计算机组成与设计---硬件/软件接口---处理器
Posted FANCY PANDA
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了计算机组成与设计---硬件/软件接口---处理器相关的知识,希望对你有一定的参考价值。
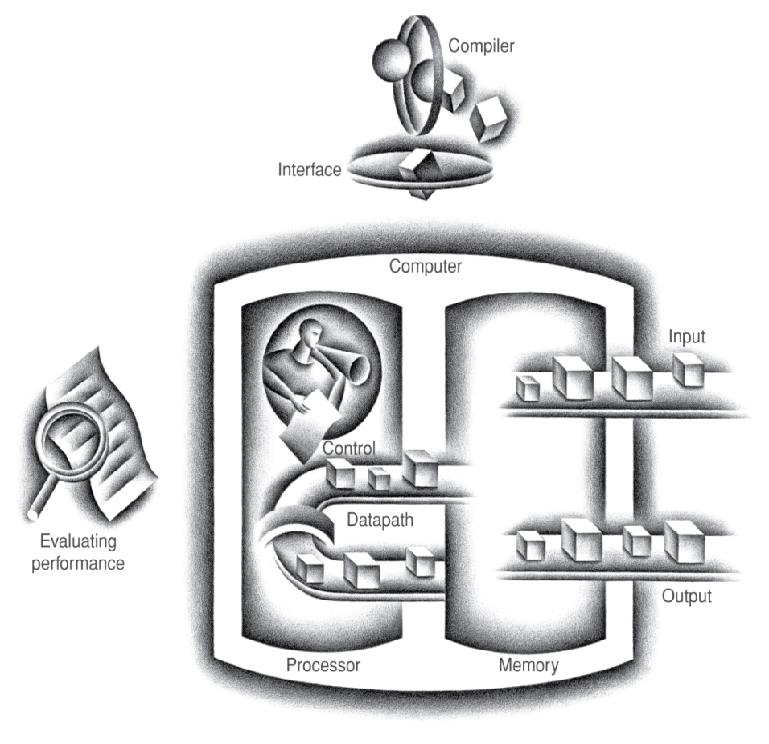
4.1逻辑设计的一般方法
二进制信息编码
- 低电平= 0, 高电平= 1
- 一线一位
- 根据多条数据总线确定多位数据编码
组合部件
- 对数据操作
- 输出是输入的函数

状态(时序)部件
- 存储信息
- 寄存器:将数据存储在电路里
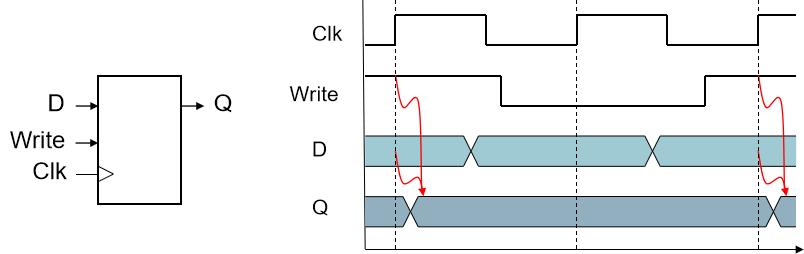
- 时钟信号决定数据更新时刻
- 边沿触发:当 Clk 从 0 变为 1时更新数据

- 带有写信号控制的寄存器
- 仅在时钟边沿且写控制信号为1时更新数据
- 在存储数据时使用
4.2建立数据通路
- CPU中处理数据和地址的所有部件
-
- 寄存器,数逻运算单元,多选器,存储器等
取指令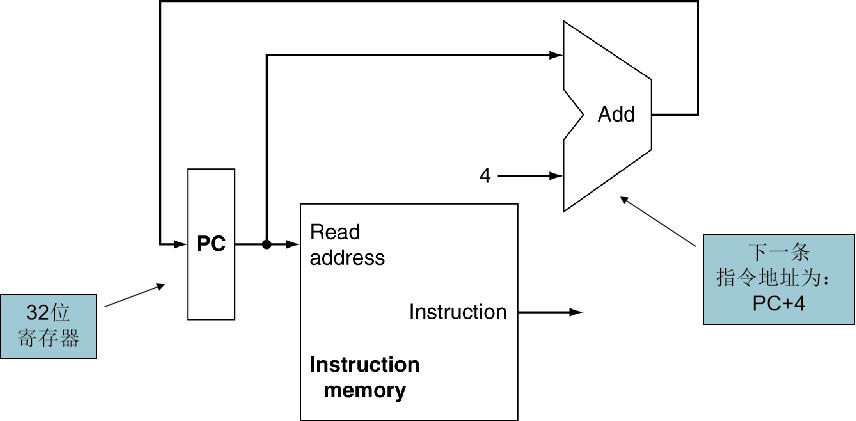
寄存器型指令
- 读取两个寄存器操作数
- 执行算术/逻辑运算
- 将运算结果写入寄存器

读取/存储( Load/Store )指令
- 读寄存器操作数
- 用16位偏移量 计算地址
-
- 使用ALU计算,偏移量需要进行符号扩展
- 读取(load) :从存储器读出数据并写入寄存器
- 存储(store):将寄存器内容写入存储器

分支指令
例如指令:bne $ s0,$ s1,exit # go to exit if $s0 ≠ $s1

-
读取寄存器操作数
-
比较两个操作数
-
- 使用ALU做减法,检查ALU的零输出信号
-
计算目标地址
-
- 符号扩展偏移量
-
- 左移2位(以字为单位的偏移量×4)
-
- 加到 PC + 4
-
-
- 取指阶段已计算(下一条指令的地址)

组成部件
- 取指阶段已计算(下一条指令的地址)
-
-
第一段数据通路需要在一个时钟周期内完成一条指令
-
- 每个数据通路部件一次只能完成一个功能
-
- 所以指令和数据需要分开存储
-
多选器为不同指令选择不同的数据源
寄存器型/读取/存储三类指令数据通路合并

4.3一个简单的实现机制
4.3.1 ALU控制
- ALU用于
-
- 读取/存储:F=加法
-
- 分支:F=减法
-
- 寄存器型: F 由funct字段决定
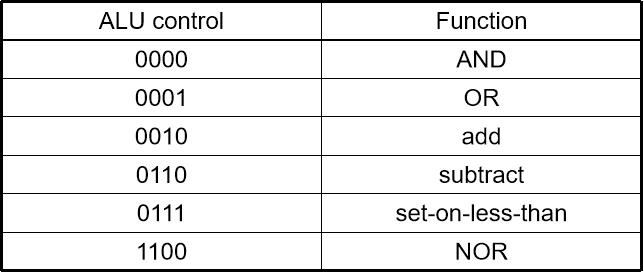
- 寄存器型: F 由funct字段决定
- 假设2位ALUOp从操作码获得
-
- 组合逻辑得到ALU控制
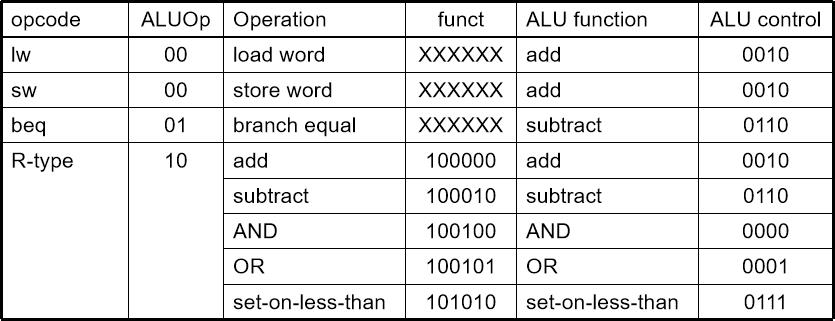
- 组合逻辑得到ALU控制
4.3.2主控制单元的设计
- 指令中的控制信号
R-型(寄存器)操作举例

add $t0, $s1, $s2

4.3.3为什么不使用单周期实现方式
- 时钟周期由执行时间最长的指令决定
-
- 读取指令数据通路,使用5个功能单元
-
- 1指令存储器 2寄存器堆 3 ALU4 数据存储器 5 寄存器堆
- 不同指令使用不同的时钟周期是不可行的,因为时钟周期必须满足所有指令中最坏的情况。
- 违反设计原则
-
- 加速常用操作
- 可以通过流水线技术提高性能
4.4流水线概述
4.4.1面向流水线的指令集
5段,每段一步
- IF: 从存储器读取指令
- ID: 指令解码并读取寄存器
- EX: 执行操作或计算地址
- MEM: 访问存储器操作数
- WB: 将结果写回寄存器
4.4.2流水线冒险
在下一个时钟周期中下一条指令不能执行的情形,称为冒险
- 结构冒险
-
- 需要的资源被占用
- 数据冒险
-
- 需要等待前面指令完成其数据读写操作
- 控制冒险
-
- 根据前面正在执行的指令决策控制操作
4.4.3对流水线概述的小结
- 流水线通过提高指令的吞吐率改进系统性能
-
- 并行执行多条指令
-
- 每条指令执行时间不变(相同延迟)
- 流水线设计者必须解决冒险
-
- 结构,数据,控制
- 指令集的设计影响流水线实现的复杂性
4.5流水线数据通路及其控制
4.5.1图形化表示的流水线

例:指令流水线有取指(IF)、译码(ID)、执行(EX)、访存(MEM)、写回寄存器(WB)五个过程段,共有16条指令连续输入此流水线。
⑴画出流水处理的时空图,假设时钟周期为100ns
⑵求流水线的实际吞吐率(单位时间里执行完毕的指令数)
⑶求流水线的加速比

答:
- 20条指令连续进入流水线时空图
- 流水线在20个时钟周期中执行完16条指令,故实际吞吐率为16/20×100ns=4/5×107条指令/S
- k级流水线处理n个任务所需时钟周期数为 Tk=k+(n-1)
非流水线处理器处理n个任务所需时钟周期数为 Te=nk
k级流水线处理器的加速比为Ck=Te/Tk=nk/k+(n-1)代入已知数据n=20,k=5,Ck=20×5/5+19=100/24=4.16
4.5.2流水线控制

4.6数据冒险:旁路与阻塞
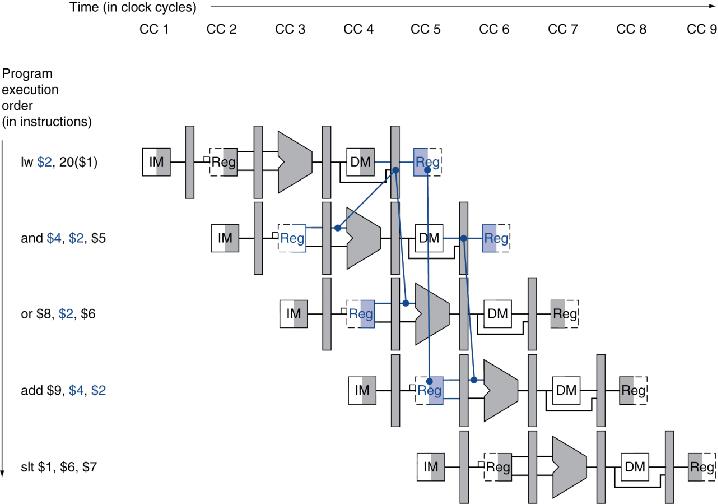
Load-Use 冒险检测
- 当运行指令在ID段解码时检查
- 给出ID段中的ALU 操作数寄存器号
-
- IF/ID.RegisterRs, IF/ID.RegisterRt
- 当出现以下情况时存在装载使用冒险
- ID/EX.MemRead and ((ID/EX.RegisterRt = IF/ID.RegisterRs) or (ID/EX.RegisterRt = IF/ID.RegisterRt))
- 如果检测到,阻塞并插入气泡
怎样阻塞流水线
- 将ID/EX 寄存器中的控制变量的值置为0
-
- EX, MEM and WB 空操作
- 阻止更新 PC 和 IF/ID 寄存器中的值
-
- 将执行中的指令重新解码
-
- 再次取出后续指令
-
- 对lw指令阻塞1个周期后允许MEM读取数据
-
-
- 接下来可以转到EX段
-
4.7控制冒险
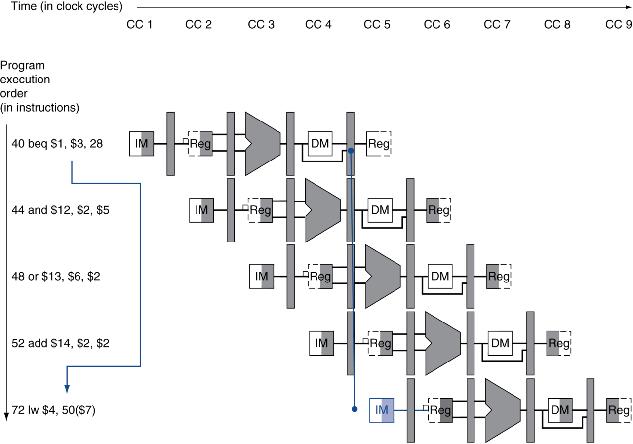
4.7.1 缩短分支的延迟
- 设置硬件将分支地址计算提前到 ID 段
- 目标地址加法器
- 寄存器比较器
例如:分支发生时的执行情况
36: sub $10, $4, $8
40: beq $1, $3, 7
44: and $12, $2, $5
48: or $13, $2, $6
52: add $14, $4, $2
56: slt $15, $6, $7
...
72: lw $4, 50($7)
4.7.2动态分支预测
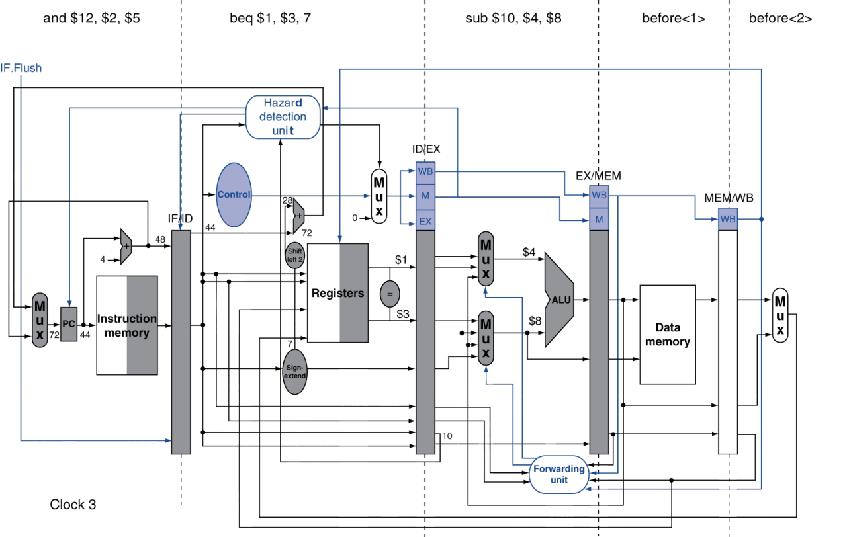
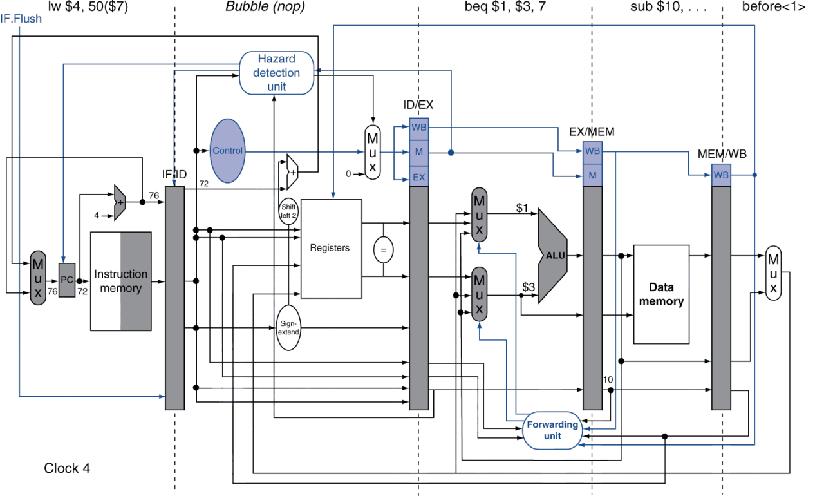
- 更深的和超标量流水线中,分支代价将增加
动态分支预测
- 分支预测缓存 (也称分支历史记录表)
- 按照最近的分支指令地址索引的存储区
- 包含分支是否发生的标志位
- -预测分支的执行过程
-
- 查表,采用上次执行该指令时相同的分支处理方法
-
- 沿着预测的方向进行取指
-
- 如果假设错误,则删除预测错误的指令,预测位取反,并返回原来的位置重新取指执行
4.8异常
- 不预期的事件发生,需要改变控制流
-
- 不同的 ISAs 对这两个术语定义也不同
- 异常
-
- CPU内部引起
-
- 例如:未定义的指令,溢出,用户进行操作系统调用等
- 中断
-
- 来自外部 I/O 控制器
- 处理异常和中断而不牺牲处理器性能是很困难的
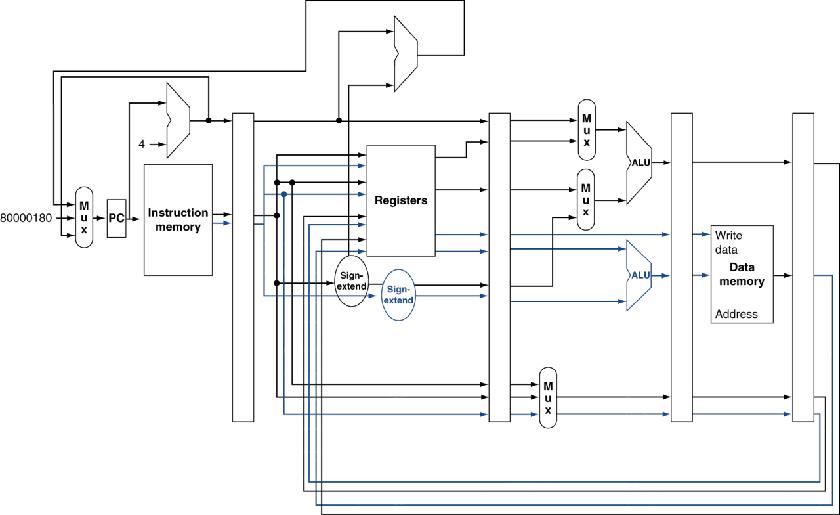
4.8.1 MIPS体系结构中的异常处理
- 由系统控制协处理器(CP0)管理异常
- 保存出错指令(被中断)的地址
-
- 异常程序计数器 (EPC)
- 保存问题产生的原因
-
- 状态寄存器 Cause register
-
- 我们假定一位
-
- 0 表示未定义指令, 1 表示算术溢出
- 异常处理系统跳转至统一的入口地址 8000 00180
- 向量中断
-
- 由异常原因决定中断控制的转移地址
- 例如:
-
- 未定义指令: 8000 0000
-
- 算术溢出: 8000 0180
- 指令可能是:
-
- 处理中断,或
-
- 跳转到实际的中断处理程序
4.8.2在流水线实现中的异常
- 控制冒险的另一种形式
- 假设加法指令
add $1, $2, $1在执行阶段产生了算术溢出 -
- 防止$1被破坏
-
- 完成前面的指令
-
- 清除add和后面的指令
-
- 设置Casue和EPC寄存器的值
-
- 把控制转交给异常处理程序
- 类似于分支预测错误的情形
-
- 使用许多相同的硬件

- 使用许多相同的硬件
4.9 指令级并行
-
流水线:并行执行多条指令
-
增加指令级并行程度
-
增加流水线深度
-
- 每级减少工作 为 缩短时钟周期
-
多发射
-
- 复制流水线的段 为 多流水线
-
- 每个时钟周期执行多条指令
-
- CPI < 1, 因此用IPC来描述
-
- E.g., 4GHz 4-路多发射微处理器
-
-
- 16 BIPS, peak CPI = 0.25, peak IPC = 4
-
-
- 但实际应用中,指令间的相关性降低了性能。
-
静态多发射
-
- 编译器对即将一同发射指令分组
-
- 打包指令并发送到发射槽
-
- 编译器检测和避免冒险
-
动态多发射
-
- 在每个时钟周期,CPU检查指令流并选择要发射的指令
-
- 编译器通过调整指令顺序加以协助
-
- 运行阶段,CPU通过先进的技术(硬件支持)能消除某些冒险。
4.9.1推测的概念
“猜测”指令结果
- 尽快执行操作
- 检查猜测是否正确
- 如果正确,完成操作
- 如果不正确,回滚,做正确的
编译器/硬件推测
- 编译器可以重新排序指令
-
- e.g., 把load指令移到分支指令的前面
-
- 可以提供修复指令,以便从错误的猜测中恢复
- 硬件可以提前执行指令
-
- 缓存猜测的结果直到该结果得到确认
-
- 清除错误预测的缓存结果
推测与异常
- 推测执行指令引起了本不存在的异常
-
- e.g., 在空指针检查之前,推测执行装载指令
- 静态推测
-
- 加入额外的推测支持,推迟异常
- 动态推测
-
- 缓存异常,直到导致异常的指令确定执行完(可能不发生)
4.9.2静态多发射处理器
- 编译器分组即将发射的多条指令,形成“发射包”
-
- 一组指令可以在一个时钟周期内被发射
-
- 由流水线需求的资源决定
-
- 可以把发射包看成一条长指令
- 指定了多个并发操作
- 超长指令字 (VLIW)
调度静态多发射
- 编译器必须能够消除一些或全部的冒险
-
- 重新排序指令,形成发射包
-
- 同一个包内,指令间不相互依赖
-
- 包间可能有某种依赖关系
-
- 可以改变ISAs;但编译器设计者必须知道!
-
- 必要时可以插入空操作
MIPS静态双发射
- 必要时可以插入空操作
- 双发射包
-
- 一个是ALU操作或分支指令
-
- 一个是装载或存储指令
-
- 64位对齐方式
-
- 先执行ALU/branch,再执行load/store
-
- 如找不到另一条与之可以同时发射的指令,就用nop指令代替它
MIPS静态双发射的冒险
- 如找不到另一条与之可以同时发射的指令,就用nop指令代替它
- 并行执行更多的指令
- EX 数据冒险 data hazard
-
- 转发可以避免单一发射的阻塞
-
- 现在load/store不能在同一个包里使用ALU的运算结果
-
add $t0, $s0, $s1load $s2, 0($t0)
-
- 可以分成两个包,对阻塞很有效
- Load-use hazard 冒险
-
- 仍有一个周期的使用延迟,但现在是两条指令
-
- 需要更高级的调度技术
4.9.3动态多发射处理器
- “超标量”处理器
- CPU决定每个周期发射0条,1条,还是多条指令
-
- 避免结构和数据冒险
- 避免使用编译器调度
-
- 尽管它还是有帮助的
-
- 不管代码是否经过调度,都是由硬件来保证执行的正确性
动态流水线调度
- 不管代码是否经过调度,都是由硬件来保证执行的正确性
- 为避免阻塞的发生,允许CPU不按次序执行指令
-
- 但要按顺序把结果提交给寄存器

寄存器重命名
- 但要按顺序把结果提交给寄存器
- 保留站和重排序缓冲区提供有效的寄存器的重命名机制
- 当指令发射到保留站时
- 如果它的操作数在寄存器堆或冲排序缓冲区中可用
-
- 操作数立即被复制到保留站中
-
- 操作数对应的寄存器堆副本不再需要,其值可以被覆盖
- -如果操作数不可用
-
- 它应该被某个功能单元以计算结果的形式提供给保留站
-
- 可以不用更新寄存器,直接跳过
推测
- 可以不用更新寄存器,直接跳过
- 推测分支并继续进行取指和执行
-
- 直到分支结果确定之后才提交Don’t commit until branch outcome determined
- 装载推测Load speculation
- 避免装载和cache缺失的延迟Avoid load and cache miss delay
-
- 预测有效地址Predict the effective address
-
- 预测装载的数值Predict loaded value
-
- 在完成存储之前装载Load before completing outstanding stores
-
- 顺便存储到装载单元Bypass stored values to load unit
- 直到推测被清除之后才提交装载Don’t commit load until speculation cleared
计算机组成与设计—硬件/软件接口—大容量和高速度:开发存储器层次结构
以上是关于计算机组成与设计---硬件/软件接口---处理器的主要内容,如果未能解决你的问题,请参考以下文章