适合打下扎实的基础。 - 《李宏毅-机器学习课程》: 机器学习经典视频教程啊,非常适合初学者观看。
- 李宏毅机器学习笔记(LeeML-Notes): 可以在线阅读,很方便,内容完成度高。
- 《南瓜书PumpkinBook》: 南瓜书,是西瓜书的补充资料,包含了西瓜书的公式的详细推导,建议先看西瓜书,部分公式不会推导的情况下,可以查看南瓜书的对应内容。
- 机器学习数学基础

五,深度学习
5.1,深度学习课程
- 《深度学习》(花书),存在英文和中文
PDF电子版。 - 《李宏毅-深度学习课程》: 经典视频教程,提供了
PPT、代码资料。
5.2,深度学习基础文章
5.3,经典CNN分析文章
1,VGGNet 拥有 5 段 卷积,每一段有 2~3 个卷积层,同时每段尾部会连接一个最大池化层用来缩小图片尺寸,每段内的卷积核数量相同,越靠后的段的卷积核数量越多:64-128-256-512-512。ResNet 网络拥有 4 段卷积, 每段卷积代表一个 残差学习
Blocks,根据网络层数的不同, Blocks 的单元数量不同,例如 ResNet18 的 Blocks 单元数量分别为2、2、2 和 2。越靠后的段的卷积核数量越多:64-128-256-512,残差学习Blocks内的卷积核通道数是相同的。
2,ResNet v2 创新点在于通过理论分析和实验证明恒等映射对于残差块的重要性,根据激活函数与相加操作的位置关系,我们称之前的组合方式(ResNet)为“后激活(post-activation)”,现在新的组合方式(ResNet v2)称之为“预激活(pre-activation)”。使用预激活有两个方面的优点:1)
f变为恒等映射,使得网络更易于优化;2)使用BN作为预激活可以加强对模型的正则化。
5.5,PyTorch 框架学习
- PyTorch中文文档;PyTorch官方教程中文版;PyTorch 官方教程。
- PyTorch_tutorial_0.0.5_余霆嵩: 存在开源
PDF电子版,且提供较为清晰的代码,适合快速入门,教程目录结构清晰明了。
5.6,PyTorch/Caffe 框架分析
- pytorch自定义层如何实现?超简单!
- 【PyTorch】torch.nn.Module 源码分析
- 详解Pytorch中的网络构造,模型save和load,.pth权重文件解析
- 半小时学会 PyTorch Hook
- 详解Pytorch中的网络构造
- 深度学习与Pytorch入门实战(九)卷积神经网络&Batch Norm
- Pytorch 里 nn.AdaptiveAvgPool2d(output_size) 原理是什么?
- caffe源码解析-开篇
- 《Caffe官方教程中译本》:存在开源
PDF电子版。
六,计算机视觉
6.1,数字图像处理教程
- 《数字图像处理第四版》:存在开源
PDF电子版。成系统的介绍了数字图像的原理及应用,内容多且全、深度也足够,非常适合深入理解数学图像原理,可挑重点看。 - 桔子code-OpenCV-Python教程
6.2,计算机视觉基础课程
- 《CS231 课程》-李飞飞。b 站视频教程,CS231n官方笔记授权翻译总集。课程非常经典,内容深入浅出,每节课都有课后作业和对应学习笔记。
- 《动手学深度学习》-李沐,存在开源
PDF电子书,官方代码为MXNet框架,也存在PyTorch代码实现书籍。
6.3,深度学习模型和资源库
Papers with code是由Meta AI Research团队主导的一个开放资源的社区,汇集了深度学习论文、数据集、算法代码、模型以及评估表。Jetson Zoo,是一个开源目录,其中包含在NVIDIA Jetson硬件平台上开发指南以及参考案例分享汇总。模型库资源里包括图像分类、目标检测、语义分割和姿势估计等方向的实践分享,提供开源代码和开发指南文章的链接。Model Zoo包含了机器学习各领域的算法框架及预训练模型资源汇总,其中包括TensorFlow、PyTorch、Keras、Caffe等框架,作者是Jing Yu Koh构建。- MediaPipe 是一个为直播和流媒体提供跨平台、可定制的机器学习解决方案的框架。MediaPipe 提供了包括人脸检测、人脸网格、虹膜识别、手部关键点检测、人体姿态估计、人体+人脸+手部组合整体、头发分割、目标检测、Box 跟踪、即时运动追踪、3D 目标检测等解决方案。
Deci旨在使用AI构建更好的AI,使深度学习能够发挥其真正的潜力。借助该公司的端到端深度学习加速平台,人工智能开发人员可以为任何环境(包括云、边缘或移动)构建、优化和部署更快、更准确的模型。借助Deci的平台,开发人员可以在任何硬件上将深度学习模型推理性能提高3到15倍,同时仍然保持准确性。平台除了能够显示每个模型的准确性之外,还可以轻松选择目标推理硬件并查看模型的运行时性能结果,例如各种硬件的吞吐量、延迟、模型大小和内存占用。但是模型加速模块的demo是需要注册账户和购买的。

6.4,目标检测网络文章
- 一文读懂Faster RCNN
- 从编程实现角度学习Faster R-CNN(附极简实现)
- Mask RCNN学习笔记
- Mask RCNN 源代码解析 (1) - 整体思路
- 物体检测之Focal Loss及RetinaNet
- CVPR18 Detection文章选介(下)
- 2020首届海洋目标智能感知国际挑战赛 冠军方案分享
- 目标检测中的样本不平衡处理方法——OHEM, Focal Loss, GHM, PISA
6.5,语义分割文章
6.6,3D 视觉技术文章
6.7,深度学习的评价指标文章
- ROC和AUC介绍以及如何计算AUC
- COCO目标检测测评指标
- 如何评测AI系统?
- PLASTER:一个与深度学习性能有关的框架
- The Correct Way to Measure Inference Time of Deep Neural Networks
七,模型压缩与量化
7.1,轻量级网络设计
网络结构碎片化更多是指网络中的多路径连接,类似于
short-cut,bottle neck等不同层特征融合,还有如FPN等结构。拖慢并行的一个很主要因素是,运算快的模块总是要等待运算慢的模块执行完毕。
- ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
- ShufflenetV2_高效网络的4条实用准则
- 轻量级神经网络:ShuffleNetV2解读
7.2,模型压缩文章
- 解读模型压缩3:高效模型设计的自动机器学习流水线
- Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding
- 韩松Deep compression论文讲解——PPT加说明文字
- 论文总结 - 模型剪枝 Model Pruning
- 编译器与IR的思考: LLVM IR,SPIR-V到MLIR
7.3,神经网络量化文章
1,量化是指用于执行计算并以低于浮点精度的位宽存储张量的技术,或者说量化就是将神经网络的浮点算法转换为定点。 量化模型对张量使用整数而不是浮点值执行部分或全部运算。
2,量化简单来说就是将浮点存储(运算)转换为整型存储(运算)的一种模型压缩技术。
3,虽然精心设计的
MobileNet能在保持较小的体积时仍然具有与GoogleNet相当的准确度,不同大小的MobileNet本身就表明——也许一个好的模型设计可以改进准确度,但同类模型中仍然是更大的网络,更好的效果!
4,权重值域调整是另一个机器学习过程,学习的目标是一对能在量化后更准确地运行网络的超参数
min/max。
7.4,推理框架剖析文章
八,高性能计算
8.1,CPU/GPU/AI 芯片科普
- 一文读懂 GPU 的发展历程
- CPU、GPU、NPU等芯片架构、特点研究
- 什么是异构并行计算?CPU与GPU的区别是什么?
- 看懂芯片原来这么简单(二):AI为什么聪明?什么是华为自研架构NPU?
- 【专利解密】如何提高AI资源利用率? 华为卷积运算芯片
- 嵌入式系统 内存模块设计
8.2,指令集(ISA)学习资料
Neon是ARM平台的向量化计算指令集,通过一条指令完成多个数据的运算达到加速的目的,或者说Neon是 ARM 平台的SIMD(Single Instruction Multiple Data,单指令多数据流)指令集实现。常用于AI、多媒体等计算密集型任务。
8.3,矩阵乘优化文章
- 移动端arm cpu优化学习笔记----一步步优化盒子滤波(Box Filter)
- OpenBLAS gemm从零入门
- 通用矩阵乘(GEMM)优化算法
- 卷积神经网络中的Winograd快速卷积算法
- 知乎专栏-深入浅出GPU优化
- CUDA GEMM 理论性能分析与 kernel 优化
- OpenPPL 中的卷积优化技巧:概述总结类文章,无代码,非专注时刻也能阅读。
- 【张先轶】BLISlab学习优化矩阵乘。第一课
- 矩阵乘法与 SIMD
Winograd是一种快速卷积算法,适用于小卷积核,可以减少浮点乘法的次数。
九,模型部署(算法SDK开发)
9.1,模型部署文章
- 海思AI芯片(Hi3519A/3559A)方案学习(二十五)初识 mapper_quant 和mapper_param
- 部署PyTorch模型到终端
- 多场景适配,TNN如何优化模型部署的存储与计算
- 模型转换、模型压缩、模型加速工具汇总
- 深度学习模型转换与部署那些事(含ONNX格式详细分析)
- ONNX初探
博客阅读后的知识点总结
1,为了尽可能地提高 MAC阵列 的利用率以及卷积运算效率,阵列控制模块会根据第一卷积参数矩阵的行数和第一卷积数据阵列的行数来确定第一乘法累加窗口的列数。
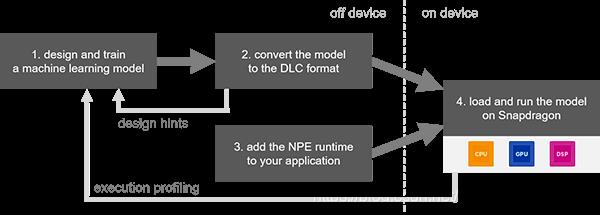
2,SNPE 开发流程:
3,目标检测模型效果提升方法:
- 以
Cascade RCNN作为baseline,以Res2Net101作为Backbone; Albumentation库做数据集增强-用在模型训练中;- 多尺度训练(
MSTMulti-scale training/testing)的升级版-SNIP方法(Scale Normalization for Image Pyramids),用在baseline模型训练和测试中:解决模板大小尺度不一的问题; DCN可变性卷积网络-用在baseline模型的backone中;soft-NMS:解决目标互相重叠的问题;HTC模型预训练,Adam优化算法可以较好的适应陌生数据集,学习率热身(warm-up)来稳定训练过程。
4,SNIP 论文解读:
SNIP 非常 solid 地证明了就算是数据相对充足的情况下,CNN 仍然很难使用所有 scale 的物体。个人猜测是由于 CNN 中没有对于 scale invariant 的结构,CNN 能检测不同 scale 的“假象”,更多是通过CNN 来通过 capacity 来强行 memorize 不同 scale 的物体来达到的,这其实浪费了大量的 capacity,而 SNIP 这样只学习同样的 scale 可以保障有限的 capacity 用于学习语义信息。论文的关键贡献:发现现在的 CNN 网络无法很好的解决 scale invariance 的问题,提出了一个治标不治本的方法。
5,高效模型设计(模型压缩)方法:
一般而言,高效模型的设计有 6 大基本思路:1)轻量级架构、2)模型裁剪、3)模型搜索、4)低精度量化、5)知识蒸馏、6)高效实现。
6,网络深度与宽度的理解及意义
更多理解参考知乎网络宽度对深度学习模型性能有什么影响?
在一定的程度上,网络越深越宽,性能越好。宽度,即通道(channel)的数量,网络深度,及 layer 的层数,如 resnet18 有 18 层网络。注意我们这里说的和宽度学习一类的模型没有关系,而是特指深度卷积神经网络的(通道)宽度。
网络深度的意义:CNN 的网络层能够对输入图像数据进行逐层抽象,比如第一层学习到了图像边缘特征,第二层学习到了简单形状特征,第三层学习到了目标形状的特征,网络深度增加也提高了模型的抽象能力。网络宽度的意义:网络的宽度(通道数)代表了滤波器(3维)的数量,滤波器越多,对目标特征的提取能力越强,即让每一层网络学习到更加丰富的特征,比如不同方向、不同频率的纹理特征等。
7,所有 Inception 模型都具有一个重要的性质——都是遵循 拆分-变换-合并(split-transform-merge) 的设计策略。
8,对于某种指令,延迟 latency 主要关注单条该指令的最小执行时间,吞吐量 throughout 主要关注单位时间内系统(一个 CPU 核)最多执行多少条该指令。因为 AI 计算的数据量比较大,所以更关注吞吐量。
9,CPU 高性能通用优化方法包括:
- 编译选项优化
- 内存性能和耗电优化:内存复用原则,小块快跑是内存设计的重要原则。
- 循环展开:循环的每次迭代都有一定的性能损失(分支指令)。但是现代 ARM 处理器具有分支预测的能力,它可以在执行条件之前预测是否将进入分支,从而降低性能损耗,这种情况下全部循环展开的的优势就减弱了。
- 并行优化和流水线重排:并行优化分为多线程核与核之间数据处理,以及单核心内部并行处理。从本质上讲,流水线重排也是一种并行优化。
10,卷积性能优化方式:卷积的计算方式有很多种,通用矩阵运算(GEMM)方式有良好的通用性,但是仅使用 GEMM 无法实现性能最优。除 GEMM 外,常用的优化方法还包括滑窗(Sliding Window)、快速傅里叶变换(Fast Fourier Transform, FFT)、Winograd 等。不同的方法适合不同的输入输出场景,最佳的办法就是对算子加入逻辑判断,将不同大小的输入分别导向不同的计算方法,以最合适的方法进行卷积计算。
- 大多数情况下,使用滑窗方法的计算性能还是无法和
GEMM方法比较,但是一般当输入小于 32 × 32 32\\times 32 32×32 时,可以考虑采用滑窗的优化方式。 Winograd是存在已久的性能优化算法,在大多数场景中,Winograd算法都显示了较大的优势,其用更多的加法运算代替部分乘法运算,因为乘法运算耗时远高于加法运算。Winograd适用于乘法计算消耗的时钟周期数大于加法运算消耗的时钟周期数的场景,且常用于 3 × 3 3\\times 3 3×3 卷积计算中。对于CPU,一般来说,一次乘法计算消耗的时间是一次加法计算消耗时间的6倍。FFT方法不适合卷积核较小的CNN模型。
11,下图展示了如何在英伟达 GPU 架构发展史以及单块 GPU 上纵向扩展以满足深度学习的需求(截止2020年)。

12,Deep compression 论文阅读总结
deep compression是解决存储问题,对于速度问题几乎没获得改善;- 权值剪枝还得看另外一篇论文:learning both weights and connection for efficient neural network
CNN模型的存储空间问题,主要还是在全连接层,若要改善inference速度,需要在卷积层下功夫。
13,Deep Compression 论文介绍的神经网络压缩方法,可分为三步:
- 剪枝:舍弃权重绝对值较小的权重,并将剩余权重以稀疏矩阵表示。
- 量化:将剪枝结果进行进一步量化,具体的是构建一组权值码本,使模型中的权值共享码本中的其中一个权重值,以减少每个权重保存所需的比特数。
- 霍夫曼编码(可选):通过霍夫曼编码,进一步地压缩索引值以及权重数值地存储空间。
参考资料
以上是关于cv算法工程师学习成长路线的主要内容,如果未能解决你的问题,请参考以下文章