迭代器的学习心得
Posted 正义的伙伴啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了迭代器的学习心得相关的知识,希望对你有一定的参考价值。
文章目录
迭代器的学习心得
这段时间学习STL实现自己的STL时第一次接触迭代器,学起来有些痛苦,下面来记录一下我的学习心得,理解有些浅薄
首先我们要了解 ——泛型编程
学完类之后给我的感觉是: C++将一个 概念 抽象成一个类,这个类用 数据结构 来组织数据 用来描述这个概念
前面学习的的STL容器,直接将类的数据类型给抽象化了,一个 容器 适用于各种数据类型,不管是内置类型(int,char…),还包括一些自定义类型(例如 自定义的链表节点、树节点…),这些类模板再加上一定的 数据结构的组织 (数据被组织成 数组 、单向链表、双向链表、树形结构…)就变成了所谓 的STL容器 ,容器实际上是对 数据结构组织的数据 的抽象化。但是使用容器得人并不知道容器所使用的数据结构底层实现到底是什么,所以对想要访问(增删查改 、遍历…) 该 数据结构组织下的数据 的人造成了一定的难度,所以这时就诞生了迭代器,以一种标准的对外接口,协助容器外的用户访问数据。

所以 大致可以总结出:容器 = 数据结构 + 迭代器 + 数据 + 实现功能的函数接口
为什么要使用迭代器
看一个示例:对于两种数据结构:数组、链表写一个写一个求平均值的函数
struct listNode //这里链表的默认底层实现
int val;
listNode* next;
;
int average(int* a, int n)
int sum = 0;
for (int i = 0; i < n; i++)
sum += a[i];
return sum;
int average(struct listNode* a)
int sum = 0;
for (struct listNode *i=a; i != NULL ; i=i->next)
sum += i->val;
return sum;
我们发现两种数据结构在遍历的时候 使用了不同的指针 作为载体来遍历数组
从狭义的角度来说这两个指针是完全不同的:一个是数组指针,空间是是连续的,直接++就可以取到下一个元素的地址、另一个是一个链表,必须通过i=i->next来访问下一个元素
但是从广义的角度来说:这两个指针都是遍历数组的一个载体,都扮演着指针的角色,但是自增的方式不同!
泛型编程指的是使用的是同一个函数(average)来处理数组、链表或其他任何其他容器类型。即函数不仅独立于容器中存储数据的类型,而且独立于容器本身的数据结构。模板提供了存储在容器中的数据类型的通用表示,因为还需要遍历容器中的值得通用表示,迭代器正是这样的通用表示。——《 C++ Primer Plus 》
迭代器使用时的注意事项
迭代器的分类

迭代器的分类是对外面的接口函数所接收的迭代器的功能的最低要求,并不是对容器里面迭代器的分类
输入迭代器:可以实现++,解除引用读取
输出迭代器:可以实现++,解除引用写入
正向迭代器:可以实现++,可以引用读取、写入
双向迭代器:可以实现++,可以引用读取、写入,可以实现–
随机访问迭代器:可以实现++,可以引用读取、写入,可以实现–,可以实现各种操作符:[] + += -= -(这时因为存储空间是相邻的)
上面的迭代器的迭代器可以看出是一种包含关系,正向迭代器包含了输入和输出迭代器、双向迭代器包含了单向迭代器、随机访问迭代器包含了双向迭代器
这注意一下:vector、string 底层是由顺序表实现所以迭代器是随机访问迭代器、而list是双向链表 是双向迭代器
迭代器的实现方式分析
- 原生指针类型
这里例如:string 、 vector
stirng的迭代器定义:
typedef char * iterator;
typedef const char* const_iterator;
stirng的迭代器定义:
typedef T* iterator;
typedef const T* const_iteraror;
- 自定义“指针”(用一个类去封装,重载运算符,让他具有和指针一样的功能)
例如:list、map、set
以list为例:
template<class T>
struct DlistNode //数据结构类型:双向链表
DlistNode* next;
DlistNode* prev;
T data;
DlistNode(T x=T() ) // 数据类型的构造函数
:next(nullptr)
,prev(nullptr)
,data(x)
;
template<class T,class Ref,class Ptr>
class list_iterator
typedef DlistNode<T> Node;
typedef list_iterator<T, Ref, Ptr> Self;
public:
list_iterator(Node* x =nullptr)
:p(x)
list_iterator(const Self& l) //指针的拷贝构造函数
p = l.p;
Ref operator*() //下面重载的运算符使得 自定义类型指针 可以像 普通指针一样
return p->data;
Ptr operator->()
return &(p->data);
Self& operator++()
p = p->next;
return *this;
Self operator++(int)
Self temp(p);
p = p->next;
return temp;
Self& operator--()
p = p->prev;
return *this;
Self& operator--(int)
T temp = p->data;
p = p->prev;
return temp;
bool operator!=(const Self& l)
return p != l.p;
bool operator==(const Self& l)
return p == l.p;
private:
Node* p; //顶层指向数据的指针
;
迭代器的左闭右开原则
如果你使用容器的时候一定十分疑惑为什么 迭代器end()-1 才是指向最后一个元素的迭代器,而end() 指向的是最后一个元素的下一个元素
这里就涉及到了迭代器在设计的时候的左闭右开原则。
如果自己手动实现过STL库的人不是很难理解,这样也是挺符合for循环的左闭右开的习惯
例如:
int main()
vector<int> v( 1,2,3,4,5,6 );
vector<int>::iterator it = find(v.begin(), v.end(), 4);
reverse(v.begin(), it);
for (auto e : v)
cout << e << " ";
e++;
这里it是指向4的迭代器,reverse的时候也遵循左闭右开的原则 也就是[1,4),所以是逆置前三个
迭代器失效问题
迭代器失效问题是一个令我十分头疼的问题,因为不同编译器由于检查错误的方法的不同,导致不同环境下同一个代码跑出来的结果大不相同,这里以vs2019、和Linux两个环境为例:
首先什么是迭代器失效?
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<vector>
using namespace std;
int main()
vector<int> v;
v.reserve(5);
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
auto it = find(v.begin(), v.end(), 3);
auto before = v.begin();
v.insert(it, 20);
auto after = v.begin();
*it = 30;
auto is = v.begin();
while (is != v.end())
cout << *is << " ";
is++;
cout << endl;
return 0;
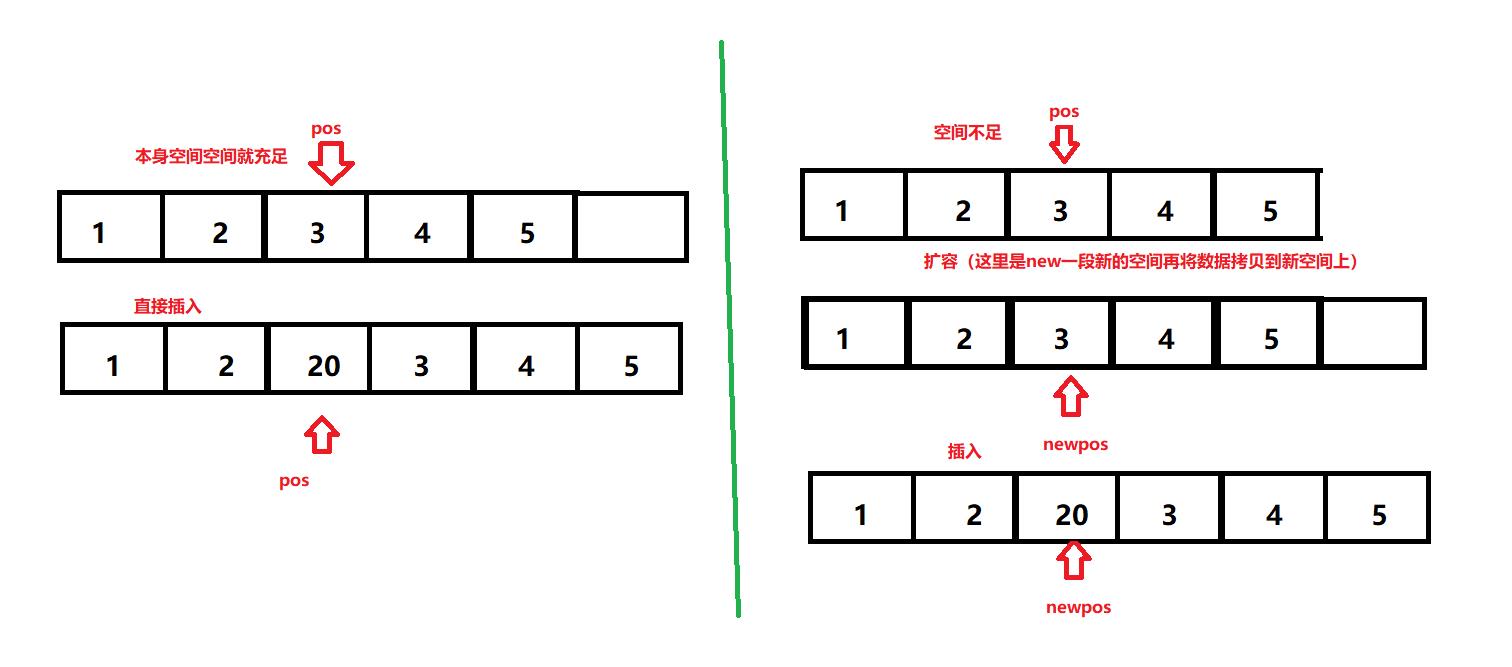
这段代码是在3(it迭代器所指向的位置)的前面插入20,但是问题也同时产生了,插入后的it迭代器指向哪?是否还能用?
这时就要面对两种情况
- 重新增容了,原来的地址空间被释放,pos会变成纯纯的野指针
- 没有增容,但是pos会指向新插入的元素
调试界面:
在insert之前v.begin()的地址

在insert之后v.begin()的地址:

增容之后,这时*it = 30; 时访问野指针,程序会崩溃。
所以这个程序在windows下一定会崩溃!
但是在linux下

居然没有崩溃,有点神奇!
打开gdb调试,结果:

insert前后v.begin()确实发生了改变,但是对于野指针居然还能访问,对于这种现象
那么如果开足空间,不发生增容,会不会也造成迭代器失效?
int main()
vector<int> v;
v.reserve(10);//开出10个空间,确保不会发生增容!
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
auto it = find(v.begin(), v.end(), 3);
auto before = v.begin();
v.insert(it, 20);
auto after = v.begin();
*it = 30;
auto is = v.begin();
while (is != v.end())
cout << *is << " ";
is++;
cout << endl;
return 0;
结果我来说一下:
vs2019:崩溃
linux: 正常编译运行
vs2013:正常编译运行
所以这种迭代器失效会因为环境不同造成不同:
- 重新增容了,原来的地址空间被释放,pos会变成纯纯的野指针 (狭义上的迭代器失效)
- 没有增容,但是pos会指向新插入的元素 ( 广义上的迭代器失效)
我们把上面两种情况统称为迭代器失效,虽然广义上的迭代器失效好像在底层上并没有什么问题。
如何避免迭代器失效?
在面对insert 、erase时,都会造成迭代器失效,这类函数也考虑到这种情况,所以两个函数都提供返回值
insert:返回插入元素位置的迭代器
erase:返回删除元素的下一个元素的迭代器
上面的代码这样写就是正确的:
int main()
vector<int> v;
v.reserve(5);
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
auto it = find(v.begin(), v.end(), 3);
auto before = v.begin();
it=v.insert(it, 20); //将返回值赋值,解决了一切迭代器失效问题
auto after = v.begin();
*it = 30;
auto is = v.begin();
while (is != v.end())
cout << *is << " ";
is++;
cout << endl;
return 0;
以上是关于迭代器的学习心得的主要内容,如果未能解决你的问题,请参考以下文章