机器学习之朴素贝叶斯分类
Posted Icy Hunter
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习之朴素贝叶斯分类相关的知识,希望对你有一定的参考价值。
文章目录
朴素贝叶斯

基于朴素贝叶斯公式来估计后验概率P(c | x)的主要困难在于类条件概率P(x | c)是所有属性上的联合概率,难以从有限的训练样本直接估计而得。因此,朴素贝叶斯就是拥有一个朴素的条件:“属性条件独立性假设”:对于已知类别,假设所有属性相互独立,也就是说假设每个属性独立地对分类结果发生影响。
因此可以重写为:
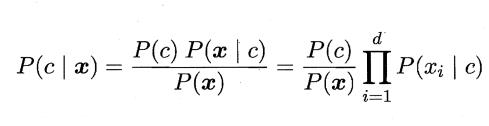
其中d为属性数目,xi为x在第i个属性上地取值。
由于对所有类别来说P(x)相同,因此基于上式朴素贝叶斯分类器可以写成:

其实也是很好理解的,就比如一组训练数据,我们先计算出好瓜并且色泽青绿的概率、好瓜并且根蒂蜷缩的概率、坏瓜并且色泽青绿的概率…根据已有的数据,我们能够得到一组概率值,那么基于此,我们其实就已经得到了朴素贝叶斯分类器了,因为当我们得到一组新的测试数据的时候,我们只需要看数据色泽、根蒂等特征是符合好瓜里的概率大还是坏瓜里的概率大就能够做出判断了。
计算的具体方式如下:

例题
举个例子:


首先估计类先验概率P©:

然后为每个属性估计条件概率P(xi| c):



看到这里可以回味一下,朴素贝叶斯其实思路很简单,就是类别中哪些特征出现的概率大,那么当测试数据属于这些特征时,计算出是这类的概率就会大了,就达到分类的效果了。
但是在这里单纯这样计算会存在一个bug,比如一个瓜很多条件都符合好瓜的特征,但是其中有一个特征因为训练集太小而并没有在好瓜中出现,那么其无论多像好瓜,都会被认为好瓜的概率为0,因为0乘任何数都为0

为此,我们可以采用拉普拉斯修正:

强调一下,Ni为表示第i个属性的取值数
那么上例可以进行如下修正:


核心代码实现
使用的西瓜数据集3.0
首先根据训练集计算出各类标签的各种特征的先验概率存储到一个概率字典中,然后就能够根据输入的数据得到类别概率从而获得最终的分类结果。
首先定义一个朴素贝叶斯类
定义我们需要的变量

初始化概率字典:
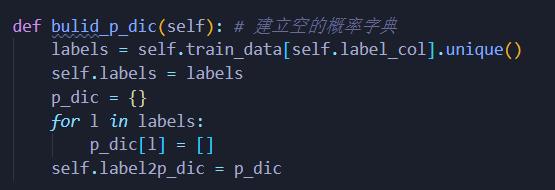
初始化后即可进行训练,训练方法定义如下:

首先需要计算在相同标签下进行不同特征的先验概率的字典并保存下来。
上面主要是计算离散特征的。

接下来就是计算连续型特征。

定义概率密度函数,为评估分类做准备。

用于评估模型,如果有标签,那么就输出对应的准确率
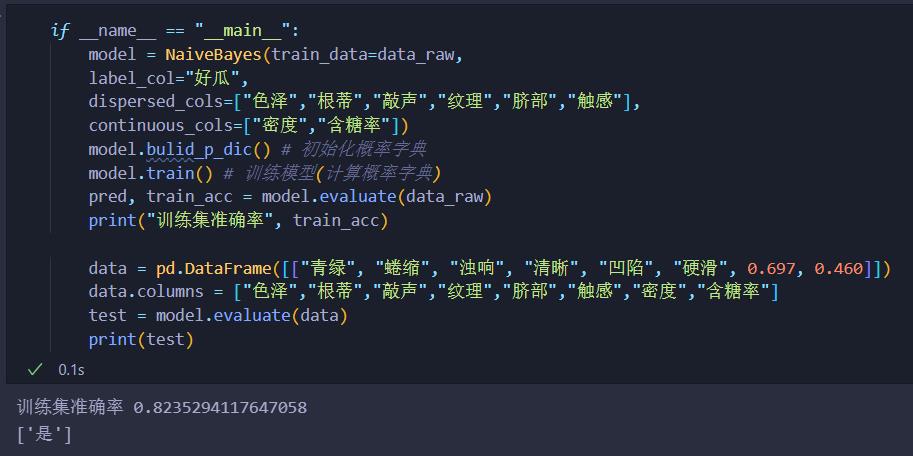
main函数入口,以及运行结果展示。
其中测试的样例就是上面提到的例题里的测试样例,分类器判别为好瓜,和例题答案一致。
我们可以接着看一下构建的概率字典:

可以看到其中的结果是经过拉普拉斯平滑过后的结果,与例题中的同样对应。
数据集+可运行代码:
机器学习之朴素贝叶斯分类+拉普拉斯平滑
参考
机器学习——周志华
以上是关于机器学习之朴素贝叶斯分类的主要内容,如果未能解决你的问题,请参考以下文章