目标检测:把标注文件txt格式转换为xml格式
Posted 告白少年
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了目标检测:把标注文件txt格式转换为xml格式相关的知识,希望对你有一定的参考价值。
txt_to_xml程序如下:
# -*- coding: utf-8 -*-
import os,shutil
import cv2
from lxml.etree import Element, SubElement, tostring
def txt_xml(img_path,img_name,txt_path,img_txt,xml_path,img_xml):
#读取txt的信息
clas=[]
img=cv2.imread(os.path.join(img_path,img_name))
imh, imw = img.shape[0:2]
txt_img=os.path.join(txt_path,img_txt)
with open(txt_img,"r") as f:
next(f)
for line in f.readlines():
line = line.strip('\\n')
list = line.split(" ")
# print(list)
clas.append(list)
node_root = Element('annotation')
node_folder = SubElement(node_root, 'folder')
node_folder.text = '1'
node_filename = SubElement(node_root, 'filename')
#图像名称
node_filename.text = img_name
node_size = SubElement(node_root, 'size')
node_width = SubElement(node_size, 'width')
node_width.text = str(imw)
node_height = SubElement(node_size, 'height')
node_height.text = str(imh)
node_depth = SubElement(node_size, 'depth')
node_depth.text = '3'
for i in range(len(clas)):
node_object = SubElement(node_root, 'object')
node_name = SubElement(node_object, 'name')
node_name.text = str(clas[i][0])
node_pose=SubElement(node_object, 'pose')
node_pose.text="Unspecified"
node_truncated=SubElement(node_object, 'truncated')
node_truncated.text="truncated"
node_difficult = SubElement(node_object, 'difficult')
node_difficult.text = '0'
node_bndbox = SubElement(node_object, 'bndbox')
node_xmin = SubElement(node_bndbox, 'xmin')
node_xmin.text = str(clas[i][1])
node_ymin = SubElement(node_bndbox, 'ymin')
node_ymin.text = str(clas[i][2])
node_xmax = SubElement(node_bndbox, 'xmax')
node_xmax.text = str(int(clas[i][1])+int(clas[i][3]))
node_ymax = SubElement(node_bndbox, 'ymax')
node_ymax.text = str(int(clas[i][2])+int(clas[i][4]))
xml = tostring(node_root, pretty_print=True) # 格式化显示,该换行的换行
img_newxml = os.path.join(xml_path, img_xml)
file_object = open(img_newxml, 'wb')
file_object.write(xml)
file_object.close()
if __name__ == "__main__":
#图像文件夹所在位置
img_path = r"C:\\Users\\An\\Desktop\\Exclusively-Dark-Image-Dataset-master\\Groundtruth\\img\\test"
#标注文件夹所在位置
txt_path=r"C:\\Users\\An\\Desktop\\Exclusively-Dark-Image-Dataset-master\\Groundtruth\\ann\\test"
#txt转化成xml格式后存放的文件夹
xml_path=r"C:\\Users\\An\\Desktop\\Exclusively-Dark-Image-Dataset-master\\xml"
for img_name in os.listdir(img_path):
print(img_name)
img_xml=img_name.split(".")[0]+".xml"
img_txt=img_name+".txt"
txt_xml(img_path, img_name, txt_path, img_txt,xml_path, img_xml)
1.图像和标注文件对应关系:
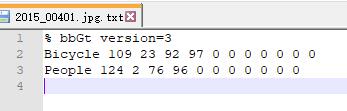
2.标注文件的格式如下:
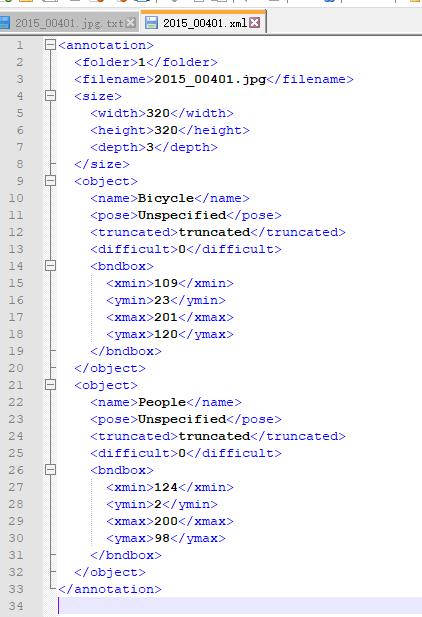
3.生成的xml文件格式如下:
4.图像用labelImg打开的结果:

以上是关于目标检测:把标注文件txt格式转换为xml格式的主要内容,如果未能解决你的问题,请参考以下文章
[数据集][VOC][目标检测]输电线异物数据集目标检测可用yolo训练-4165张介绍
[数据集][VOC][目标检测]河道垃圾水面漂浮物数据集目标检测可用yolo训练-1304张介绍
[数据集][VOC][目标检测]翻越栏杆翻越防护栏数据集目标检测可用yolo训练-1035张介绍