数据库建表规约,索引创建及失效分析
Posted niaonao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库建表规约,索引创建及失效分析相关的知识,希望对你有一定的参考价值。
文章目录
1. 建表规约
1.1 表达是否概念的字段,使用 is_xxx 的方式命名,数据类型为 unsigned tinyint;
1.2 表名、字段名使用小写字母或数字;
禁止数字开头,禁止两个下划线中间值出现数字。
禁用保留字,保留字即有特定语义的字符串,如 select,distinct,from,range,desc。
1.3 表名称命名建议为”项目名_表名“,基础模块建议为”模块名_表名“
1.4 索引创建命名
唯一索引名称以 uk_name 命名;
普通索引名以 idx_name 命名;
联合索引以 idx_col1_col2 命名;
-- 创建索引SQL
-- 创建主键唯一约束索引
ALTER TABLE action_all ADD PRIMARY KEY uk_id (`id`) USING BTREE;
-- 创建及删除普通索引;最左前缀原则,实际上创建了两组组合索引
-- 组合一:type;组合二:type、sellerNick
ALTER TABLE action_all ADD INDEX `idx_type_sellerNick` (`type`, `sellerNick`);
ALTER TABLE action_all DROP INDEX `idx_type_sellerNick`;
1.5 小数类型为 decimal,禁止使用 float 或 double
1.6 如果存储的字符串长度几乎相等,使用 char 定长字符串类型
1.7 合适的字符存储长度,不但节约数据库表空间、节约索引存储,更重要的是提升检索速度
1.8 varchar 是可变长度字符串,不预先分配存储空间,长度不要超过 5000,超出应定义为 text 字段类型,独立出来一张表,避免影响其他字段的索引效率。
1.9 尽量使用数字型字段。字符型相对数字型会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
1.10 表必备的四个字段,自增主键 id,记录状态 state,创建时间 create_time,更新时间 update_time。
1.11 修改字段含义或对表示状态的字段追加时,应更新字段注释。
1.12 字段允许适当冗余,以提高性能。
1.13 单表容量超过 2GB或者单表行数超过 500 万行,推荐进行分库分表。
【问题一】key 和 index 的有什么区别
数据库保留字 key 和 index 都可用于创建数据库索引使用;
索引分类包括,主键索引,唯一索引,普通索引;
key 创建约束索引,用于主键索引和唯一索引;
index 创建普通索引。
key 具有双重意义,约束和索引,偏重于约束规范数据库完整性,同时具备索引辅助查询作用。包括主键索引 primary key、唯一索引 unique key、外键索引 foreign key。key 包括了约束 constraint 和索引 index。
index 仅作为辅助查询,没有约束作用,约束是 key 的作用,创建 index 时会在另外的 innodb 表空间以一个类似目录的结构存储。
【问题二】为什么使用 index,不用保留字 key 替代 index;
index 仅作为普通索引,只具有辅助查询作用;key 会创建约束 constraint 和索引 index。
创建 key 通常是为了约束表行为的,而不是为了查询,如唯一约束,外键约束;仅考虑辅助查询的话,还是通过创建 index 索引来辅助查询即可。
【问题三】组合索引
组合索引就是相对单字段索引来说的,支持对多个字段创建组合索引,创建方式与单个字段的索引相同;
组合索引遵循最左前缀原则,从左往右组合的优先顺序,组合索引列的组合唯一。
组合索引的优点,索引覆盖和索引下推。索引覆盖减少了很多回表操作,提高了查询的效率。索引下推,索引列越多通过索引筛选的数据越少。
【问题四】聚簇索引与非聚簇索引
如果表设置了主键,则主键就是聚簇索引;
如果表没有主键,则会默认第一个 NOT NULL,且具有唯一约束的列作为聚簇索引。
如果没有主键,也没有唯一约束的列,则默认创建一个隐藏的 row_id 作为聚簇索引;
InnoDB的聚簇索引的叶子节点存储的是页结构,一个页包含多行数据,可以直接定位到行记录。
InnoDB必须要有至少一个聚簇索引。
聚簇索引的叶子节点的值是所有的列值,非聚簇索引的叶子节点的值是索引列+主键。
普通索引也叫二级索引,除聚簇索引外的索引,即非聚簇索引。
InnoDB的普通索引叶子节点存储的是主键(聚簇索引)的值,而MyISAM的普通索引存储的是记录指针。
【问题五】索引有什么缺点
索引文件是 innodb 独立的存储文件,占用一定的磁盘空间;一个表禁止创建过多的索引,否则大表下,索引文件膨胀很快,需要建立最优的索引。
更新表 insert/update/delete 的时候需要同时更新索引文件,存在一定的速度影响。
【问题六】索引失效的情况
左模糊或全模糊查询时,根据 B+ 树结构可知,无法左模糊查询,索引失效。
索引列上使用范围查询 >、<、between 时索引失效。
条件查询存在 or 保留字时索引失效,建议使用 union 代替。
条件查询存在字段为 varchar 时,查询条件未加引号导致索引失效。
查询的结果集超过全表的 30% 时索引失效。不建议对枚举类型字段创建索引,比如常见的 status,type 字段。
查询条件使用函数在索引列上时索引失效。
字符串条件查询时,应单引号括起来,否则由于隐式转换会导致索引失效。
对于索引列进行逻辑运算,包括 +、-、* 、/、<>、! 等运算会索引失效,所以 != 在条件查询中会导致索引失效;这种情况下可以创建函数索引来处理。
对于组合索引,根据最左前缀原则不使用左边的字段,索引失效。
in、not in、exists、not exists 保留字的使用会索引失效。
B-tree索引 is null、is not null 不会走索引,位图索引 is null,is not null 都会走。
当变量采用的是times变量,而表的字段采用的是date变量时,或相反情况时索引失效。
正常使用索引的语句:
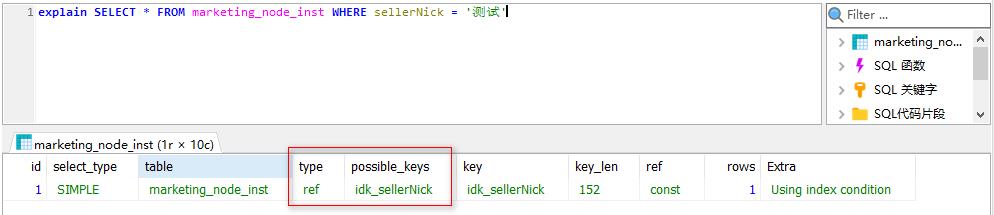
索引失效的部分场景:
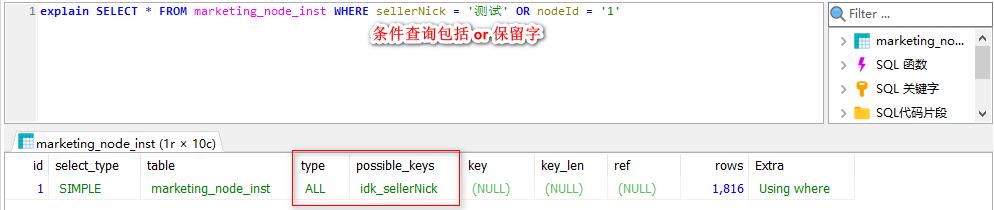
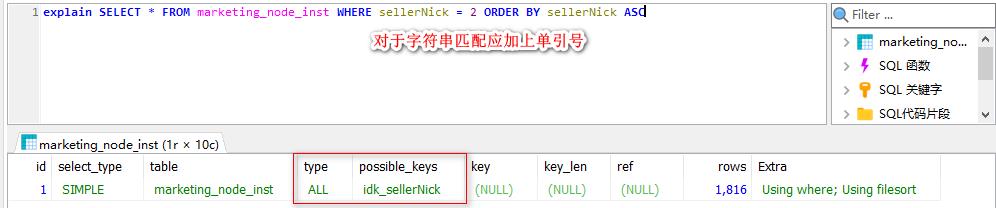
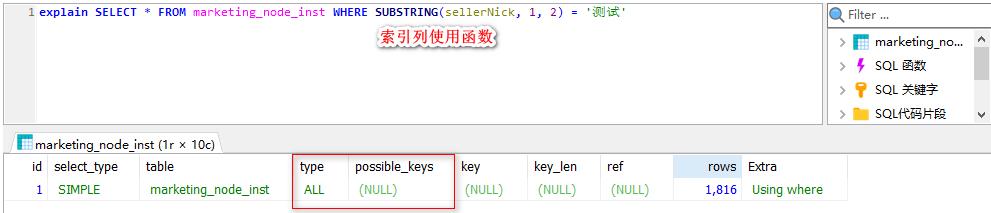
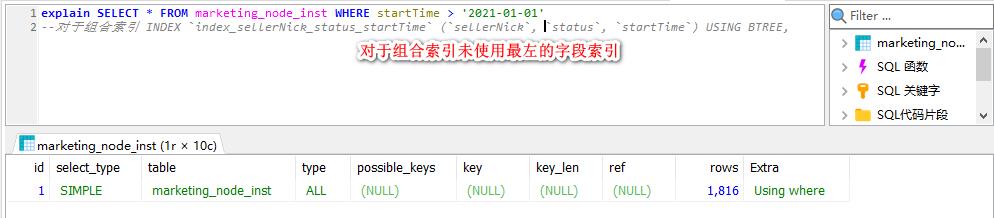
2. 索引规约
2.1 业务上具有唯一特性的字段,必须创建唯一索引
2.2 超过三个表联合查询,禁止使用 join。需要 join 的字段需要保证数据类型完全一致;多表关联查询时,保证关联的字段创建索引。
2.3 存储引擎在创建索引的时候,索引键长度是有一个较为严格的长度限制的,所有索引键最大长度总和不能超过1000,而且不是实际数据长度的总和,而是索引键字段定义长度的总和。
主要字符集的计算方式:
latin1 = 1 byte = 1 character
uft8 = 3 byte = 1 character
gbk = 2 byte = 1 character
2.4 页面搜索严谨左模糊或全模糊,必须则可以通过搜索引擎来解决。
索引文件具有 B-Tree 的最左前缀匹配特性,左边的值无法确定,无法使用索引,即左模糊或全模糊查询时索引失效。
2.5 对于 order by 的使用,注意考虑索引的有序性。order by 最后的字段是组合索引的一部分,并且放在索引组合顺序的最后,避免出现 file_sort 的情况,影响查询性能。
对于组合索引 idx_a_b_c;
正例:where a=? and b=? order by c;
反例:索引中有范围查找,那么索引有序性无法利用,如:WHERE a>10 ORDER BY b;索引a_b无法排序。即索引列上使用范围查询时索引失效;
2.6 分页查询优化
利用延迟查询或子查询优化超多分页场景
快速定位需要获取的 id 段,然后再关联
SELECT a.* FROM 表 1 a, (select id from 表 1 where 条件 LIMIT 100000,20 ) b where <u>a.id</u>=<u>b.id</u>
查询单条记录时,使用 limit 1 效率更高;
select 具体字段比 select * 效率更高;
统计记录数量使用 select count( * )
复杂的函数嵌套可以转换为代码逻辑来处理;
instr() 效率高于 like,需考虑索引失效问题
not exists 优于 not in,需考虑索引失效问题
in 优于 not in,需考虑索引失效问题
2.7 SQL性能优化的目标:至少要达到 range 级别,要求是 ref级别,如果可以是 consts最好。
consts 单表中最多只有一个匹配行(主键或者唯一索引),在优化阶段即可读取到数据。
ref 指的是使用普通的索引(normal index)。
range 对索引进行范围检索。
2.8 建组合索引的时候,区分度最高的在最左边
2.9 SQL 语句 where 条件存在等值查询和范围查询时,等值查询放前面;
select id from custom where code = 'code' and createTime > '2021-07-01 00:00:00';
2.10 语句执行阶段
语句的执行阶段分为
- FROM 阶段
- WHERE 阶段
- GROUP BY 阶段
- HAVING 阶段
- SELECT 阶段
- ORDER BY 阶段
- LIMIT 阶段
示例语句
-- 业务处理失败记录表
CREATE TABLE `failure_log` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT '主键,自增',
`createTime` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`updateTime` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`customId` BIGINT(20) NOT NULL COMMENT '自定义人群ID',
`version` INT(11) NOT NULL DEFAULT '1' COMMENT '版本号',
`userNick` VARCHAR(50) NULL DEFAULT NULL COMMENT '失败人员名称' COLLATE 'utf8_general_ci',
`reason` VARCHAR(256) NULL DEFAULT NULL COMMENT '失败原因' COLLATE 'utf8_general_ci',
`remark` VARCHAR(256) NULL DEFAULT NULL COMMENT '备注' COLLATE 'utf8_general_ci',
PRIMARY KEY (`id`) USING BTREE,
INDEX `idk_createTime` (`createTime`) USING BTREE
)
COLLATE='utf8_general_ci'
ENGINE=InnoDB
AUTO_INCREMENT=1;
-- 按天统计 2021-10-01 日前,每日业务处理失败超出 100 次最近十日及失败次数。
SELECT LEFT(createTime,10) createTime,COUNT(*) countNum
FROM failure_log
WHERE createTime < '2021-10-01'
GROUP BY LEFT(createTime,10)
HAVING(COUNT(*)) > 100
ORDER BY createTime DESC
LIMIT 0,5
-- 示例结果
"createTime" "countNum"
"2021-09-29" "170"
"2021-09-28" "150"
"2021-09-26" "200"
"2021-09-25" "150"
"2021-09-20" "278"
上述 SQL 的执行阶段简述
语句的执行阶段,则包括从表 failure_log 中按条件 where 筛选数据,然后对条件筛选结果 group by 分组,聚合分析条件判断 having 后的结果集合按 select 获取部分指定数据进行透出,再对此时的结果集进行 order by 排序,limit 返回排序后指定条数据
2.11 Explain 语句执行计划分析
- select_type 项
SIMPLE: 简单SELECT,不使用UNION或子查询等PRIMARY: 子查询中最外层查询,查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARYUNION: UNION中的第二个或后面的SELECT语句DEPENDENT UNION: UNION中的第二个或后面的SELECT语句,取决于外面的查询UNION RESULT: UNION的结果,union语句中第二个select开始后面所有selectSUBQUERY: 子查询中的第一个SELECT,结果不依赖于外部查询DEPENDENT SUBQUERY: 子查询中的第一个SELECT,依赖于外部查询DERIVED: 派生表的SELECT, FROM子句的子查询UNCACHEABLE SUBQUERY: 一个子查询的结果不能被缓存,必须重新评估外链接的第一行
- type 项:全表查询 ALL 性能差,NULL性能最好
ALL:Full Table Scan, mysql将遍历全表以找到匹配的行index: Full Index Scan,index与ALL区别为index类型只遍历索引树range: 只检索给定范围的行,使用一个索引来选择行ref: 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值eq_ref: 类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者 unique key作为关联条件const、system: 当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量,system是const类型的特例,当查询的表只有一行的情况下,使用systemNULL: MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。
- possible_keys 与 key
possible_keys 包含 key,是 key 的超集;查询可能会使用到的索引项,key是查询使用到的索引项 - key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度;不损失精确性的情况下,长度越短越好
(key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的) - rows
列与索引的比较,表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值 - extra
Using where:不用读取表中所有信息,仅通过索引就可以获取所需数据,这发生在对表的全部的请求列都是同一个索引的部分的时候,表示mysql服务器将在存储引擎检索行后再进行过滤
Using temporary:表示MySQL需要使用临时表来存储结果集,常见于排序和分组查询,常见 group by ; order by
Using filesort:当Query中包含 order by 操作,而且无法利用索引完成的排序操作称为“文件排序”
Using join buffer:改值强调了在获取连接条件时没有使用索引,并且需要连接缓冲区来存储中间结果。如果出现了这个值,那应该注意,根据查询的具体情况可能需要添加索引来改进能。
Impossible where:这个值强调了where语句会导致没有符合条件的行(通过收集统计信息不可能存在结果)。
Select tables optimized away:这个值意味着仅通过使用索引,优化器可能仅从聚合函数结果中返回一行
No tables used:Query语句中使用from dual 或不含任何from子句
Not exists:MySQL能够对查询执行 LEFT JOIN 优化,并且在找到与 LEFT JOIN 条件匹配的一行后,不会在上一行组合中检查此表中的更多行。
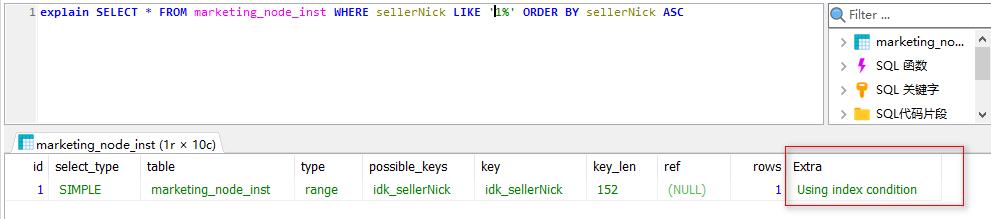
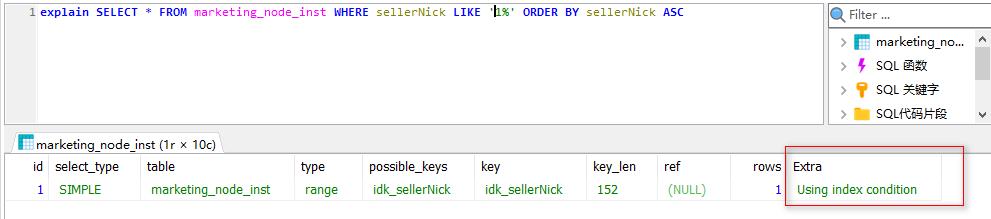
【问题一】神麽是 file_sort
如果我们需要根据某一个字段继续排序并且没有添加索引的话,那么使用 explain 对该 SQL 进行查询的话就会在 Extra 中看到 filesort。有索引的话直接取就好了,不需要排序操作;没有创建索引时,查询时会对排序字段进行排序,需要把这部分数据全部加载到内存中来排序,内存不足会导致数据库崩溃,因此会借助外部文件系统进行排序,这就是 filesort。
如下,已对表字段 sellerNick 创建普通索引,在索引失效时,对其排序会出现 filesort;
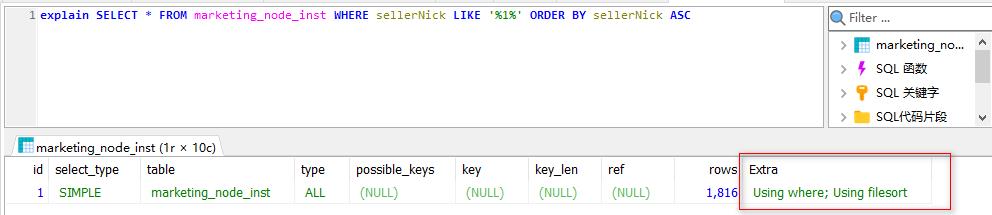
用于 filesort 的缓冲区大小查看
【问题二】神麽是回表查询
如果是聚簇索引,作为条件查询,只需要一次扫描 B+ 树即可通过聚簇索引定位到行记录;
对于普通索引,需要扫描两次 B+ 树来定位行记录,先通过普通索引定位到聚簇索引的值,然后第二次扫描 B+树通过聚簇索引的值定位到行记录。这就是回表查询。
3. SQL 规约
3.1 推荐使用 select count( * ),避免使用 select count(col);count( * ) 就是 SQL92 定义的标准统计行数的语法,跟数据库无关,跟 NULL和非 NULL无关。count( * )会统计值为 NULL的行;count(col) 不统计;
3.2 count(distinctcol) 计算该列除 NULL之外的不重复数量。注意 count(distinctcol1, col2) 如果其中一列全为 NULL,那么即使另一列有不同的值,也返回为 0。
3.3 当某一列的值全是 NULL时,count(col)的返回结果为 0,但 sum(col)的返回结果为NULL
3.4 使用 ISNULL()来判断是否为 NULL值。注意:NULL与任何值的直接比较都为 NULL。
NULL<>NULL的返回结果是 NULL,而不是 false。
NULL=NULL的返回结果是 NULL,而不是 true。
NULL<>1的返回结果是 NULL,而不是 true。
3.5 在代码中的分页逻辑,若 count 结果为 0,则直接返回避免执行后续的分页语句。
3.6 不推荐使用外键与级联;一切外键概念可在应用层通过业务逻辑来解决。外键与级联更新适用于单机低并发,不适合分布式、高并发集群;级联更新是强阻塞,存在数据库更新风暴的风险;外键影响数据库的插入速度。
3.7 禁止使用存储过程,难以调试扩展且不易移植。
3.8 in、not in 等使索引失效的情况,避免出现。
3.9 如果有全球化需要,所有的字符存储与表示,使用 utf-8编码。如果要使用表情,那么使用 utfmb4 来进行存储。
3.10 TRUNCATETABLE 比 DELETE 速度快,且使用的系统和事务日志资源少,但 TRUNCATE无事务且不触发 trigger,有可能造成事故,故不建议在开发代码中使用此语句
参考文章:
覆盖索引与回表
为什么我们要尽量避免FileSort(文件排序)?
MySQL中explain执行计划中额外信息字段(Extra)详解
Powered By niaonao
以上是关于数据库建表规约,索引创建及失效分析的主要内容,如果未能解决你的问题,请参考以下文章